
一行代码搞定Python逐行内存消耗分析
❝本文完整示例代码及文件已上传至我的
❞Github仓库https://github.com/CNFeffery/PythonPracticalSkills
我们即将学习的是:一行代码分析Python代码行级别内存消耗。

很多情况下,我们需要对已经写好的Python程序的内存消耗进行优化,但是一段代码在运行过程中的内存消耗是动态变化的,这种时候就可以用到memory_profiler这个第三方库,它可以帮助我们分析记录Python脚本中,执行到每一行时,内存的消耗及波动变化情况。
memory_profiler的使用方法超级简单,使用pip install memory_profiler完成安装后,只需要从memory_profiler导入profile并作为要分析的目标函数的装饰器即可,譬如下面这个例子:
❝demo.py
❞
import numpy as np
from memory_profiler import profile
@profile
def demo():
a = np.random.rand(10000000)
b = np.random.rand(10000000)
a_ = a[a < b]
b_ = b[a < b]
del a, b
return a_, b_
if __name__ == '__main__':
demo()
接着在终端执行python demo.py,稍事等待后,就会看到打印出的分析结果报告(这里我是在jupyter lab里执行的终端命令):
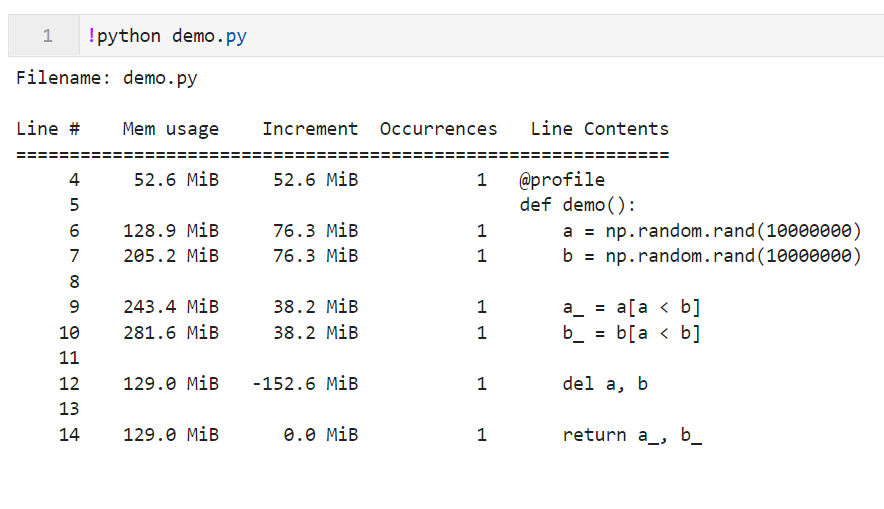
其中Line #列记录了分析的各行代码具体行位置,Mem usage列记录了当程序执行到该行时,当前进程占用内存的量,Increment记录了当前行相比上一行内存消耗的变化量,Occurrences记录了当前行的执行次数(循环、列表推导等代码行会记作多次),Line Contents列则记录了具体对应的行代码。
通过这样细致的内存分析结果,我们就能有的放矢地优化我们的代码啦~
本期分享结束,咱们下回见~👋
END
各位伙伴们好,詹帅本帅搭建了一个个人博客和小程序,汇集各种干货和资源,也方便大家阅读,感兴趣的小伙伴请移步小程序体验一下哦!(欢迎提建议)
推荐阅读
评论