
3000帧动画图解MySQL为什么需要binlog、redo log和undo log
全文建立在MySQL的存储引擎为InnoDB的基础上
Hollis的新书限时折扣中,一本深入讲解Java基础的干货笔记!
先看一条SQL如何入库的:
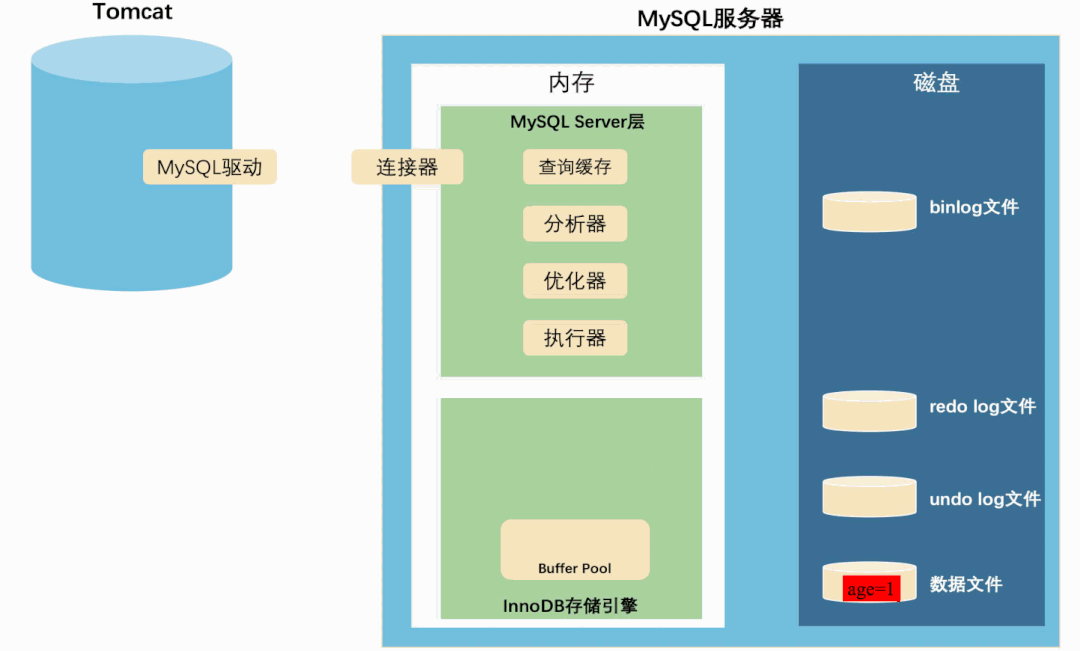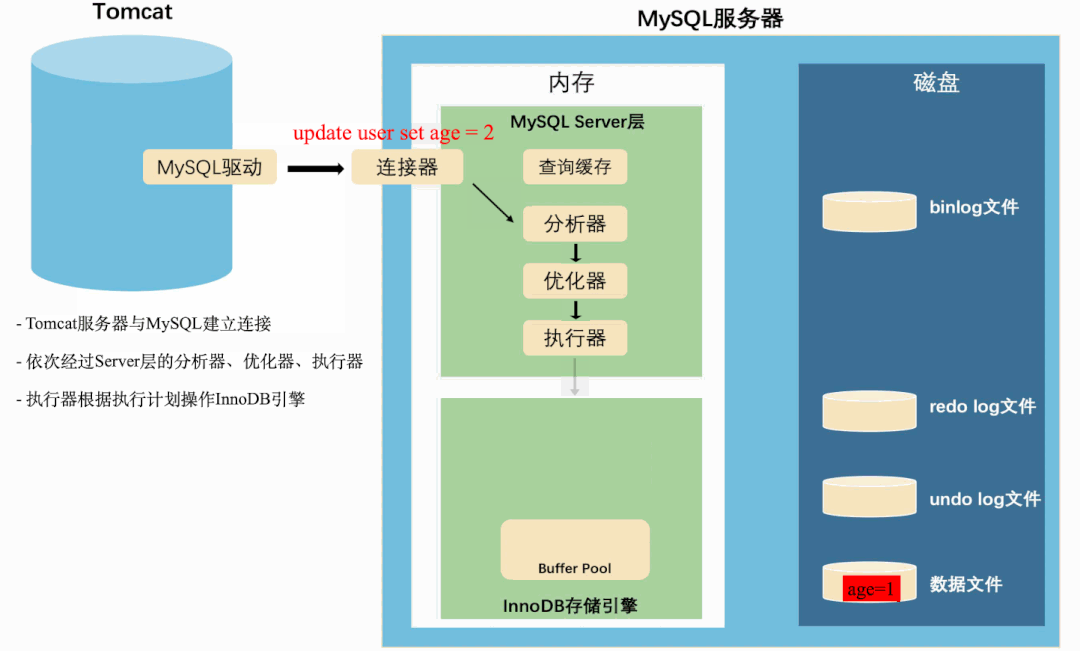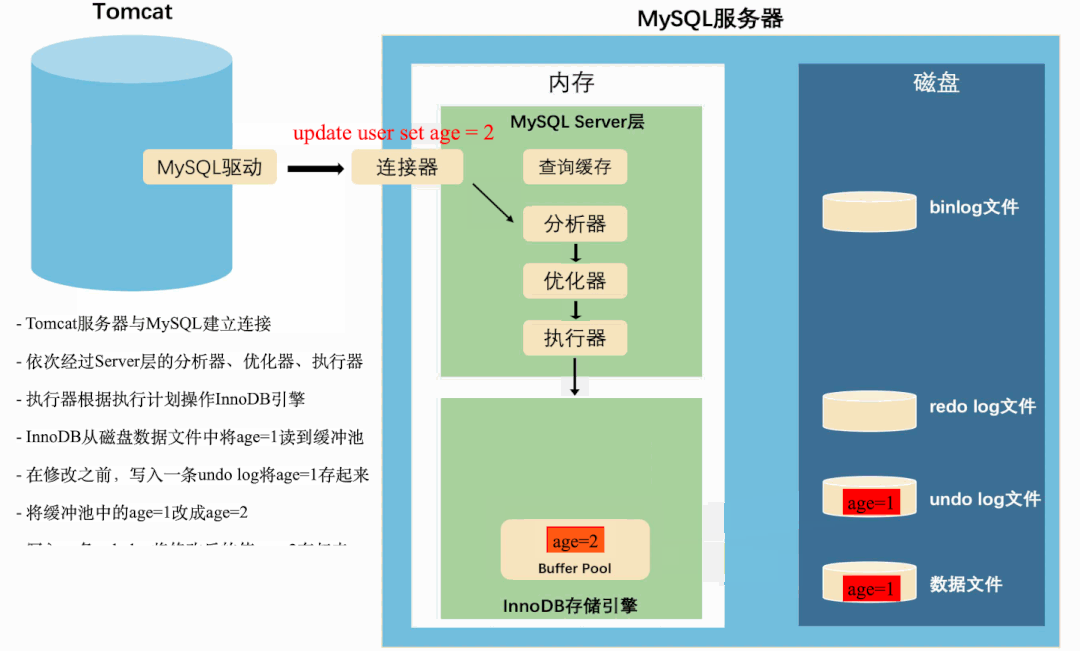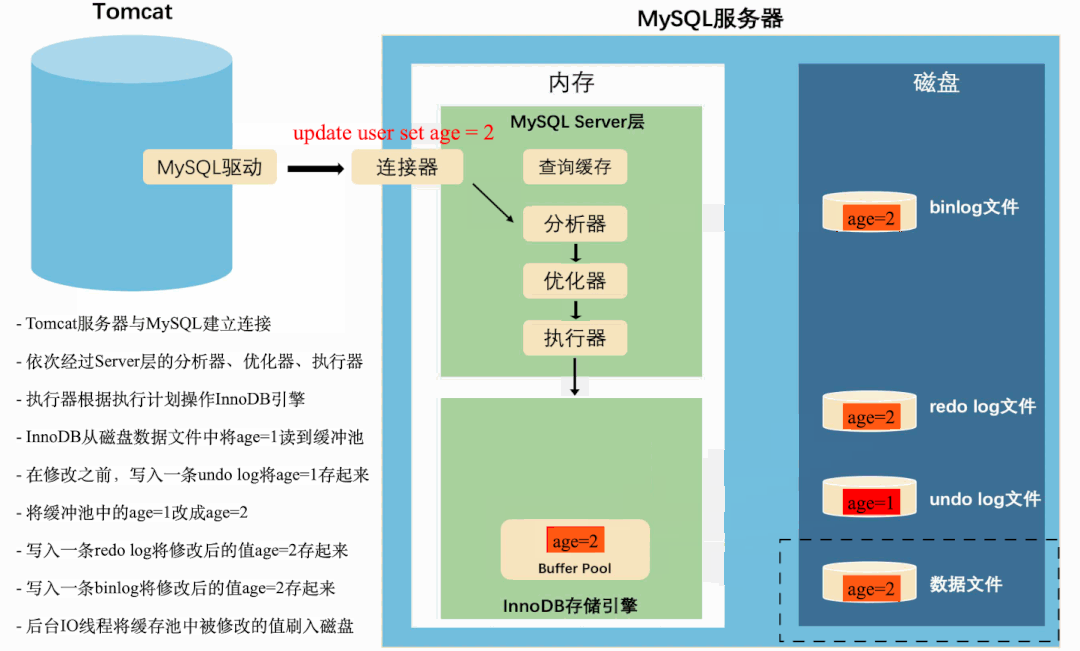
这是一条很简单的更新SQL,从MySQL服务端接收到SQL到落盘,先后经过了MySQL Server层和InnoDB存储引擎。
Server层就像一个产品经理,分析客户的需求,并给出实现需求的方案。
InnoDB就像一个基层程序员,实现产品经理给出的具体方案。
在MySQL”分析需求,实现方案“的过程中,还夹杂着内存操作和磁盘操作,以及记录各种日志。
他们到底有什么用处?他们之间到底怎么配合的?MySQL又为什么要分层呢?InnoDB里面的那一块Buffer Pool又是什么?
我们慢慢分析。
分层结构
MySQL为什么要分为Server层和存储引擎两层呢?
这个问题官方也没有给出明确的答案,但是也不难猜,简单来说就是为了“解耦”。
Server层和存储引擎各司其职,分工明确,用户可以根据不同的需求去使用合适的存储引擎,多好的设计,对不对?
后来的发展也验证了“分层设计”的优越性:
MySQL最初搭载的存储引擎是自研的只支持简单查询的MyISAM的前身ISAM,后来与Sleepycat合作研发了Berkeley DB引擎,支持了事务。
江山代有才人出,技术后浪推前浪,MySQL在持续的升级着自己的存储引擎的过程中,遇到了横空出世的InnoDB,InnoDB的功能强大让MySQL倍感压力。
自己的存储引擎打不过InnoDB怎么办?
打不过就加入!

MySQL选择了和InnoDB合作。正是因为MySQL存储引擎的插件化设计,两个公司合作的非常顺利,MySQL也在合作后不久就发布了正式支持nnoDB的4.0版本以及经典的4.1版本。
MySQL兼并天下模式也成为MySQL走向繁荣的一个重要因素。这能让MySQL长久地保持着极强竞争力。
时至今日,MySQL依然占据着极高数据库市场份额,仅次于王牌数据库Oracle。
Buffer Pool
在InnoDB里,有一块非常重要的结构——Buffer Pool。

Buffer Pool是个什么东西呢?
Buffer Pool就是一块用于缓存MySQL磁盘数据的内存空间。
为什么要缓存MySQL磁盘数据呢?
我们通过一个例子说明,我们先假设没有Buffer Pool,user表里面只有一条记录,记录的age = 1,假设需要执行三条SQL:
事务A:update user set age = 2 事务B:update user set age = 3 事务C:update user set age = 4
如果没有Buffer Pool,那执行就是这样的:
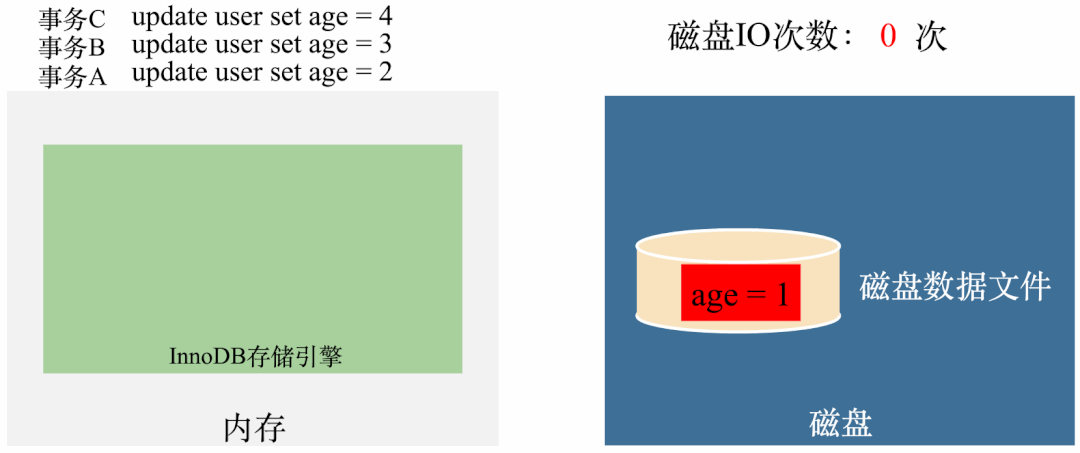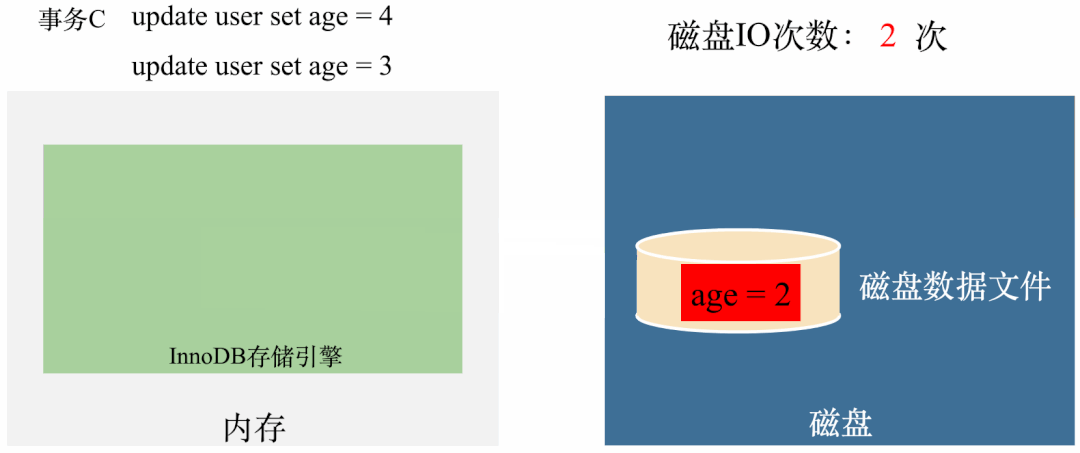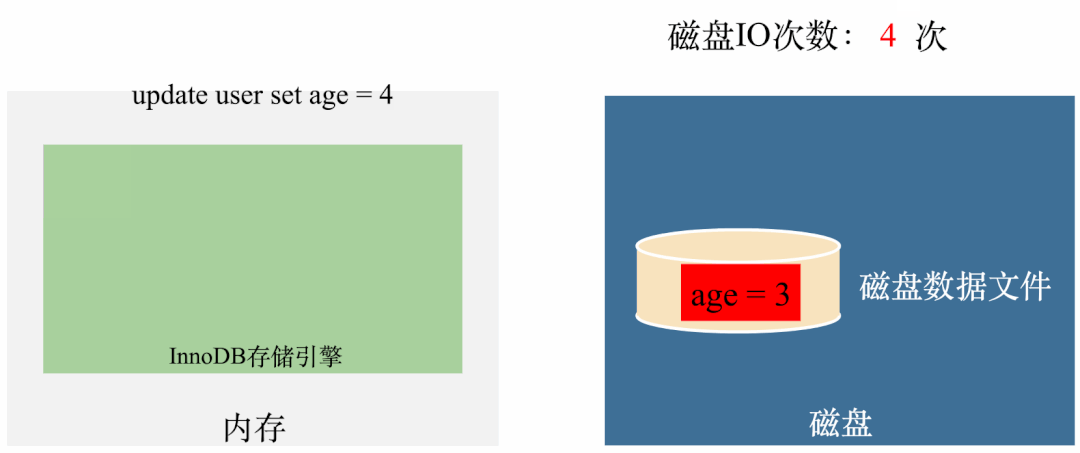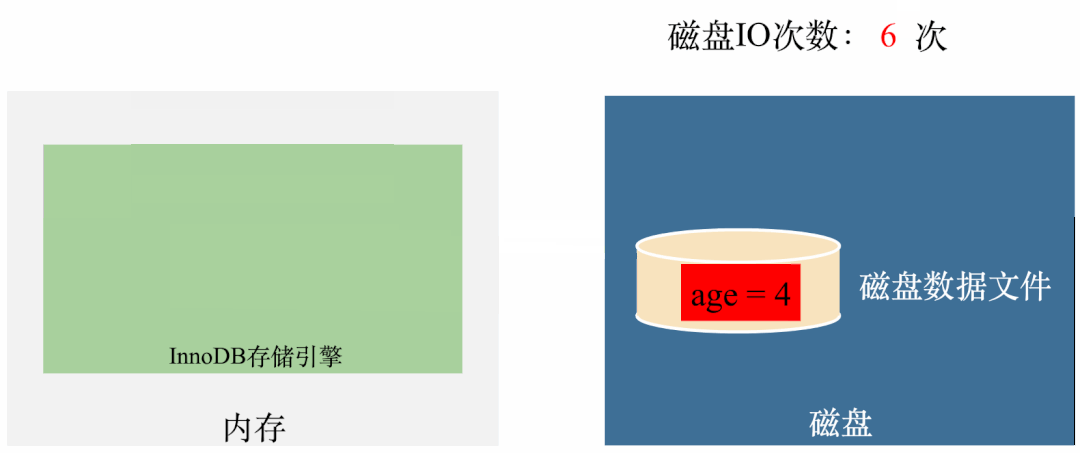
从图上可以看出,每次更新都需要从磁盘拿数据(1次IO),修改完了需要刷到磁盘(1次IO),也就是每次更新都需要2次磁盘IO。三次更新需要6次磁盘IO。
而有了Buffer Pool,执行就成了这样:
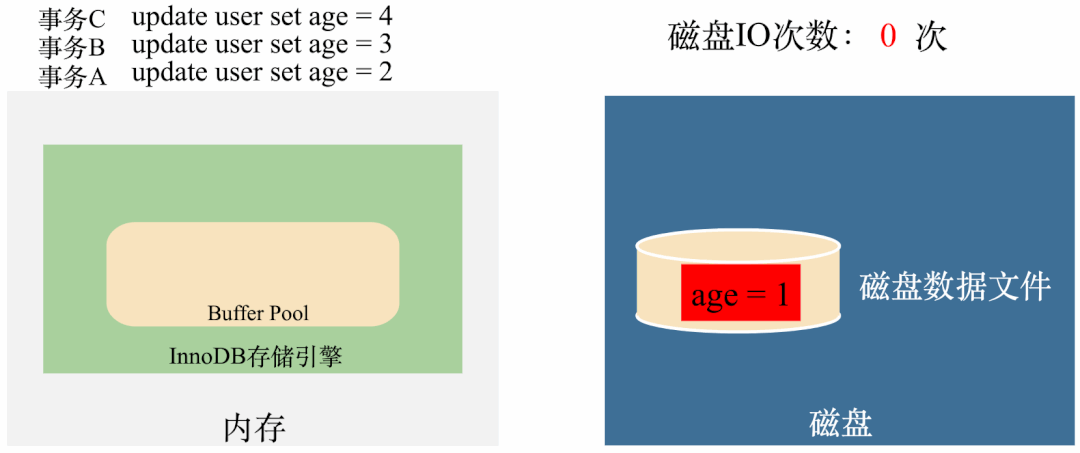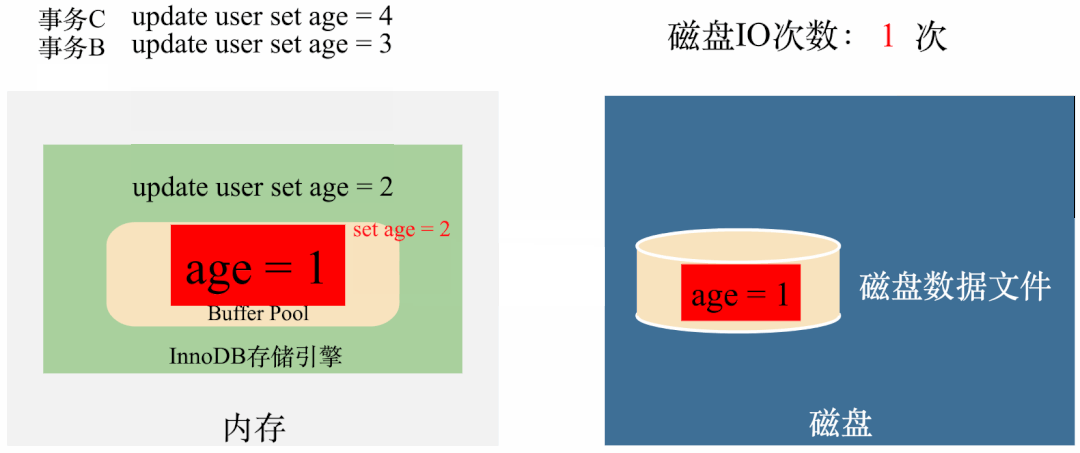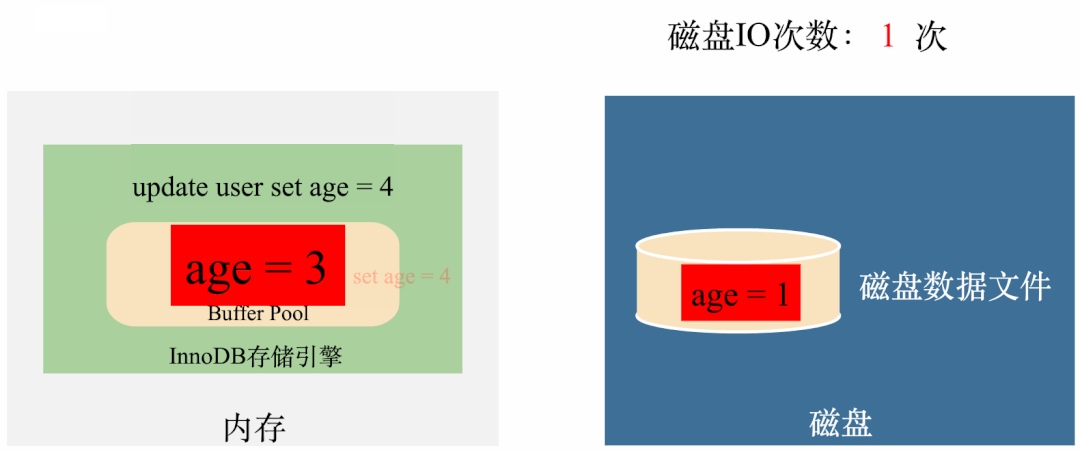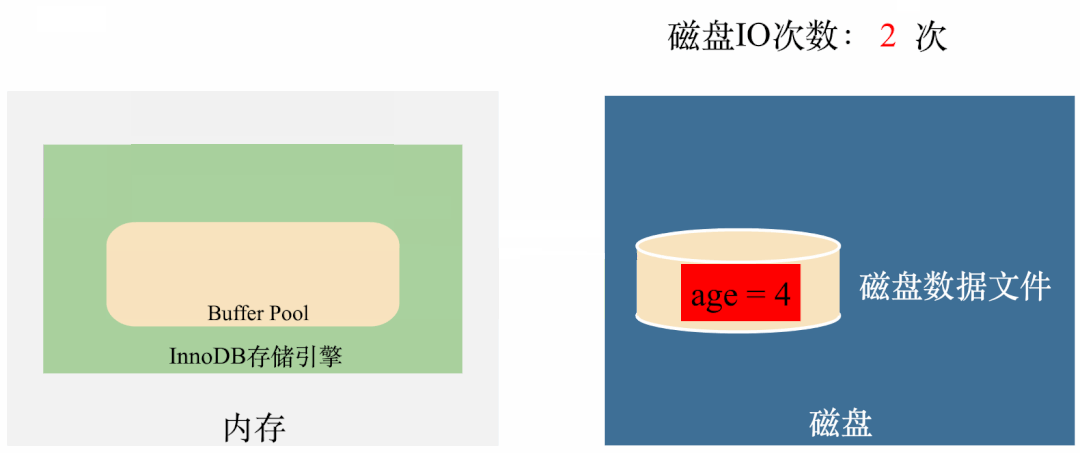
从图上可以看出,只需要在第一次执行的时候将数据从磁盘拿到Buffer Pool(1次IO),第三次执行完将数据刷回磁盘(1次IO),整个过程只需要2次磁盘IO,比没有Buffer Pool节省了4次磁盘IO的时间。
当然,Buffer Pool真正的运转流程没有这么简单,具体实现细节和优化技巧还有很多,由于篇幅有限,本文不做详细描述。
我想表达的是:Buffer Pool就是将磁盘IO转换成了内存操作,节省了时间,提高了效率。
Buffer Pool是提高了效率没错,但是出现了一个问题,Buffer Pool是基于内存的,而只要一断电,内存里面的数据就会全部丢失。
如果断电的时候Buffer Pool的数据还没来得及刷到磁盘,那么这些数据不就丢失了吗?
还是上面的那个例子,如果三个事务执行完毕,在age = 4还没有刷到磁盘的时候,突然断电,数据就全部丢掉了:
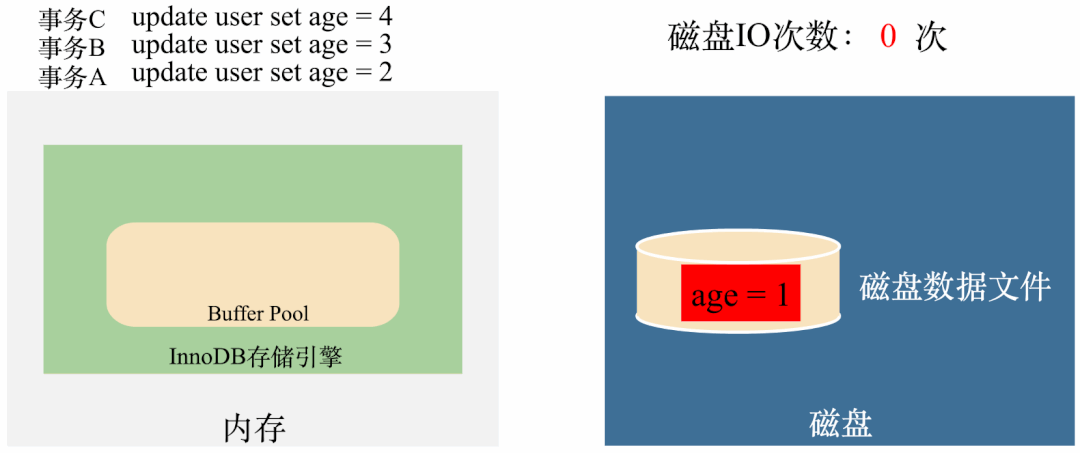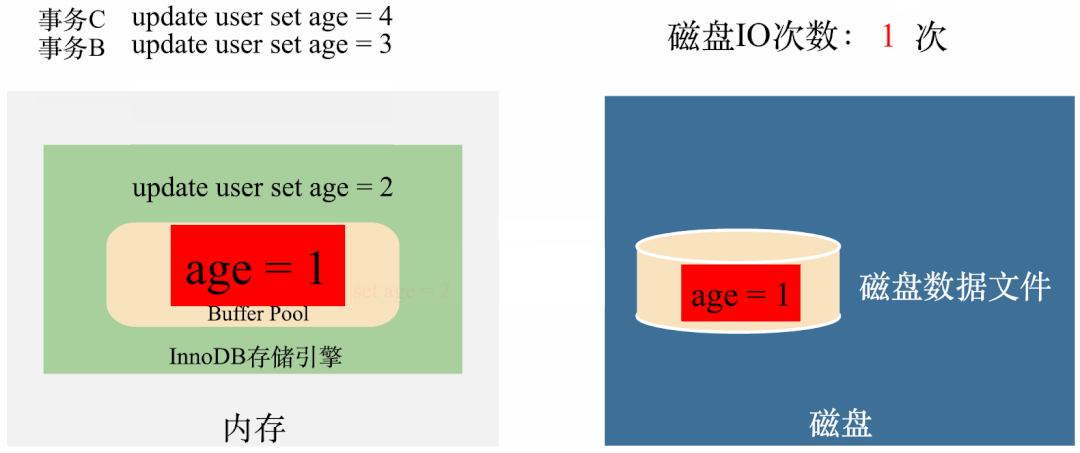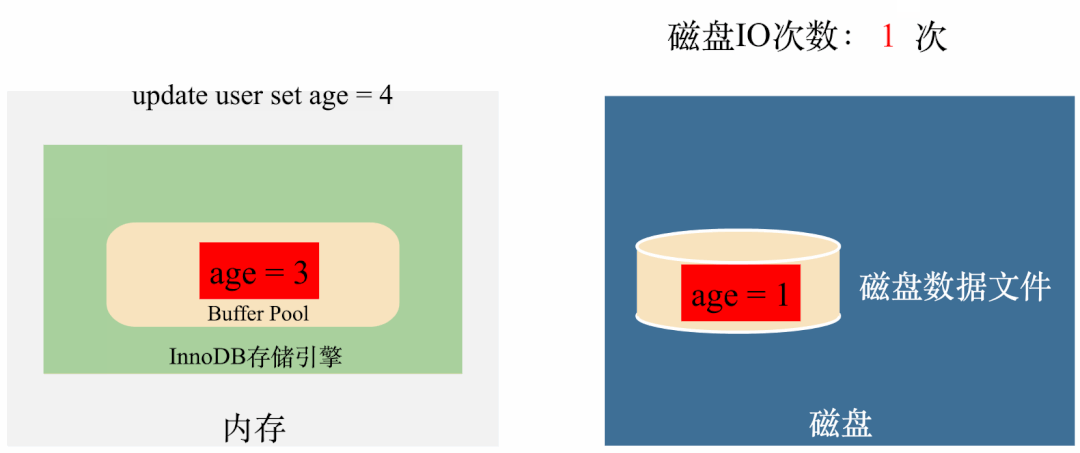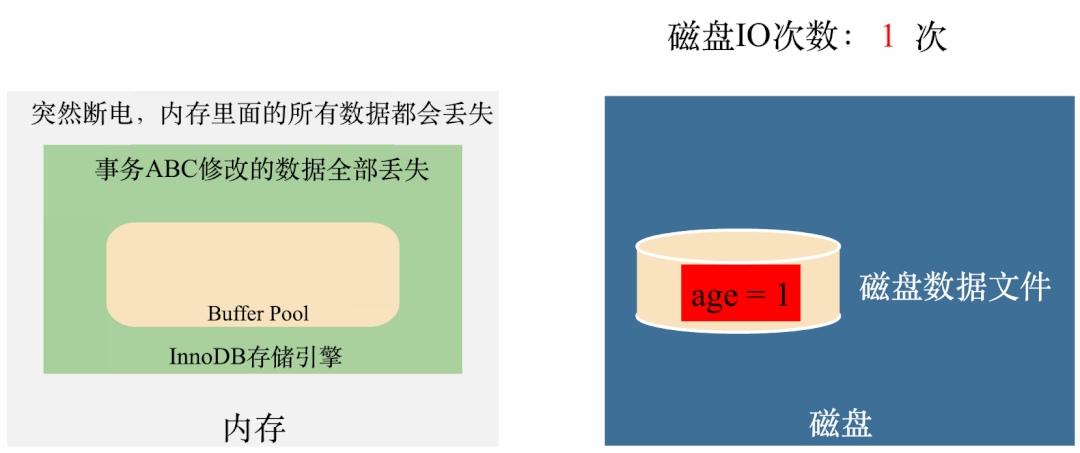
试想一下,如果这些丢失的数据是核心的用户交易数据,那用户能接受吗?
答案是否定的。
那InnoDB是如何做到数据不会丢失的呢?
今天的第一个日志——redo log登场了。
恢复 - redo log
顾名思义,redo是重做的意思,redo log就是重做日志的意思。
redo log是如何保证数据不会丢失的呢?
就是在修改之后,先将修改后的值记录到磁盘上的redo log中,就算突然断电了,Buffer Pool中的数据全部丢失了,来电的时候也可以根据redo log恢复Buffer Pool,这样既利用到了Buffer Pool的内存高效性,也保证了数据不会丢失。
我们通过一个例子说明,我们先假设没有Buffer Pool,user表里面只有一条记录,记录的age = 1,假设需要执行一条SQL:
事务A:update user set age = 2
执行过程如下:
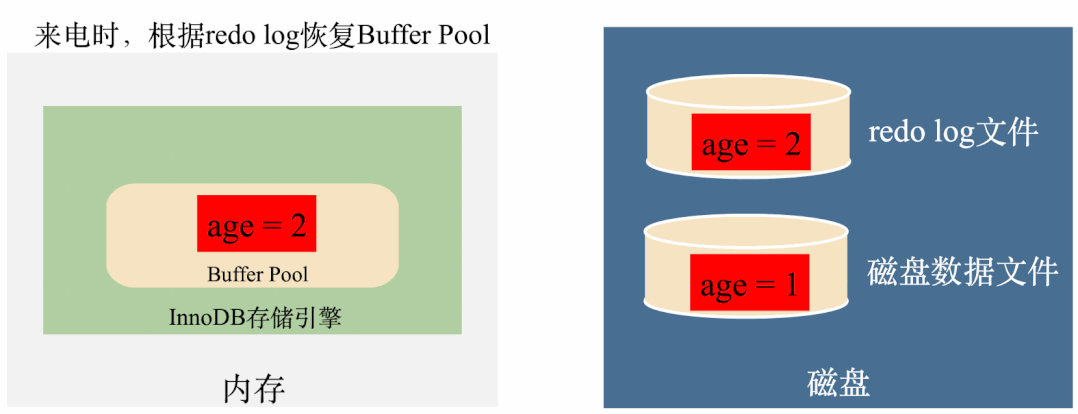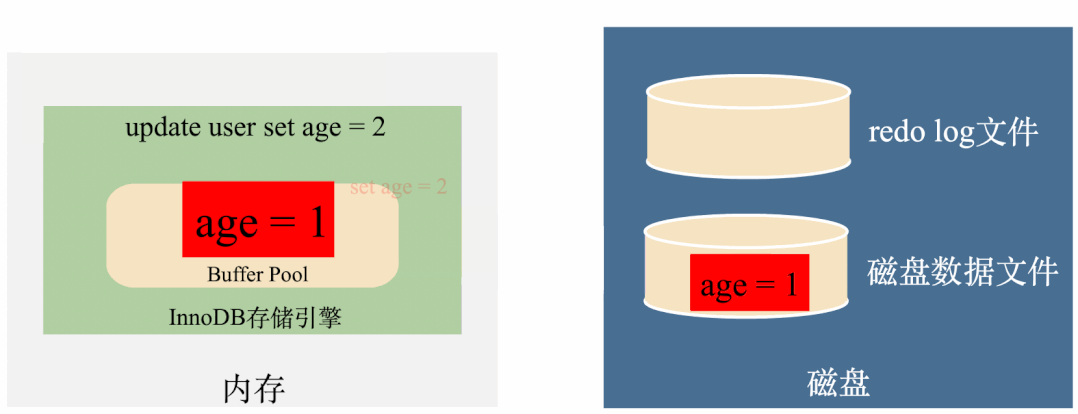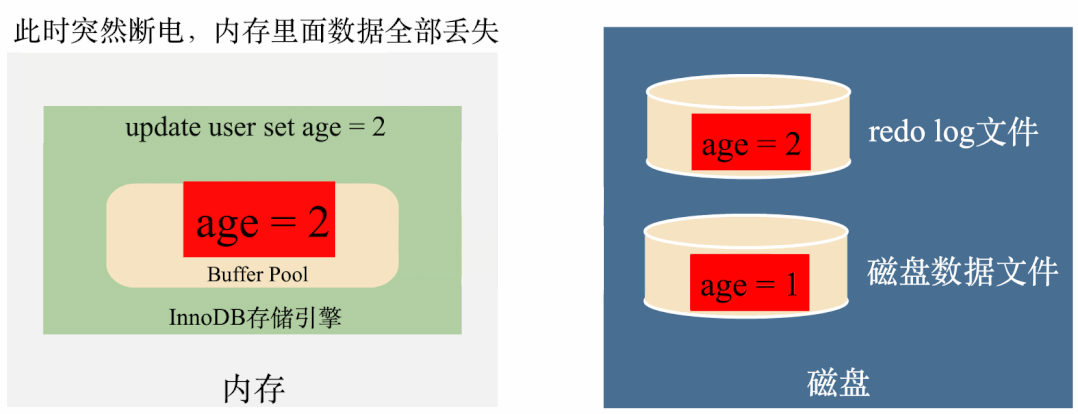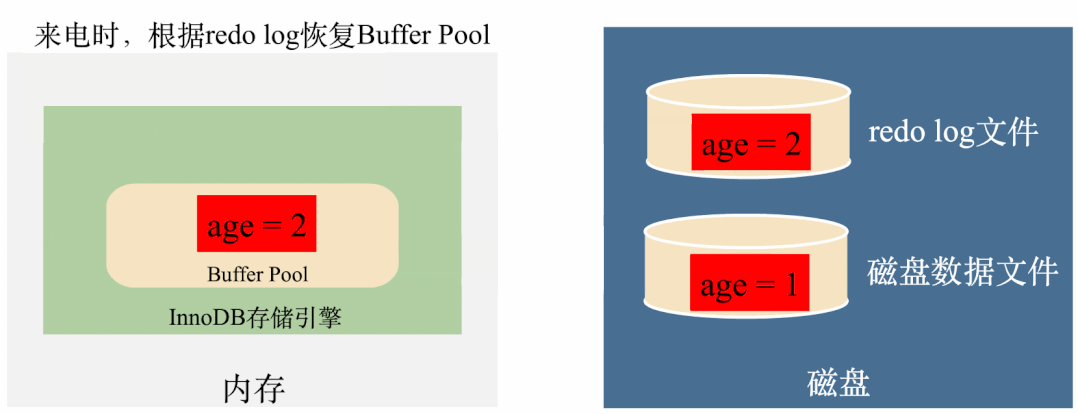
如上图,有了redo log之后,将age修改成2之后,马上将age = 2写到redo log里面,如果这个时候突然断电内存数据丢失,在来电的时候,可以将redo log里面的数据读出来恢复数据,用这样的方式保证了数据不会丢失。
你可能会问,redo log文件也在磁盘上,数据文件也在磁盘上,都是磁盘操作,何必多此一举?为什么不直接将修改的数据写到数据文件里面去呢?

傻瓜,因为redo log是磁盘顺序写,数据刷盘是磁盘随机写,磁盘的顺序写比随机写高效的多啊。
这种先预写日志后面再将数据刷盘的机制,有一个高大上的专业名词——WAL(Write-ahead logging),翻译成中文就是预写式日志。
虽然磁盘顺序写已经很高效了,但是和内存操作还是有一定的差距。
那么,有没有办法进一步优化一下呢?
答案是可以。那就是给redo log也加一个内存buffer,也就是redo log buffer,用这种套娃式的方法进一步提高效率。
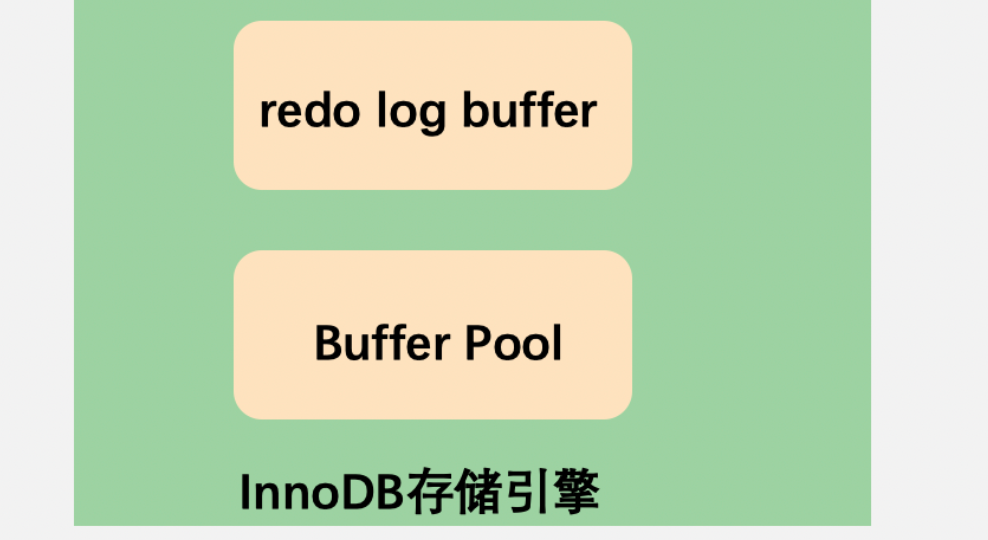
redo log buffer具体是怎么配合刷盘呢?
在回答这个问题之前之前,我们先来捋一下MySQL服务端和操作系统的关系:
MySQL服务端是一个进程,它运行于操作系统之上。也就是说,操作系统挂了MySQL一定挂了,但是MySQL挂了操作系统不一定挂。
所以MySQL挂了有两种情况:
MySQL挂了,操作系统也挂了,也就是常说的服务器宕机了。这种情况Buffer Pool里面的数据会全部丢失,操作系统的os cache里面的数据也会丢失。 MySQL挂了,操作系统没有挂。这种情况Buffer Pool里面的数据会全部丢失,操作系统的os cache里面的数据不会丢失。
OK,了解了MySQL服务端和操作系统的关系之后,再来看redo log的落盘机制。redo log的刷盘机制由参数innodb_flush_log_at_trx_commit控制,这个参数有3个值可以设置:
innodb_flush_log_at_trx_commit = 1:实时写,实时刷 innodb_flush_log_at_trx_commit = 0:延迟写,延迟刷 innodb_flush_log_at_trx_commit = 2:实时写,延迟刷
写可以理解成写到操作系统的缓存(os cache),刷可以理解成把操作系统里面的缓存刷到磁盘。
这三种策略的区别,我们分开讨论:
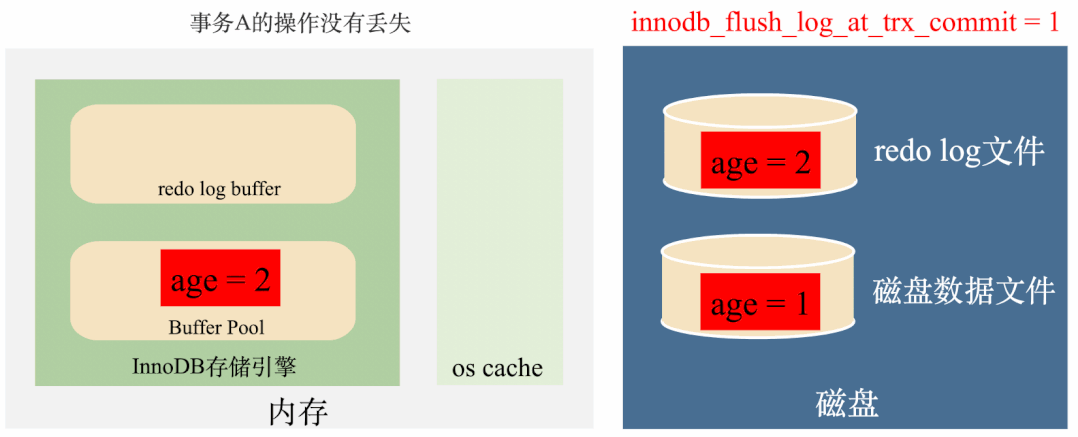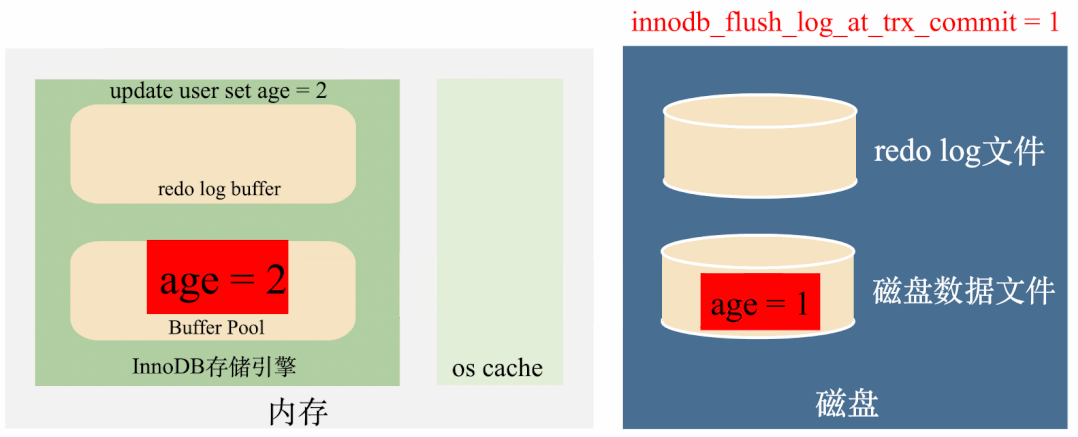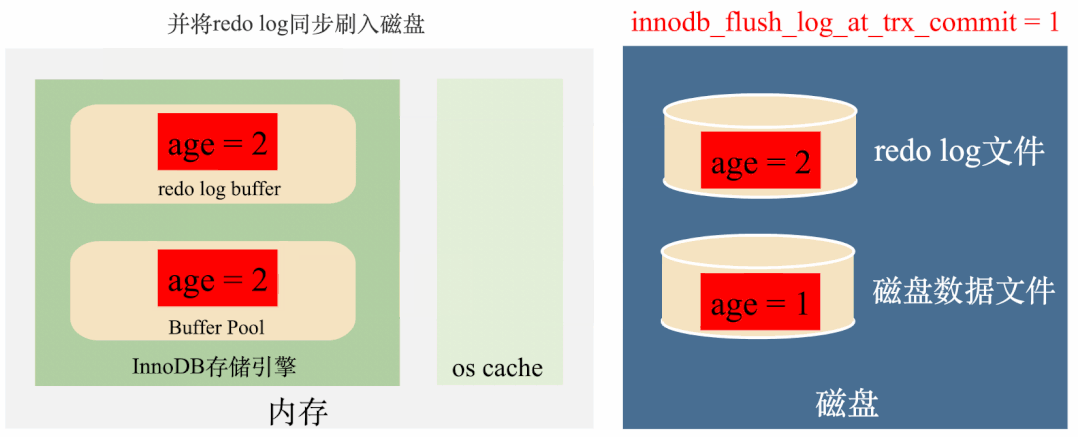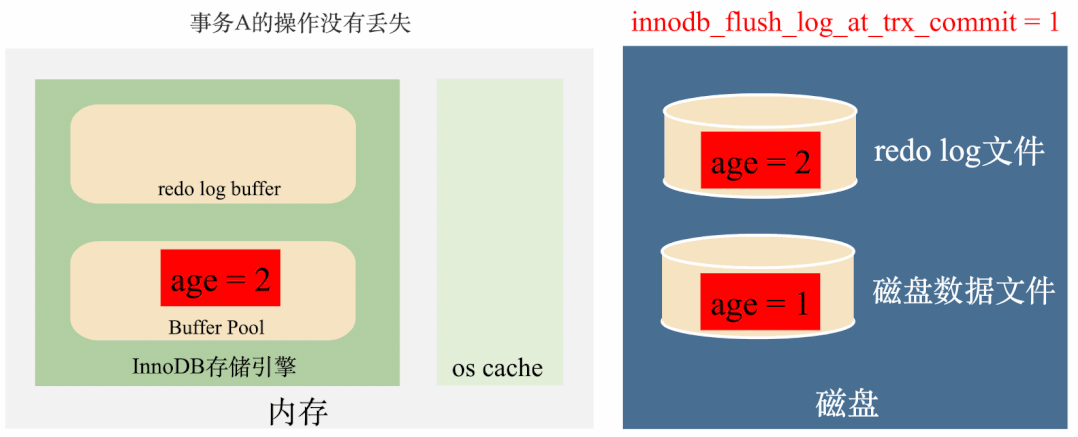
innodb_flush_log_at_trx_commit = 1:实时写,实时刷
这种策略会在每次事务提交之前,每次都会将数据从redo log刷到磁盘中去,理论上只要磁盘不出问题,数据就不会丢失。
总结来说,这种策略效率最低,但是丢数据风险也最低。
innodb_flush_log_at_trx_commit = 0:延迟写,延迟刷
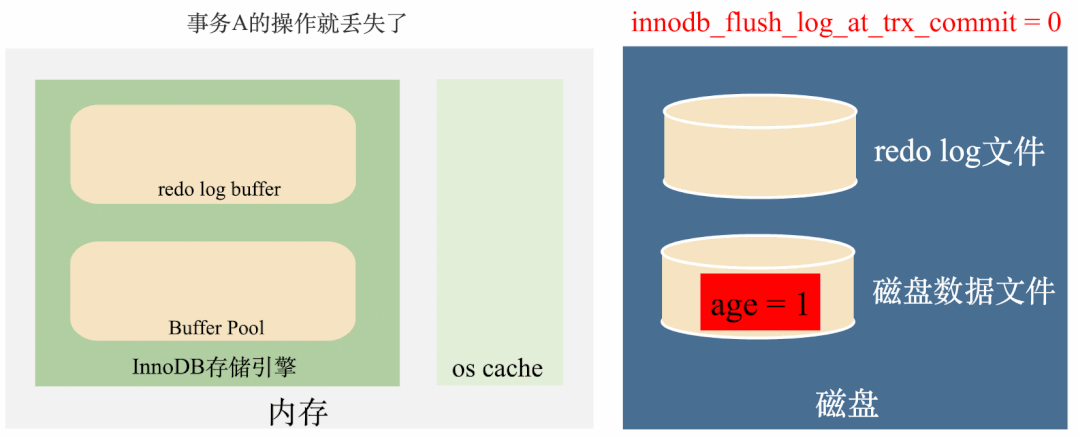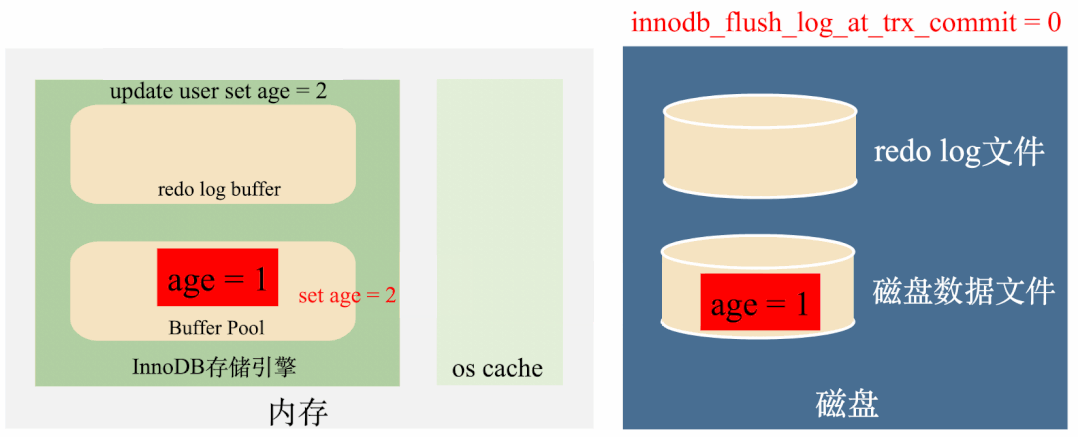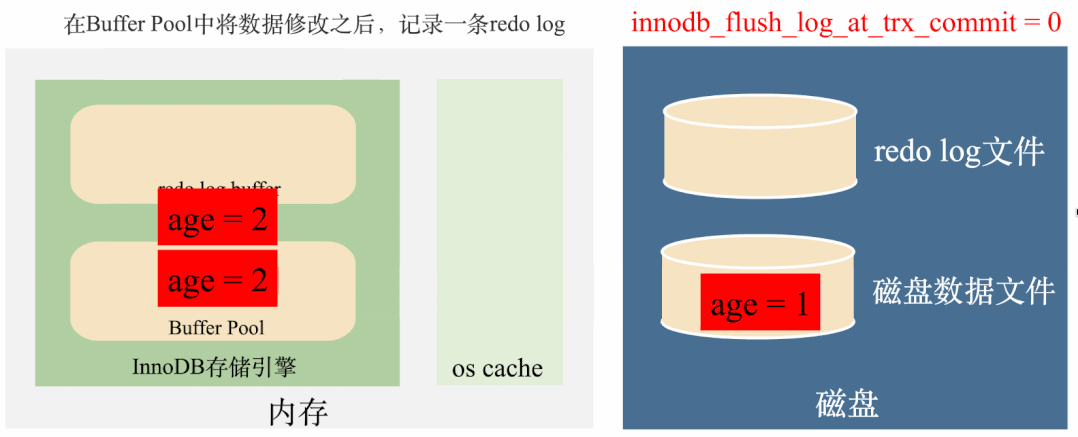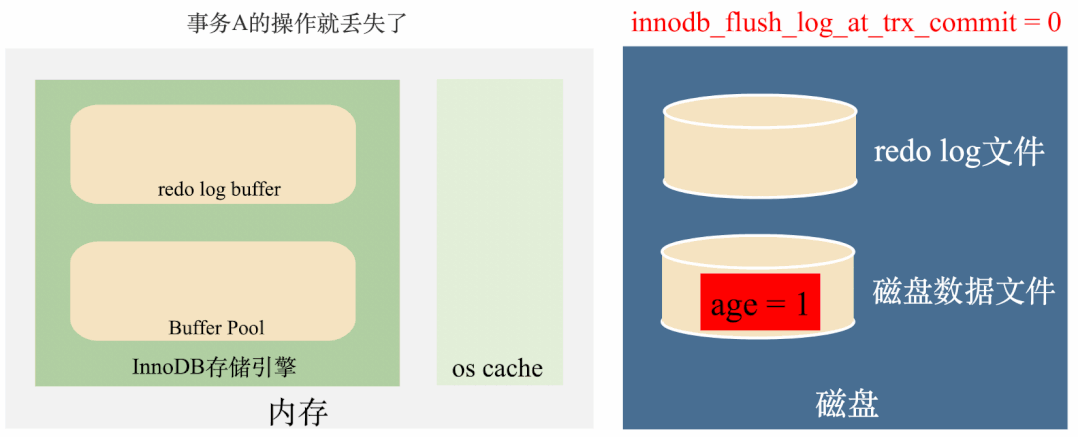
这种策略在事务提交时,只会把数据写到redo log buffer中,然后让后台线程定时去将redo log buffer里面的数据刷到磁盘。
这种策略是最高效的,但是我们都知道,定时任务是有间隙的,但是如果事务提交后,后台线程没来得及将redo log刷到磁盘,这个时候不管是MySQL进程挂了还是操作系统挂了,这一部分数据都会丢失。
总结来说这种策略效率最高,丢数据的风险也最高。
innodb_flush_log_at_trx_commit = 2:实时写,延迟刷
这种策略在事务提交之前会把redo log写到os cache中,但并不会实时地将redo log刷到磁盘,而是会每秒执行一次刷新磁盘操作。
这种情况下如果MySQL进程挂了,操作系统没挂的话,操作系统还是会将os cache刷到磁盘,数据不会丢失,如下图:
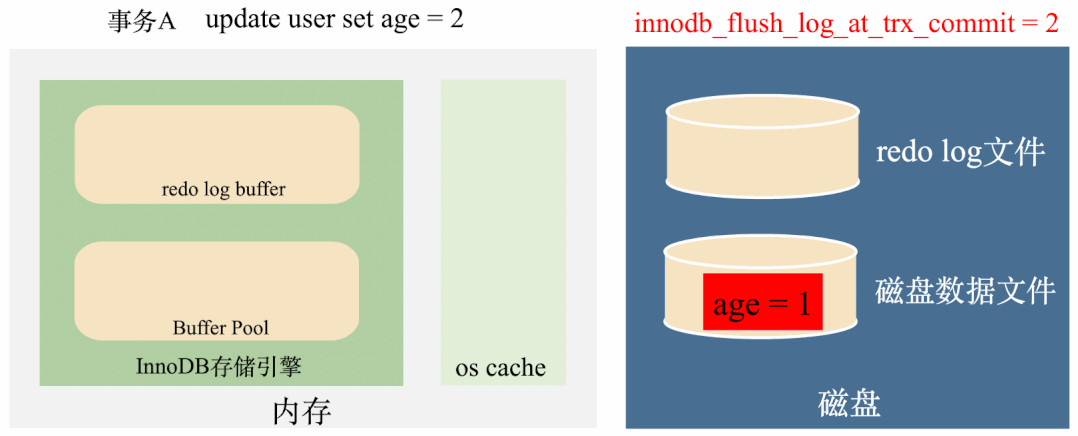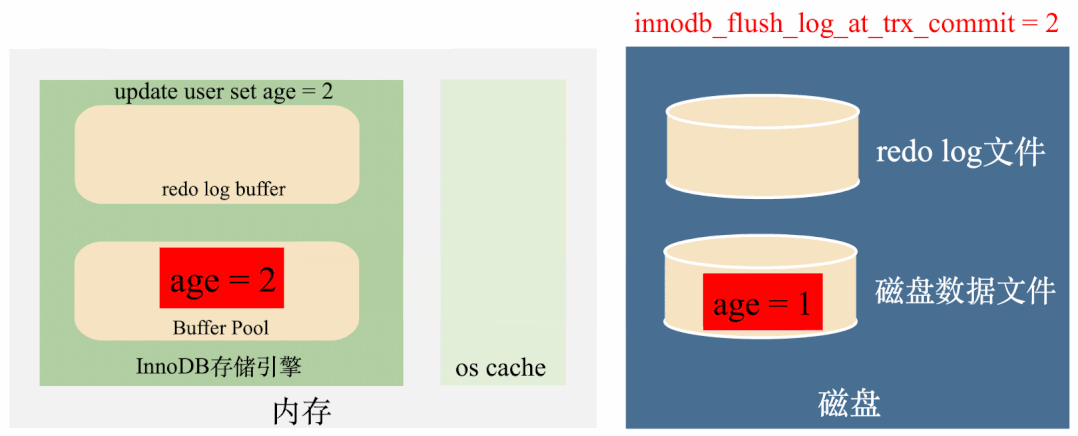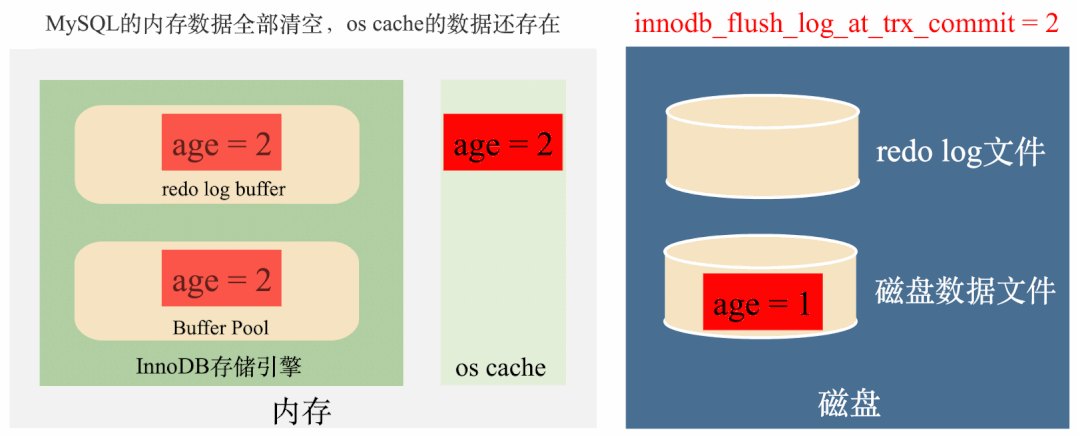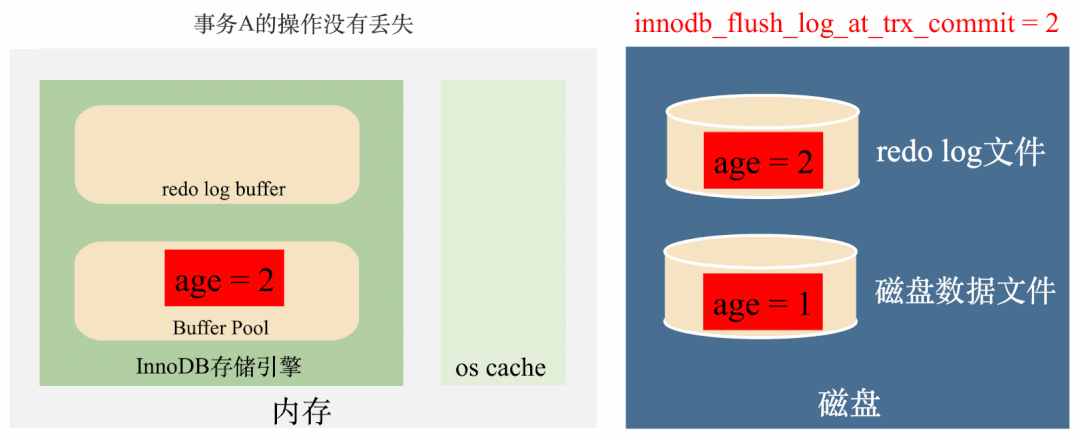
但如果MySQL所在的服务器挂掉了,也就是操作系统都挂了,那么os cache也会被清空,数据还是会丢失。如下图:
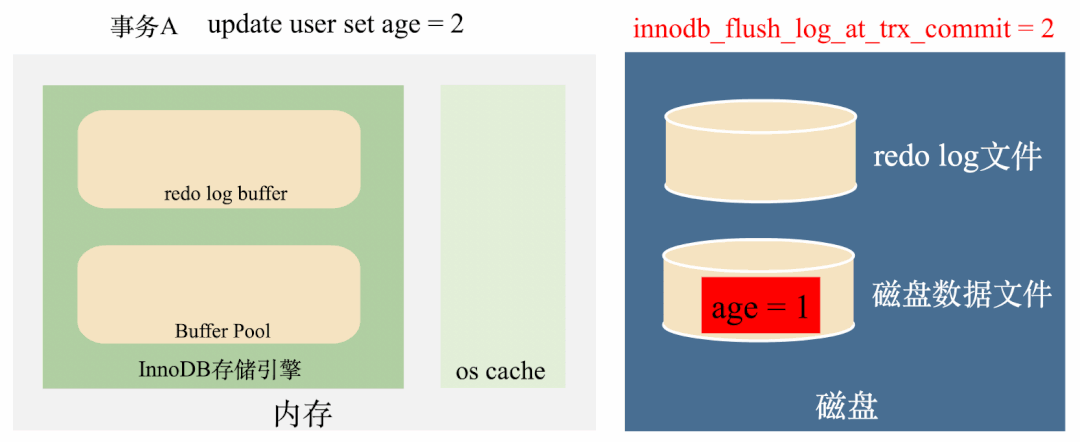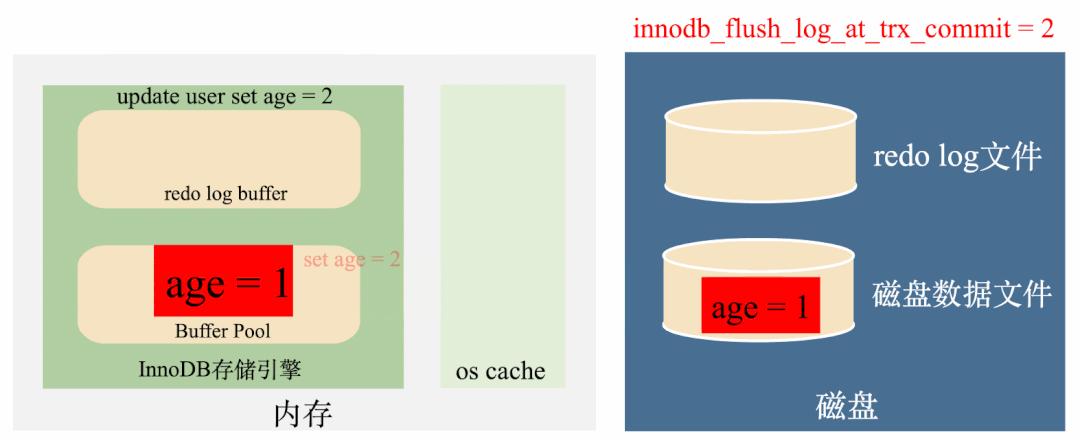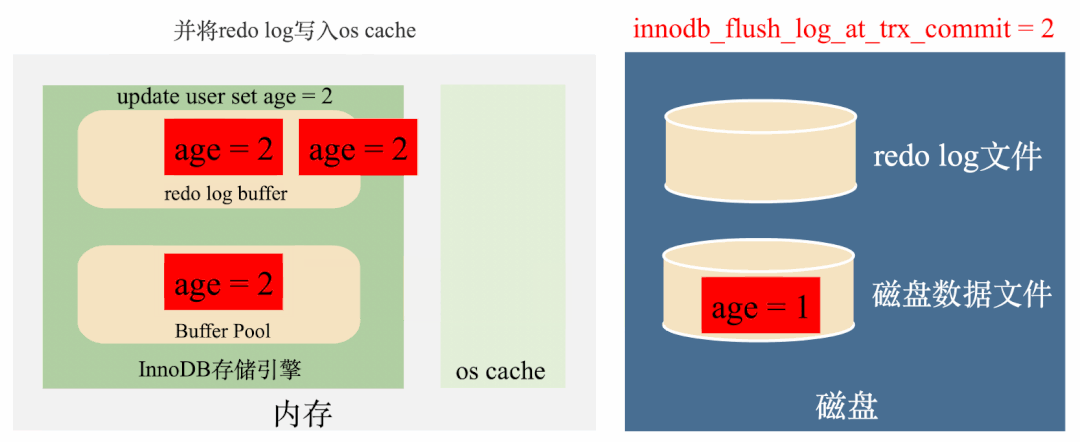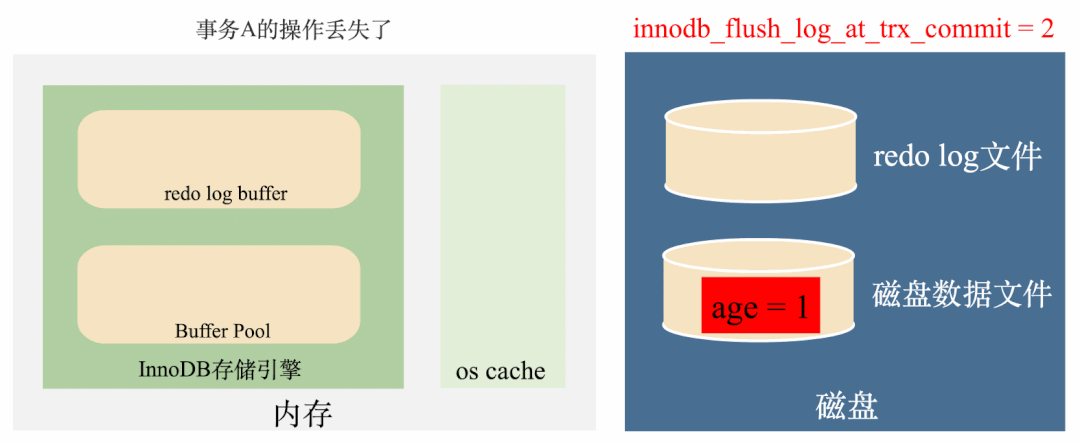
所以,这种redo log刷盘策略是上面两种策略的折中策略,效率比较高,丢失数据的风险比较低,绝大多情况下都推荐这种策略。
总结一下,redo log的作用是用于恢复数据,写redo log的过程是磁盘顺序写,有三种刷盘策略,有innodb_flush_log_at_trx_commit 参数控制,推荐设置成2。
回滚 - undo log
我们都知道,InnoDB是支持事务的,而事务是可以回滚的。
假如一个事务将age=1修改成了age=2,在事务还没有提交的时候,后台线程已经将age=2刷入了磁盘。这个时候,不管是内存还是磁盘上,age都变成了2,如果事务要回滚,找不到修改之前的age=1,无法回滚了。
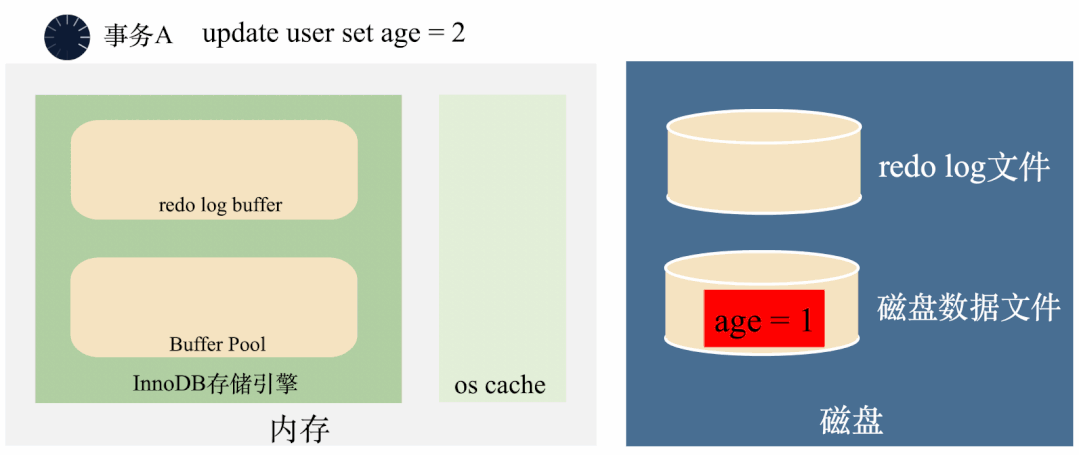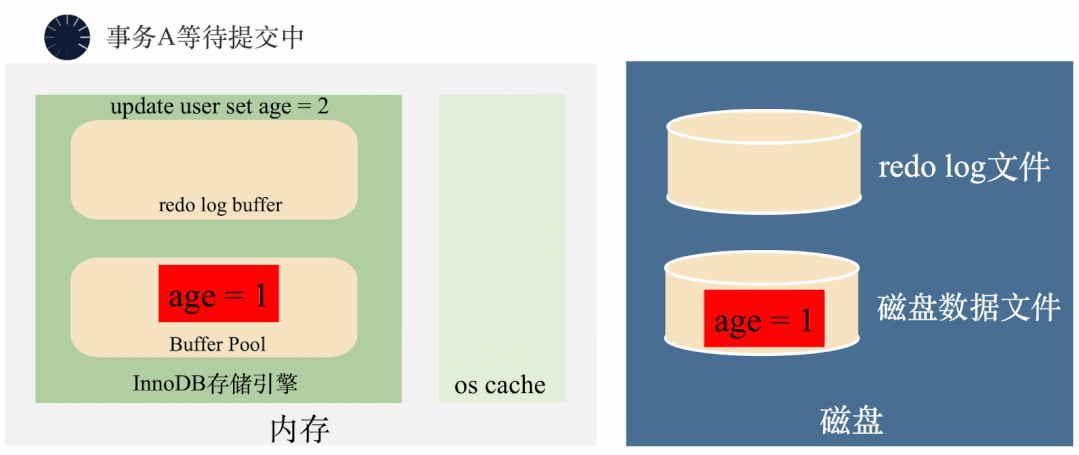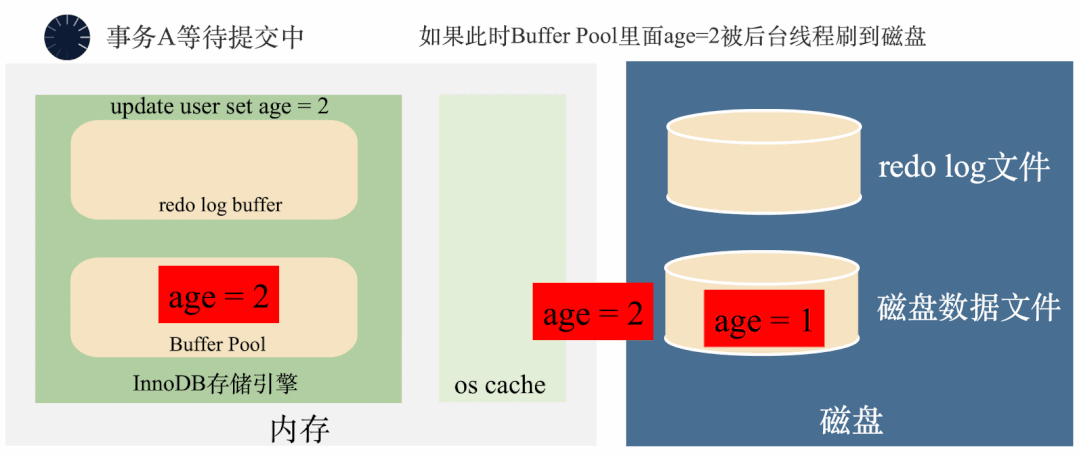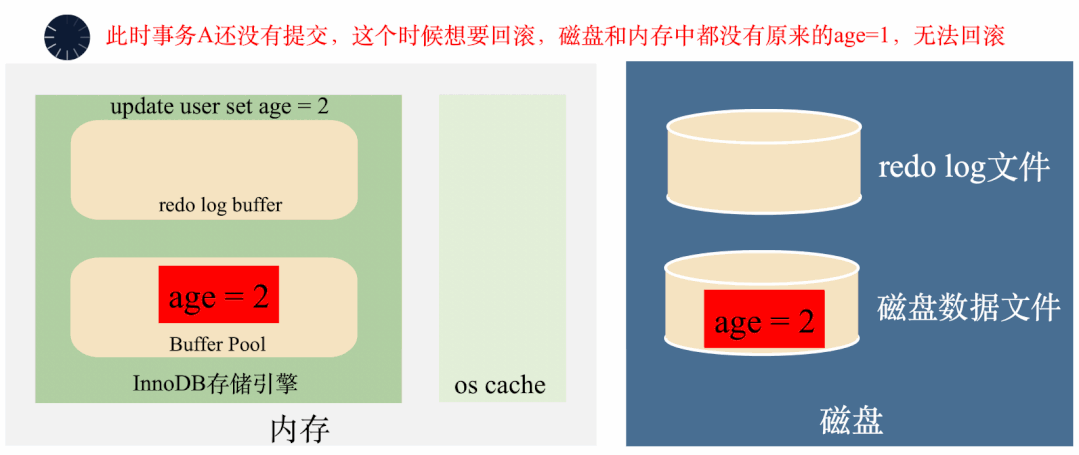
那怎么办呢?
很简单,把修改之前的age=1存起来,回滚的时候根据存起来的age=1回滚就行了。
MySQL确实是这么干的!这个记录修改之前的数据的过程,叫做记录undo log。undo翻译成中文是撤销、回滚的意思,undo log的主要作用也就是回滚数据。
如何回滚呢?看下面这个图:
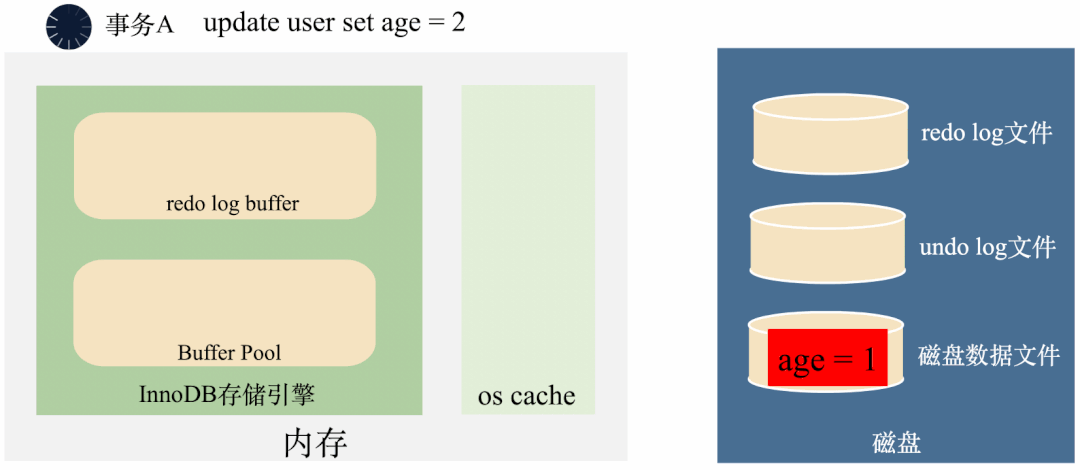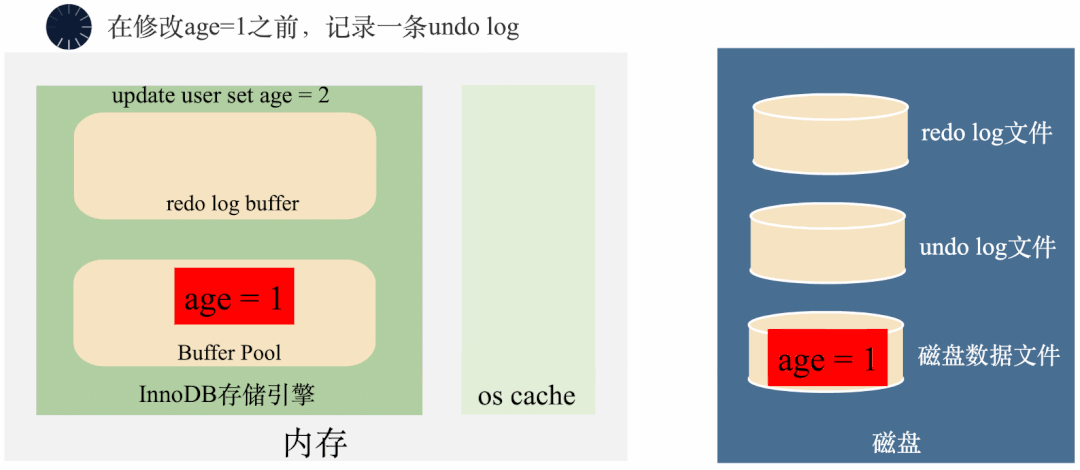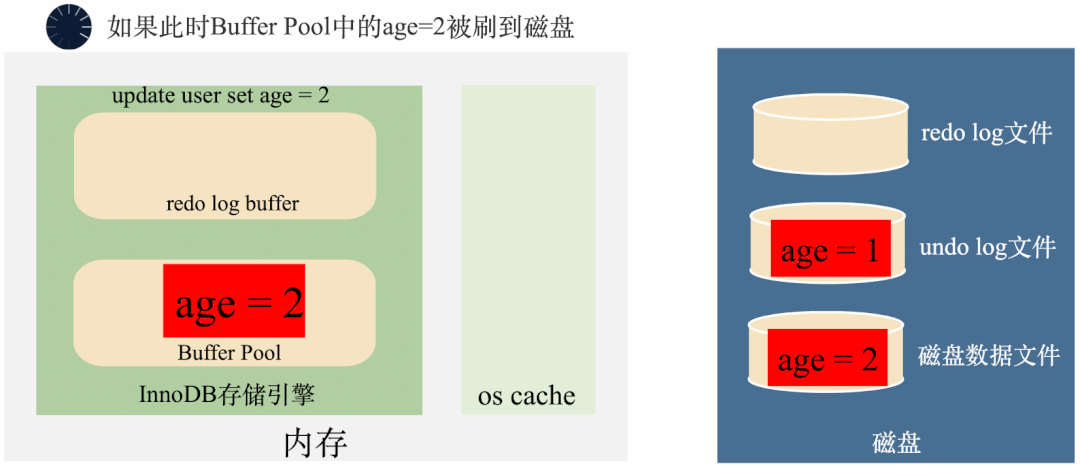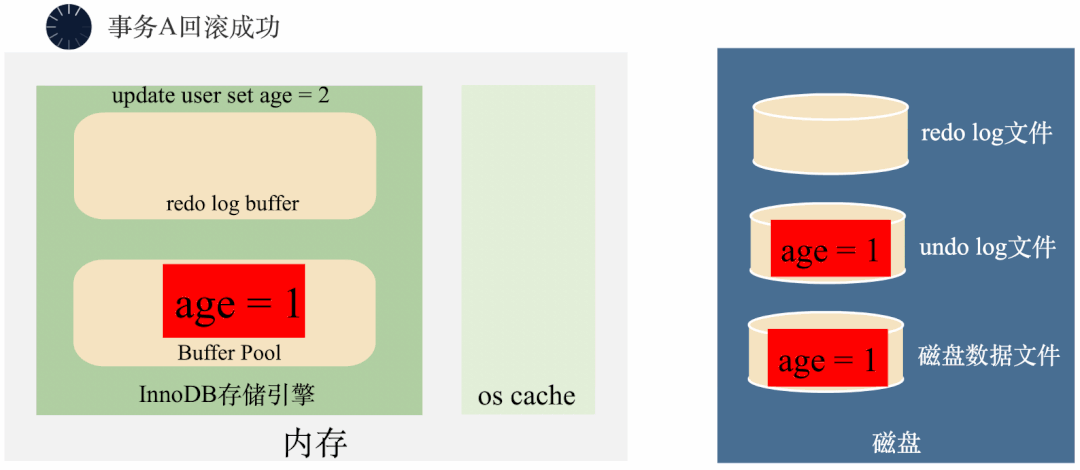
MySQL在将age = 1修改成age = 2之前,先将age = 1存到undo log里面去,这样需要回滚的时候,可以将undo log里面的age = 1读出来回滚。
需要注意的是,undo log默认存在全局表空间里面,你可以简单的理解成undo log也是记录在一个MySQL的表里面,插入一条undo log和插入一条普通数据是类似。也就是说,写undo log的过程中同样也是要写入redo log的。
归档 - binlog
undo log记录的是修改之前的数据,提供回滚的能力。
redo log记录的是修改之后的数据,提供了崩溃恢复的能力。
那binlog是干什么的呢?
binlog记录的是修改之后的数据,用于归档。
和redo log日志类似,binlog也有着自己的刷盘策略,通过sync_binlog参数控制:
sync_binlog = 0 :每次提交事务前将binlog写入os cache,由操作系统控制什么时候刷到磁盘 sync_binlog =1 :采用同步写磁盘的方式来写binlog,不使用os cache来写binlog sync_binlog = N :当每进行n次事务提交之后,调用一次fsync将os cache中的binlog强制刷到磁盘
那么问题来了,binlog和redo log都是记录的修改之后的值,这两者有什么区别呢?有redo log为什么还需要binlog呢?
首先看两者的一些区别:
binlog是逻辑日志,记录的是对哪一个表的哪一行做了什么修改;redo log是物理日志,记录的是对哪个数据页中的哪个记录做了什么修改,如果你还不了解数据页,你可以理解成对磁盘上的哪个数据做了修改。 binlog是追加写;redo log是循环写,日志文件有固定大小,会覆盖之前的数据。 binlog是Server层的日志;redo log是InnoDB的日志。如果不使用InnoDB引擎,是没有redo log的。
但说实话,我觉得这些区别并不是redo log不能取代binlog的原因,MySQL官方完全可以调整redo log让他兼并binlog的能力,但他没有这么做,为什么呢?
我认为不用redo log取代binlog最大的原因是“没必要”。
为什么这么说呢?
第一点,binlog的生态已经建立起来。MySQL高可用主要就是依赖binlog复制,还有很多公司的数据分析系统和数据处理系统,也都是依赖的binlog。取代binlog去改变一个生态费力了不讨好。
第二点,binlog并不是MySQL的瓶颈,花时间在没有瓶颈的地方没必要。
总结
Buffer Pool是MySQL进程管理的一块内存空间,有减少磁盘IO次数的作用。 redo log是InnoDB存储引擎的一种日志,主要作用是崩溃恢复,有三种刷盘策略,有innodb_flush_log_at_trx_commit 参数控制,推荐设置成2。 undo log是InnoDB存储引擎的一种日志,主要作用是回滚。 binlog是MySQL Server层的一种日志,主要作用是归档。 MySQL挂了有两种情况:操作系统挂了MySQL进程跟着挂了;操作系统没挂,但是MySQL进程挂了。
最后,再用一张图总结一下全文的知识点:
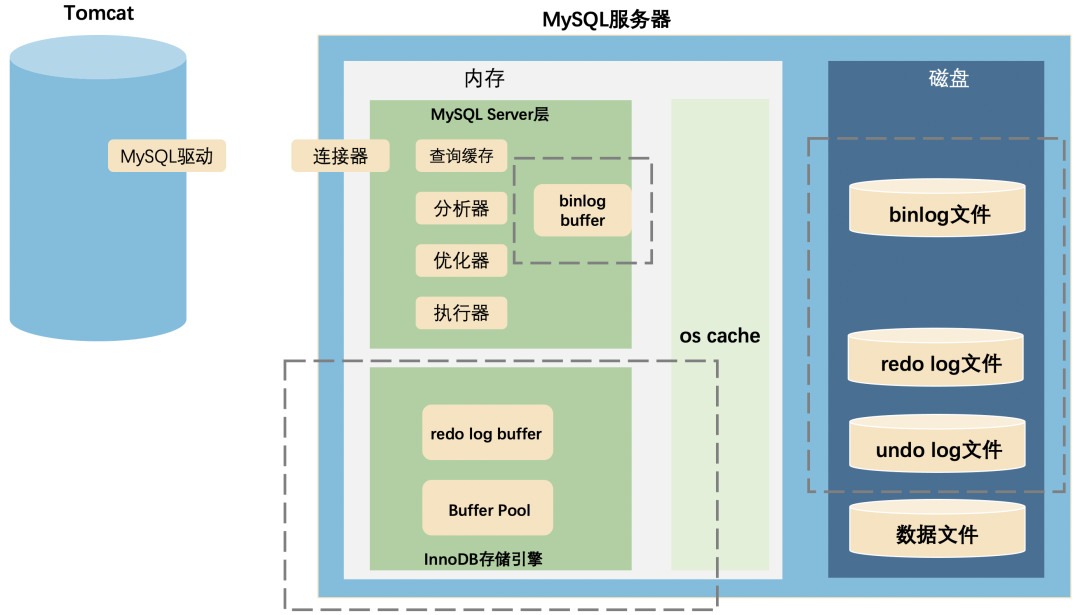
写在最后
这篇文章写在一年之前,本来觉得是一篇水文没想要发,最近无聊修改了一下发了出来,希望能够用动图的形式帮助到MySQL基础不太好的朋友,大神忽略就好。
需要强调的一点是,由于作者水平有限,本文只是浅显的从无到有地阐述了MySQL几种日志的大致作用,过程中省略了很多细节,比如Buffer Pool的实现细节,比如undo log和MVCC的关系,比如binlog buffer、change buffer的存在,比如redo log的两阶段提交。
如果您有任何问题,我们可以探讨,如果您在文中发现错误,还望您指出,万分感谢!
参考资料
《MySQL实战45讲》 《从根儿上理解MySQL》 《MySQL技术内幕—InnoDB存储引擎》第2版
完
我的新书《深入理解Java核心技术》已经上市了,上市后一直蝉联京东畅销榜中,目前正在6折优惠中,想要入手的朋友千万不要错过哦~长按二维码即可购买~
长按扫码享受6折优惠
往期推荐

还在用 SimpleDateFormat 做时间格式化?小心项目崩掉!
Logback 配置文件这样优化,TPS提高 10 倍

入职一家新公司,如何快速熟悉代码?
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️