
旷视MegEngine是如何将31*31的大核卷积计算速度提高10倍的

来源:DeepHub IMBA 本文约3400字,建议阅读5分钟
“大内核的cnn可以胜过小内核的cnn”这可能是今年来对于CNN研究最大的成果了。
内核带来了更多的计算和参数
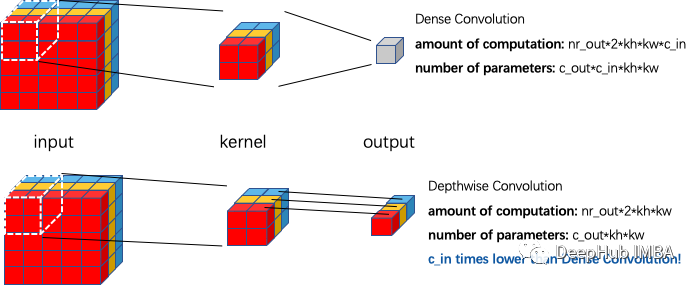
如何寻找大核卷积的优化空间?
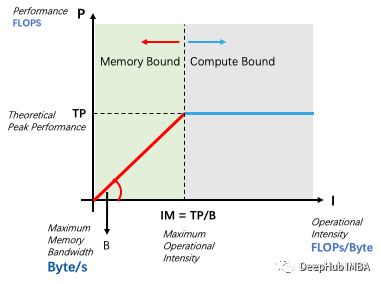
算力:每秒所完成的浮点运算次数,单位为FLOP/s或GFLOP/s 带宽:每秒所完成的内存读取量,单位为Byte/s或GByte/s 计算密度:又称访存比,是算力与带宽的比值,即每字节读取所完成的浮点运算量,单位为FLOP/Byte
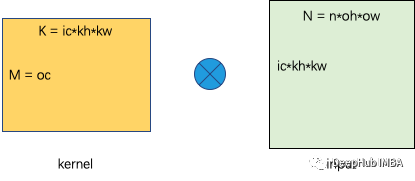
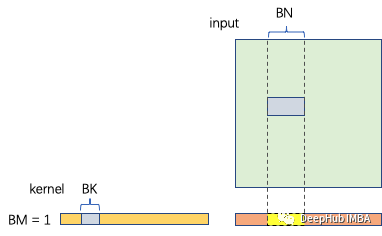
内核块大小为BM×BK 输入块大小为BK×BN 计算的次数是BM×BN×BK×2 内存访问为(BM×BK+BN×BK)×4 计算密度为BM×BN×2/(BM+BN)×4
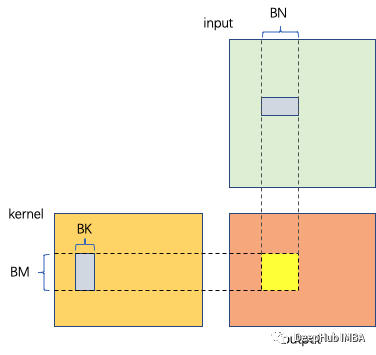
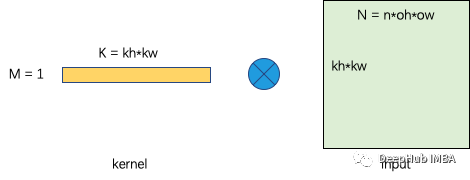
浮点运算次数=oh×ow×khkw×2 FLOPs 内存访问数= (kh×kw+(oh+kh−1)×(ow+kw−1))×4 bytes 内核大小:kh×kw 输入大小:(oh+kh−1)×(ow+kw−1) 计算密度=(oh×ow×kh×kw×2)/{(kh×kw+(oh+kh−1)×(ow+kw−1))×4}
MegEngine的表现
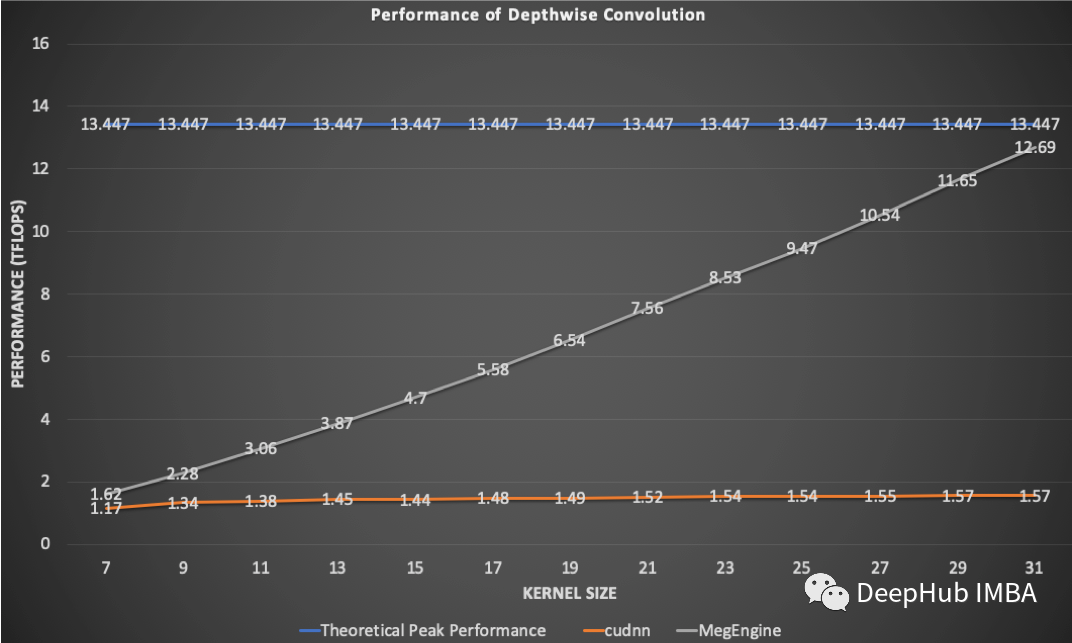
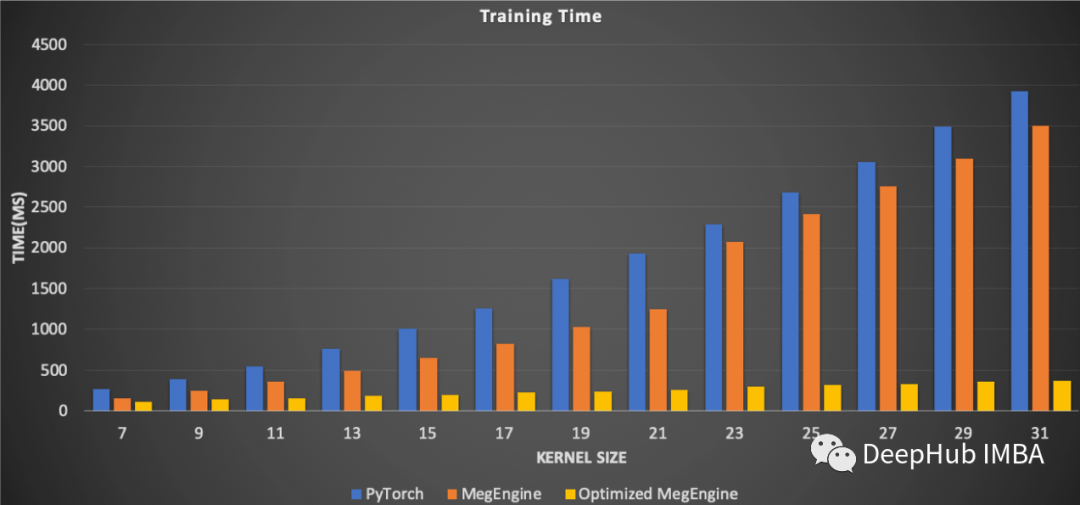
编辑:黄继彦
评论