
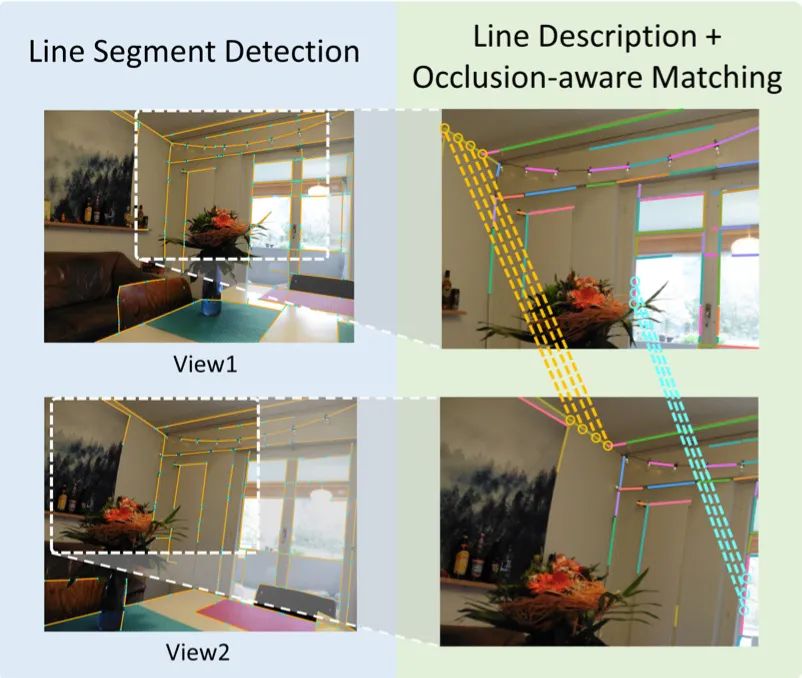
妙啊!不怕遮挡的图像线段匹配 SOLD2,还能联合自监督线段检测|CVPR2021 Oral
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

极市导读
本文介绍来自苏黎世联邦理工学院和微软的研究者们提出了首个联合检测与描述线段的深度网络:。不需要对线进行标注,可以推广到任一数据集。
线特征表示是多视图任务等多个重要的视觉任务的关键,与特征点检测和描述相比,线段检测与匹配问题也更具有挑战性。近期,来自苏黎世联邦理工学院和微软的研究者们提出了首个联合检测与描述线段的深度网络:。

由于采用了自监督学习, 不需要对线进行标注,因而可以推广到任一数据集。与线框分析(wireframe parsing)不同的是, 可对图像中的线段进行可重复且准确的定位。同时, 所提出的线描述符具有很高的可分辨性,也对视角变化和遮挡有着很强的鲁棒性。作者在现有的线检测,以及用单应变换和真实视点变化创建的多视点数据集上验证评估了这一方法。
已经被CVPR2021接收,同时作者也已经在Github上开源了相关代码。
论文链接:https://arxiv.org/abs/2104.03362
代码地址:https://github.com/cvg/SOLD2
论文背景
出于密集而强大的表示,特征点是多种计算机视觉任务的关键,例如三维重建和SLAM等。但世界由更高层次的几何结构组成,这些结构在语义上与点相比更有意义。在这些结构中,与点相比,线具备更多的优势。线在现实世界中更为广泛,尤其是在人造环境中,同时在纹理较差的区域中也有较为明显的特征。与点相反,线具有自然的方向,也能够提供有关场景结构的强大几何线索。因而,线能够很好地表示三维任务的特征。
过去,检测图像中线段的方法往往依赖于图像梯度信息和人工设置的滤波。有学者在ECCV2020上提出的TP-lsd[1]方法也实现了实时线检测。而现有的大多数线检测都在尝试解决一个问题:线框分析(wireframe parsing),即基于线段对场景的结构化布局进行推理。但是,这些方法并未针对跨图像的可重复性进行优化,这也是多视图任务的一项重要功能。同时,这些方法的训练还需要标注难度很大的真值(groud truth)。
使用特征描述符是在图像之间进行几何结构匹配的传统方法。然而,线描述符面临着一些难题,如线段可能会被部分遮挡,其端点便无法很好地进行定位,同时每条线段周围需要描述的区域波动很大,且在透视和变形变化下可能会严重形变。过去线描述符着重于提取每条线段周围的支撑区域,并在计算其梯度数据。近期研究中,受到点描述符学习相关成功研究的推动,已经有研究者提出了一些深度线描述符。但这些方法并没有对线遮挡进行设计,线端点定位的问题也悬而未决。
在 中,作者联合学习了线段的检测与描述。受LCNN [2]和Super-Point [3]的启发,作者引入了一个可以在没有任何标签的图像数据集上进行训练的自监督网络。在合成数据集上进行预训练后,将 推广到了真实图像。 所提出的线检测旨在最大程度地提高线的可重复性和准确性,使其可以尽可能准确地应用于几何估算任务。通过引入一种新颖的基于动态规划的线匹配技术,所学习到的描述符对遮挡具有鲁棒性,同时与点描述符具有相同的判别力。对标最新的特征点方法,提供了一个通用的pipeline。总结来说,所作出的贡献有以下三点:
提出了首个用于联合线段检测和描述的深度网络; 自监督的线段检测,使其能在任一真实图像数据集上进行训练; 线匹配对遮挡具有鲁棒性,在图像匹配任务上实现了SOTA。
方法简介
问题描述
线段可通过多种参数化进行表示:
两个端点; 中点,方向和长度; 中点和端点的偏移量; 引力场 ……
而在 这项工作中,鉴于其简单性和在自监督过程中的兼容性,作者选择以两个端点作为线表征。对于空间分辨率为 的图像 ,考虑所有结点的集合 和图像 的线段 。线段 由一对端点 定义。
结点和线热图推理
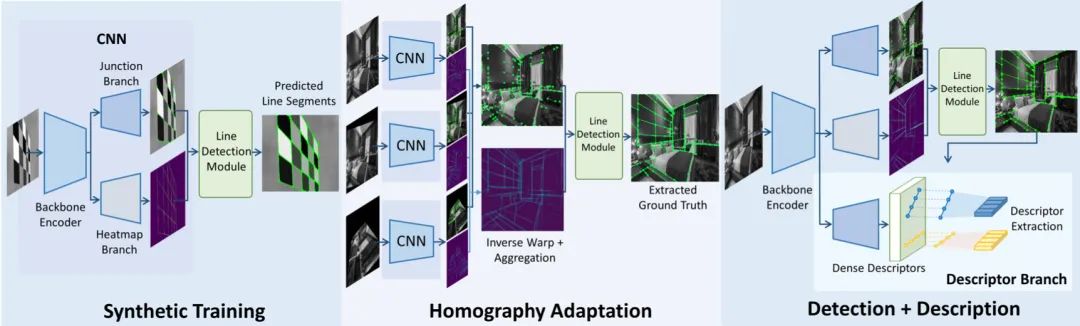
将灰度图像作为输入,通过共享的主干编码器对其进行处理,然后将其划分为三个不同的输出。交界图 预测每个像素成为线终点的概率,线热图 提供像素在线上的概率,描述符图 生成逐像素局部描述符。首先介绍集中讨论前两个分支的优化,紧接着将介绍它们用于检索和匹配图像线段的组合。
对于结点分支,作者采用与SuperPoint[3]的关键点解码器类似的方法,其中输出为 特征图 。每65维向量对应一个 块加一个额外的“无结点”垃圾箱。定义每块中真实结点表征的真值结点。当多个真值结点落在同一块中时,会随机选择一个结点,同时数值表示没有结点。结点损失是 与 之间的交叉熵损失:
在调整结点图大小以得到最终的 网格之前,对通道维度进行softmax并舍弃第65维。
第二个分支以图像分辨率 输出线热图。给定二进制真值 (如果像素在线段上则为1),通过一个二进制的交叉熵损失对线热图进行优化:
线检测
推理出结点图 和线热图 后,设置 阈值以保持最大检测量,并采用NMS来提取线段结点 。线段备选集 由 中对每一对结点组成。因为用两个端点定义线段的激活在不同备选中可能存在很大的不同,因而基于 和 提取最终的线段预测 并非易事。
方法可以分为以下四个部分:
端点之间的常规采样; 自适应局部最大值搜索; 平均得分 局内点比率
自监督学习pipeline
受SuperPoint[3]等先前工作的启发,作者将其单应适应性推广到线段中。令 和 代表网络前向传播,计算结点图和热线图。使用集合 ,单应变换 ,来汇总 SuperPoint 中的结点和热图预测:
接下来,将线检测应用于汇总的 和 ,以此获得预测的线段 ,而后将其作为真值的下一轮训练,pipeline如下图所示。与 SuperPoint相似,可以应用迭代这一过程来提高标注的质量。而事实上单次适应就能提供高质量的标注。
线描述
的描述符头输出描述符图 ,并通过在其他密集描述符中使用的基于点的三元组损失来优化。给定一对图像 和 ,并匹配这两个图像中的线段,沿着每条线段规律采样点,并从描述符图中提取相应的描述符 和 ,其中 是图像中点的总数。三元组损失使匹配点的描述符距离最小化,同时使非匹配点最大化。正距离定义为:
负距离是在点与其批最难负样本之间计算的:
其中 ,使得点 和 至少相距 个像素,并且不是同一条线的一部分,类似地适用于 。将有边际 的三元组损失定义为:
多任务学习
检测和描述线段是两个独立的任务,它们具有不同的同方差任意不确定性,同时各自的损失也可能具有不同的数量级。因此,作者采用了对损失进行动态加权的多任务学习方法[21],在训练过程中优化了权重 , 和 。总损失为:
线匹配
两条线段基于它们各自的点描述符的集合进行比较。但由于某些点可能会被遮挡,或由于角度变动造成线段长度改变,采样点可能会发生错位。然而,沿着线段匹配的点的顺序应该是恒定的,即线段描述符是一个有序的描述符序列,而不仅仅是一个集合。为了解决这一问题,作者从生物信息学中的核苷酸比对和立体视觉中沿扫描线的像素比对中得到了启发:通过动态规划算法找到了最优的点分配。
当匹配两个点序列时,每个点可以匹配另一个点或跳过。两点匹配的得分取决于它们的描述符(即点积)的相似性。跳过一个点将受到一个 分数的惩罚, 分数需要进行调整,以此更好地匹配高相似性的点和跳过低相似性的点。线匹配的总分是所有点跳过和匹配的总和,而Needleman-Wunsch(NW)算法将返回最大化该总分的最佳匹配序列。这是通过逐行填充分数矩阵的动态规划来实现的,如下图所示:
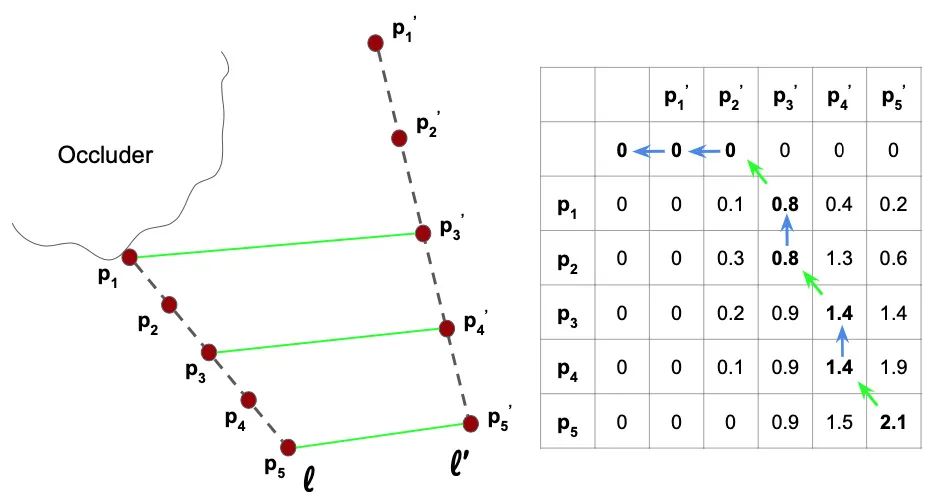
给定沿线段 的 个点的序列,沿 的 ,以及关联描述符 和 ,该得分矩阵 是一个 网格,其中 包含用 中的前 个点匹配的 中的前 个点的最优得分。网格由第一行和第一列中的 分数初始化,并使用存储在左,上和左上单元格中的分数逐行依次填充:
填充矩阵后,在网格中选择最高分数并将其用作备选线对的匹配分数,然后将第一图像的每一行与第二图像中具有最大匹配分数的行进行匹配。
实验
线检测评估
作者用结构和正交距离比较了重复性和错误阈值为5个像素的定位误差。与其他基准相比, 提供了可重复最强且准确的线检测。

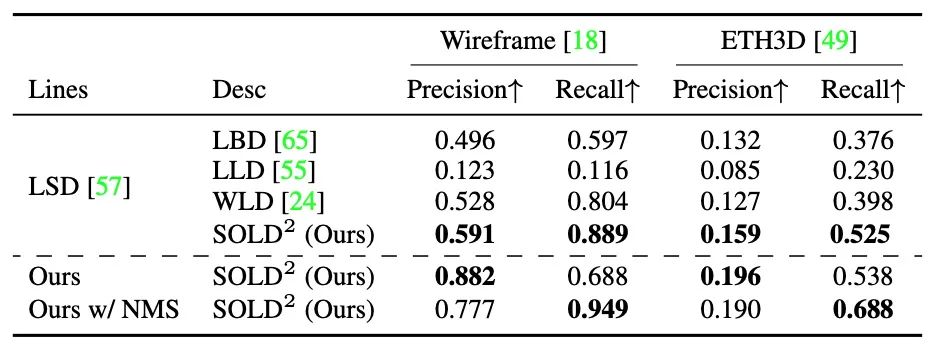
描述符评估
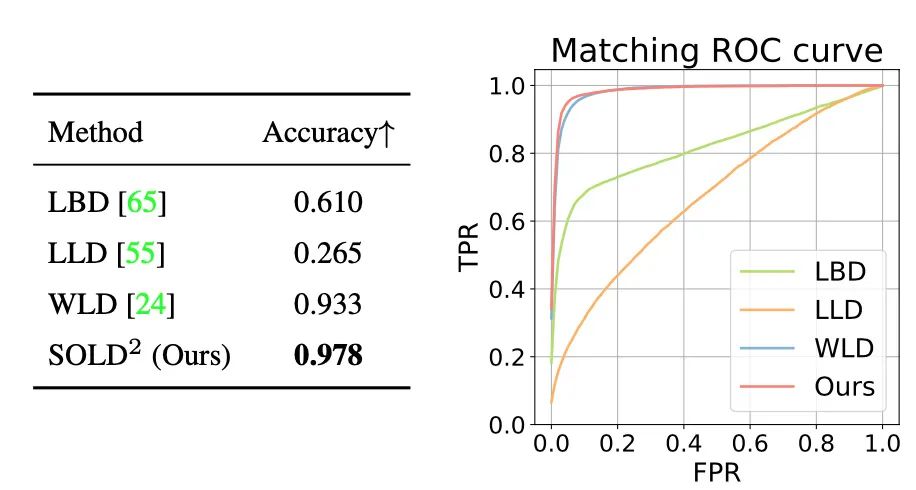
对遮挡的鲁棒性
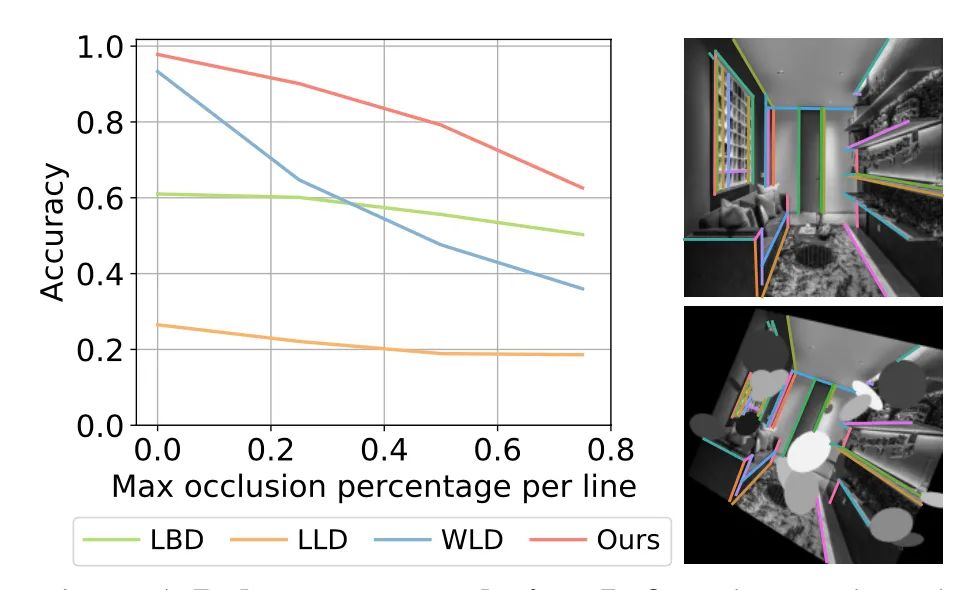
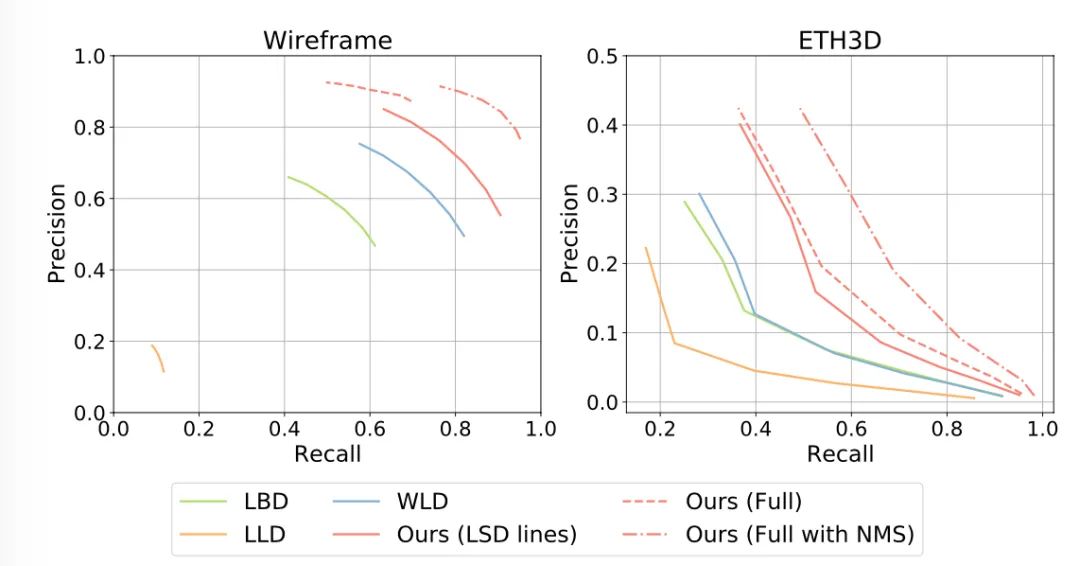
匹配精度和召回率
线匹配的可视化
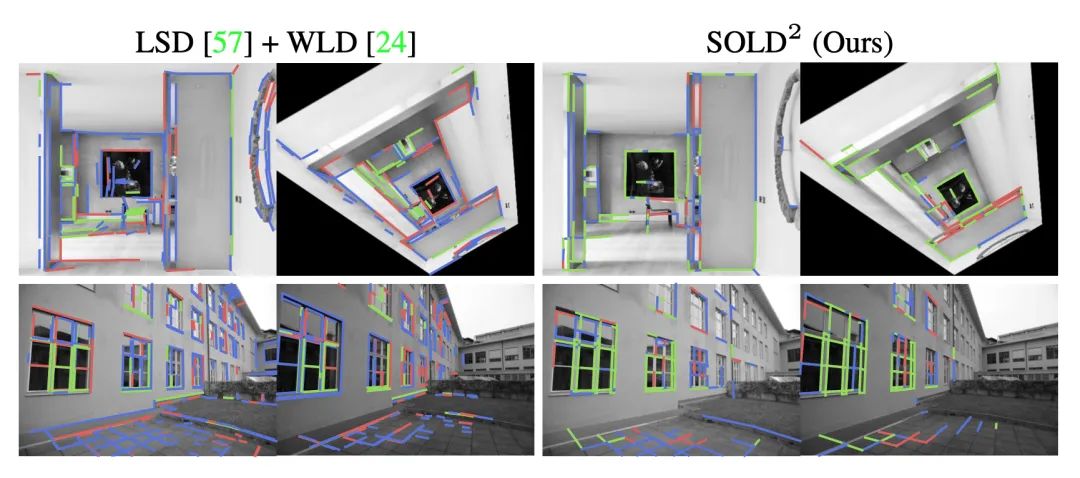
与其他方法的对比,其中绿色是正确匹配的线段,红色是错误匹配,蓝色是未匹配线段:

与其他方法进行对比的线段检测效果:

总结
作为首个用于图像中线段联合检测与描述的深度学习pipeline,由于其采用自监督训练方案,因而可以推广应用于绝大多数图像数据集。同时,受益于深层特征描述符的识别能力, 能够处理被遮挡和定位不佳的线端点等线段描述中的常见问题。 在一系列室外数据集上的评估中都证明了它在提高重复性和精度等匹配性能上的卓越能力。虽然与目前已经较为成熟的特征点匹配技术相比, 还存在许多需要继续改进的地方,也仍然有很长的一段距离,但它已经迈出了第一步。
参考文献
[1] SiyuHuang,FangboQin,PengfeiXiong,NingDing,YijiaHe, and Xiao Liu. Tp-lsd: Tri-points based line segment detector. In European Conference on Computer Vision (ECCV), 2020.
[2] Yichao Zhou, Haozhi Qi, and Yi Ma. End-to-end wireframe parsing. In International Conference on Computer Vision (ICCV), 2019.
[3] Daniel DeTone, Tomasz Malisiewicz, and Andrew Rabi- novich. Superpoint: Self-supervised interest point detection and description. In Computer Vision and Pattern Recognition Workshops (CVPRW), 2018.
本文亮点总结:
1.线框分析(wireframe parsing)不同, 可对图像中的线段进行可重复且准确的定位。同时, 所提出的线描述符具有很高的可分辨性,也对视角变化和遮挡有着很强的鲁棒性。
2. 论文贡献:
提出了首个用于联合线段检测和描述的深度网络; 自监督的线段检测,使其能在任一真实图像数据集上进行训练; 线匹配对遮挡具有鲁棒性,在图像匹配任务上实现了SOTA。