
呦呦,这些代码有点臭,重构大法带你秀(SPI接口化),skr~
大家好,我是狼王,一个爱打球的程序员
如果说
正常的重构是为了消除代码的坏味道,
那么高层次的重构就是消除架构的坏味道
最近由于需要将公司基础架构的组件进行各种
兼容,适配以及二开,所以很多时候就需要对组件进行重构,大家是不是在拿到公司老项目老代码,又需要二开或者重构的时候,会头很大,无从下手,我之前也一直是这样的状态,不过在慢慢熟悉了一些重构的思想和方法之后,就能稍微的得心应手一些,下面我就开始讲下重构,然后会着重讲下重构中的SPI接口化。
先给大家看看最近通过使用SPI接口化,重构的一个组件-分布式存储。
重构前的代码结构
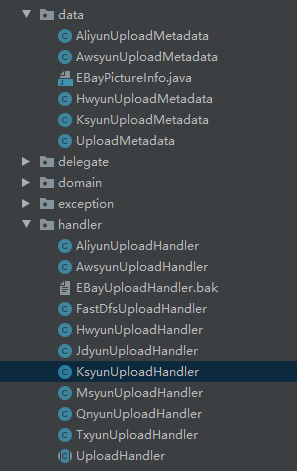 好家伙,所有的第三方存储都是写在一个模块中的,各种
好家伙,所有的第三方存储都是写在一个模块中的,各种阿里云,腾讯云,华为云等等,这样的代码架构在前期可能在不需要经常扩展,二开的时候,还是能用的。
但是当某个新需求来的时候,比如我遇到的:需要支持多个云的多个账号上传下载功能,这个是因为在不同的云上,不同账号的权限,安全认证等都是不太一样的,所以在某一刻,这个需求就被提出来了,也就是你想上传到哪个云的哪个账号都可以。
然后拿到这个代码,看了下这样的架构,可能在这样的基础上完成需求也是没有问题的,但是扩展很麻烦,而且代码会越来越繁重,架构会越来越复杂,不清晰。
所以我索性趁着这个机会,就重构一把,和其他同事也商量了下,决定分模块,SPI化,好处就是根据你想使用的引入对应的依赖,让代码架构更加清晰,后续更加容易扩展了!下面就是重构后的大体架构:
 是不是清楚多了,之后哪怕某个云存储需要增加新功能,或者需要兼容更多的云也是比较容易的了。
是不是清楚多了,之后哪怕某个云存储需要增加新功能,或者需要兼容更多的云也是比较容易的了。
好了,下面就让我们开始讲讲重构大法~
重构
重构是什么?
重构(Refactoring)就是通过调整程序代码改善软件的质量、性能,使其程序的设计模式和架构更趋合理,提高软件的扩展性和维护性。
重构最重要的思想就是让普通程序员也能写出优秀的程序。
把优化代码质量的过程拆解成一个个小的步骤,这样重构一个项目的巨大工作量就变成比如修改变量名、提取函数、抽取接口等等简单的工作目标。
作为一个普通的程序员就可以通过实现这些易完成的工作目标来提升自己的编码能力,加深自己的项目认识,从而为最高层次的重构打下基础。
而且高层次的重构依然是由无数个小目标构成,而不是长时间、大规模地去实现。
重构本质是极限编程的一部分,完整地实现极限编程才能最大化地发挥重构的价值。而极限编程本身就提倡拥抱变化,增强适应性,因此分解极限编程中的功能去适应项目的需求、适应团队的现状才是最好的操作模式。
重构的重点
重复代码,过长函数,过大的类,过长参数列,发散式变化,霰弹式修改,依恋情结,数据泥团,基本类型偏执,平行继承体系,冗余类等
下面举一些常用的或者比较基础的例子:
一些基本的原则我觉得还是需要了解的
尽量避免过多过长的创建Java对象 尽量使用局部变量 尽量使用StringBuilder和StringBuffer进行字符串连接 尽量减少对变量的重复计算 尽量在finally块中释放资源 尽量缓存经常使用的对象 不使用的对象及时设置为null 尽量考虑使用静态方法 尽量在合适的场合使用单例 尽量使用final修饰符
下面是关于类和方法优化:
重复代码的提取 冗长方法的分割 嵌套条件分支或者循环递归的优化 提取类或继承体系中的常量 提取继承体系中重复的属性与方法到父类
这里先简单介绍这些比较常规的重构思想和原则,方法,毕竟今天的主角是SPI,下面有请SPI登场!
SPI
什么是SPI?
SPI全称Service Provider Interface,是Java提供的一套用来被第三方实现或者扩展的API,它可以用来启用框架扩展和替换组件。
它是一种服务发现机制,它通过在ClassPath路径下的META-INF/services文件夹查找文件,自动加载文件里所定义的类。
这一机制为很多框架扩展提供了可能,比如在Dubbo、JDBC中都使用到了SPI机制。
下面就是SPI的机制过程

SPI实际上是基于接口的编程+策略模式+配置文件组合实现的动态加载机制。
系统设计的各个抽象,往往有很多不同的实现方案,在面向的对象的设计里,一般推荐模块之间基于接口编程,模块之间不对实现类进行硬编码。
一旦代码里涉及具体的实现类,就违反了可拔插的原则,如果需要替换一种实现,就需要修改代码。为了实现在模块装配的时候能不在程序里动态指明,这就需要一种服务发现机制。
SPI就是提供这样的一个机制:为某个接口寻找服务实现的机制。有点类似IOC的思想,就是将装配的控制权移到程序之外,在模块化设计中这个机制尤其重要。所以SPI的核心思想就是解耦。
SPI使用介绍
要使用Java SPI,一般需要遵循如下约定:
当服务提供者提供了接口的一种具体实现后,在jar包的 META-INF/services目录下创建一个以接口全限定名`为命名的文件,内容为实现类的全限定名;接口实现类所在的jar包放在主程序的 classpath中;主程序通过 java.util.ServiceLoder动态装载实现模块,它通过扫描META-INF/services目录下的配置文件找到实现类的全限定名,把类加载到JVM;SPI的实现类必须携带一个不带参数的构造方法;
SPI使用场景
概括地说,适用于:调用者根据实际使用需要,启用、扩展、或者替换框架的实现策略
以下是比较常见的例子:
数据库驱动加载接口实现类的加载
JDBC加载不同类型数据库的驱动日志门面接口实现类加载
SLF4J加载不同提供商的日志实现类Spring
Spring中大量使用了SPI,比如:对servlet3.0规范对ServletContainerInitializer的实现、自动类型转换Type Conversion SPI(Converter SPI、Formatter SPI)等Dubbo
Dubbo中也大量使用SPI的方式实现框架的扩展, 不过它对Java提供的原生SPI做了封装,允许用户扩展实现Filter接口
SPI简单例子
先定义接口类
package com.test.spi.learn;
import java.util.List;
public interface Search {
public List<String> searchDoc(String keyword);
}
文件搜索实现
package com.test.spi.learn;
import java.util.List;
public class FileSearch implements Search{
@Override
public List<String> searchDoc(String keyword) {
System.out.println("文件搜索 "+keyword);
return null;
}
}
数据库搜索实现
package com.test.spi.learn;
import java.util.List;
public class DBSearch implements Search{
@Override
public List<String> searchDoc(String keyword) {
System.out.println("数据库搜索 "+keyword);
return null;
}
}
接下来可以在resources下新建META-INF/services/目录,然后新建接口全限定名的文件:com.test.spi.learn.Search
里面加上我们需要用到的实现类
com.test.spi.learn.FileSearch
com.test.spi.learn.DBSearch
然后写一个测试方法
package com.test.spi.learn;
import java.util.Iterator;
import java.util.ServiceLoader;
public class TestCase {
public static void main(String[] args) {
ServiceLoader<Search> s = ServiceLoader.load(Search.class);
Iterator<Search> iterator = s.iterator();
while (iterator.hasNext()) {
Search search = iterator.next();
search.searchDoc("hello world");
}
}
}
可以看到输出结果:
文件搜索 hello world
数据库搜索 hello world
SPI原理解析
通过查看ServiceLoader的源码,梳理了一下,实现的流程如下:
应用程序调用ServiceLoader.load方法
ServiceLoader.load方法内先创建一个新的ServiceLoader,并实例化该类中的成员变量,包括以下:
loader(ClassLoader类型,类加载器)
acc(AccessControlContext类型,访问控制器)
providers(LinkedHashMap<String,S>类型,用于缓存加载成功的类)
lookupIterator(实现迭代器功能)
应用程序通过迭代器接口获取对象实例
ServiceLoader先判断成员变量providers对象中(LinkedHashMap<String,S>类型)是否有缓存实例对象,
如果有缓存,直接返回。如果没有缓存,执行类的装载,实现如下:
(1)读取META-INF/services/下的配置文件,获得所有能被实例化的类的名称,值得注意的是,ServiceLoader可以跨越jar包获取META-INF下的配置文件(2)通过反射方法Class.forName()加载类对象,并用instance()方法将类实例化。(3)把实例化后的类缓存到providers对象中,(LinkedHashMap<String,S>类型)
然后返回实例对象。
总结
优点
使用
SPI机制的优势是实现解耦,使得接口的定义与具体业务实现分离,而不是耦合在一起。应用进程可以根据实际业务情况启用或替换具体组件。
缺点
不能按需加载。虽然 ServiceLoader做了延迟载入,但是基本只能通过遍历全部获取,也就是接口的实现类得全部载入并实例化一遍。如果你并不想用某些实现类,或者某些类实例化很耗时,它也被载入并实例化了,这就造成了浪费。获取某个实现类的方式不够灵活,只能通过 Iterator形式获取,不能根据某个参数来获取对应的实现类。多个并发多线程使用 ServiceLoader类的实例是不安全的。加载不到实现类时抛出并不是真正原因的异常,错误很难定位。
看到上面这么多的缺点,你肯定会想,有这些弊端为什么还要使用呢,没错,在重构的过程中,
SPI接口化是一个非常有用的方式,当你需要扩展的时候,适配的时候,越早的使用你就会受利越早,在一个合适的时间,恰当的机会的时候,就鼓起勇气,重构吧!
好了。今天就说到这了,我还会不断分享自己的所学所想,希望我们一起走在成功的道路上!
乐于输出干货的Java技术公众号:狼王编程。公众号内有大量的技术文章、海量视频资源、精美脑图,不妨来关注一下!回复资料领取大量学习资源和免费书籍!
