
Spring Boot 集成 Kafka
Spring Boot 作为主流微服务框架,拥有成熟的社区生态。市场应用广泛,为了方便大家,整理了一个基于spring boot的常用中间件快速集成入门系列手册,涉及RPC、缓存、消息队列、分库分表、注册中心、分布式配置等常用开源组件,大概有几十篇文章,陆续会开放出来,感兴趣同学请提前关注&收藏
消息通信有两种基本模型,即发布-订阅(Pub-Sub)模型和点对点(Point to Point)模型,发布-订阅支持生产者消费者之间的一对多关系,而点对点模型中有且仅有一个消费者。
前言
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。其持久化层本质上是一个“按照分布式事务日志架构的大规模发布/订阅消息队列”。
Kafka高效地处理实时流式数据,可以实现与Storm、HBase和Spark的集成。作为聚类部署到多台服务器上,Kafka处理它所有的发布和订阅消息系统使用了四个API,即生产者API、消费者API、Stream API和Connector API。它能够传递大规模流式消息,自带容错功能,已经取代了一些传统消息系统,如JMS、AMQP等。
为什么使用kafka?
削峰填谷。缓冲上下游瞬时突发流量,保护 “脆弱” 的下游系统不被压垮,避免引发全链路服务 “雪崩”。 系统解耦。发送方和接收方的松耦合,一定程度简化了开发成本,减少了系统间不必要的直接依赖。 异步通信:消息队列允许用户把消息放入队列但不立即处理它。 可恢复性:即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
业务场景
一些同步业务流程的非核心逻辑,对时间要求不是特别高,可以解耦异步来执行 系统日志收集,采集并同步到kafka,一般采用ELK组合玩法 一些大数据平台,用于各个系统间数据传递
基本架构
Kafka 运行在一个由一台或多台服务器组成的集群上,并且分区可以跨集群节点分布
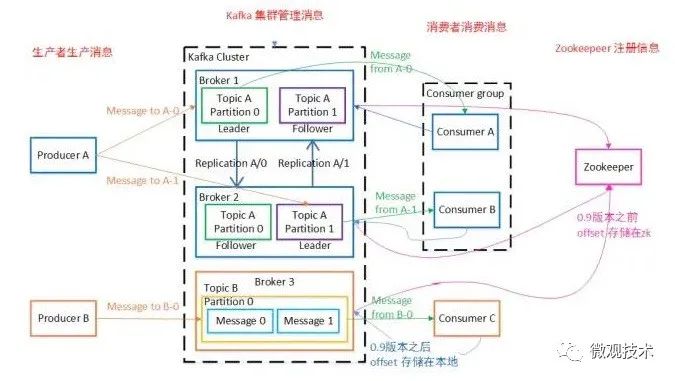
1、Producer 生产消息,发送到Broker中
2、Leader状态的Broker接收消息,写入到相应topic中。在一个分区内,这些消息被索引并连同时间戳存储在一起
3、Leader状态的Broker接收完毕以后,传给Follow状态的Broker作为副本备份
4、 Consumer 消费者的进程可以从分区订阅,并消费消息
常用术语
Broker。负责接收和处理客户端发送过来的请求,以及对消息进行持久化。虽然多个 Broker 进程能够运行在同一台机器上,但更常见的做法是将不同的 Broker 分散运行在不同的机器上 主题:Topic。主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务。 分区:Partition。一个有序不变的消息序列。每个主题下可以有多个分区。 消息:这里的消息就是指 Kafka 处理的主要对象。 消息位移:Offset。表示分区中每条消息的位置信息,是一个单调递增且不变的值。 副本:Replica。Kafka 中同一条消息能够被拷贝到多个地方以提供数据冗余,这些地方就是所谓的副本。副本还分为领导者副本和追随者副本,各自有不同的角色划分。每个分区可配置多个副本实现高可用。一个分区的N个副本一定在N个不同的Broker上。 Leader:每个分区多个副本的“主”副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。 Follower:每个分区多个副本的“从”副本,实时从 Leader 中同步数据,保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会成为新的 Leader。 生产者:Producer。向主题发布新消息的应用程序。 消费者:Consumer。从主题订阅新消息的应用程序。 消费者位移:Consumer Offset。表示消费者消费进度,每个消费者都有自己的消费者位移。offset保存在broker端的内部topic中,不是在clients中保存 消费者组:Consumer Group。多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。 重平衡:Rebalance。消费者组内某个消费者实例挂掉后,其他消费者实例自动重新分配订阅主题分区的过程。Rebalance 是 Kafka 消费者端实现高可用的重要手段。
代码演示
外部依赖:
在 pom.xml 中添加 Kafka 依赖:
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
由于spring-boot-starter-parent 指定的版本号是2.1.5.RELEASE,spring boot 会对外部框架的版本号统一管理,spring-kafka 引入的版本是 2.2.6.RELEASE
配置文件:
在配置文件 application.yaml 中配置 Kafka 的相关参数,具体内容如下:
Spring:
kafka:
bootstrap-servers: localhost:9092
producer:
retries: 3 # 生产者发送失败时,重试次数
batch-size: 16384
buffer-memory: 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer # 生产者消息key和消息value的序列化处理类
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: tomge-consumer-group # 默认消费者group id
auto-offset-reset: earliest
enable-auto-commit: true
auto-commit-interval: 100
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
对应的配置类 org.springframework.boot.autoconfigure.kafka.KafkaProperties,来初始化kafka相关的bean实例对象,并注册到spring容器中。
发送消息:
Spring Boot 作为一款支持快速开发的集成性框架,同样提供了一批以 -Template 命名的模板工具类用于实现消息通信。对于 Kafka 而言,这个工具类就是KafkaTemplate。
KafkaTemplate 提供了一系列 send 方法用来发送消息,典型的 send 方法定义如下代码所示:
public ListenableFuture<SendResult<K, V>> send(String topic, @Nullable V data) {
。。。。 省略
}
生产端提供了一个restful接口,模拟发送一条创建新用户消息。
@GetMapping("/add_user")
public Object add() {
try {
Long id = Long.valueOf(new Random().nextInt(1000));
User user = User.builder().id(id).userName("TomGE").age(29).address("上海").build();
ListenableFuture<SendResult> listenableFuture = kafkaTemplate.send(addUserTopic, JSON.toJSONString(user));
// 提供回调方法,可以监控消息的成功或失败的后续处理
listenableFuture.addCallback(new ListenableFutureCallback<SendResult>() {
@Override
public void onFailure(Throwable throwable) {
System.out.println("发送消息失败," + throwable.getMessage());
}
@Override
public void onSuccess(SendResult sendResult) {
// 消息发送到的topic
String topic = sendResult.getRecordMetadata().topic();
// 消息发送到的分区
int partition = sendResult.getRecordMetadata().partition();
// 消息在分区内的offset
long offset = sendResult.getRecordMetadata().offset();
System.out.println(String.format("发送消息成功,topc:%s, partition: %s, offset:%s ", topic, partition, offset));
}
});
return "消息发送成功";
} catch (Exception e) {
e.printStackTrace();
return "消息发送失败";
}
}
实际上开发使用的Kafka默认允许自动创建Topic,创建Topic时默认的分区数量是1,可以通过server.properties文件中的num.partitions=1修改默认分区数量。在生产环境中通常会关闭自动创建功能,Topic需要由运维人员先创建好。
消费消息:
在 Kafka 中消息通过服务器推送给各个消费者,而 Kafka 的消费者在消费消息时,需要提供一个监听器(Listener)对某个 Topic 实现监听,从而获取消息,这也是 Kafka 消费消息的唯一方式。
定义一个消费类,在处理具体消息业务逻辑的方法上添加 @KafkaListener 注解,并配置要消费的topic,代码如下所示:
@Component
public class UserConsumer {
@KafkaListener(topics = "add_user")
public void receiveMesage(String content) {
System.out.println("消费消息:" + content);
}
}
是不是很简单,添加kafka依赖、使用KafkaTemplate、@KafkaListener注解就完成消息的生产和消费,其实是SpringBoot在背后默默的做了很多工作,如果感兴趣可以研究下
spring-boot-autoconfigure,里面提供了常用开源框架的客户端实例封装。
演示工程代码
https://github.com/aalansehaiyang/spring-boot-bulking
模块:spring-boot-bulking-kafka
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。