
为什么 Python3.6 之后字典是有序的
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
字典的本质就是 hash 表,hash 表就是通过 key 找到其 value ,平均情况下你只需要花费 O(1) 的时间复杂度即可以完成对一个元素的查找,字典是否有序,并不是指字典能否按照键或者值进行排序,而是字典能否按照插入键值的顺序输出对应的键值。
比如,对于一个无序字典,插入顺序和遍历的顺序是不一致的:
>>> my_dict = dict()
>>> my_dict["name"] = "lowman"
>>> my_dict["age"] = 26
>>> my_dict["girl"] = "Tailand"
>>> my_dict["money"] = 80
>>> my_dict["hourse"] = None
>>> for key,value in my_dict.items():
... print(key,value)
...
money 80
girl Tailand
age 26
hourse None
name lowman
而一个有序字典的输出是这样的:
name lowman
age 26
girl Tailand
money 80
hourse None
那为什么 Python3.6 之后,Python 的字典就有序了呢?
先从 Python3.6 之前说起。在 Python 3.6 之前,其数据结构如下图所示:
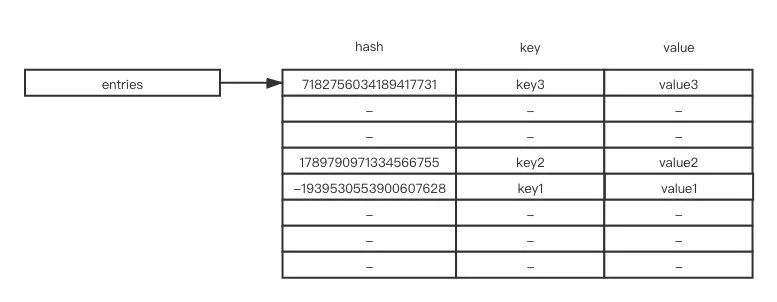
由于不同键的哈希值不一样,哈希表(entries)中的顺序是按照哈希值大小排序的,遍历时从前往后遍历并不能输出键值插入的顺序,其表现起来就是无序的。
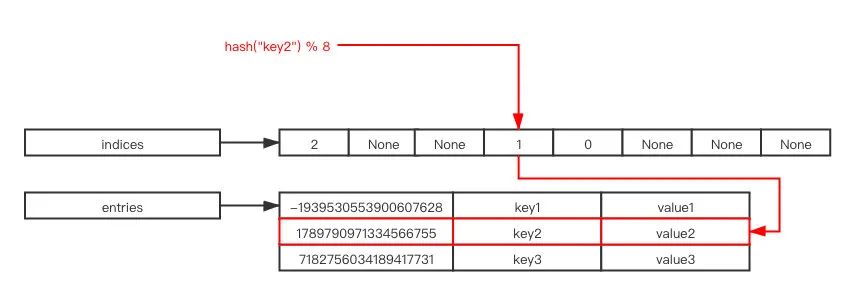
此外,这种方式还有一个缺点,就是如果以稀疏的哈希表存储时,会浪费较多的内存空间,Python3.6 之后,对其进行了优化,哈希索引和真正的键值对分开存放,数据结构如下所示:

indices 指向了一列索引,entries 指向了原本的存储哈希表内容的结构。
你可以把 indices 理解成新的简化版的哈希表,entries 理解成一个数组,数组中的每个元素是原本应该存储的哈希结果:键和值。
查找或者插入一个元素的时候,根据键的哈希值结果取模 indices 的长度,就能得到对应的数组下标,再根据对应的数组下标到 entries 中获取到对应的结果,比如 hash("key2") % 8 的结果是 3,那么 indices[3] 的值是 1,这时候到 entries 中找到对应的 entries[1] 既为所求的结果:
这么做的好处是空间利用率得到了较大的提升,我们以 64 位操作系统为例,每个指针的长度为 8 字节,则原本需要 8 * 3 * 8 为 192
现在变成了 8 * 3 * 3 + 1 * 8 为 80,节省了 58% 左右的内存空间,如下图所示:
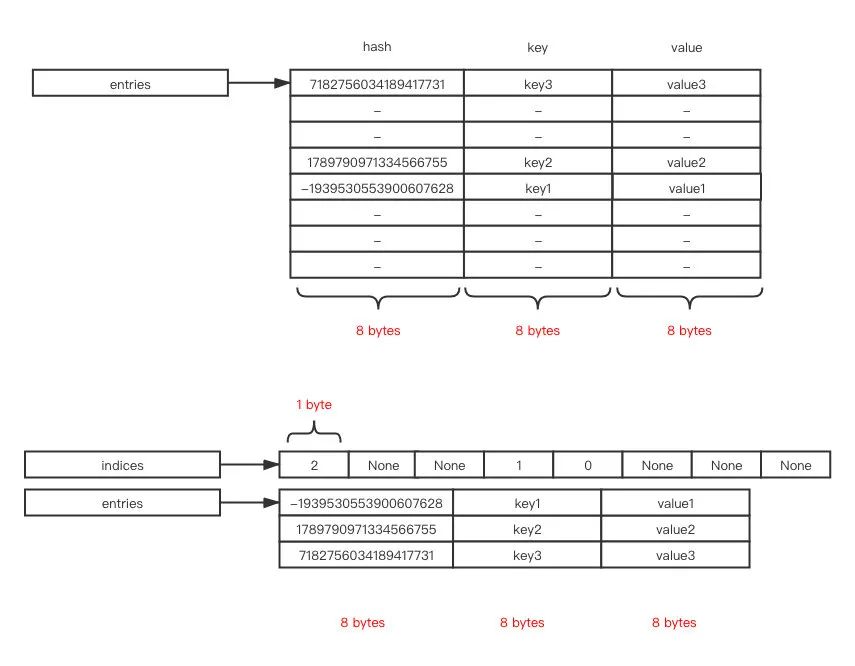
此外,由于 entries 是按照插入顺序进行插入的数组,对字典进行遍历时能按照插入顺序进行遍历,这也是为什么 Python3.6 以后的版本字典对象是有序的原因。
最后
如果你对 Python 解释器的实现感兴趣,可以阅读 CPython 的源码,源码之下无秘密,阅读源码也是提升自己最快的学习方式,这里推荐一个学习 CPython 的开源仓库 CPython-Internals[1],图文注释并茂,是非常有价值的学习资源。如果本文对你有帮助,还请点赞关注哈。
转自:python七号
参考资料
CPython-Internals: https://github.com/zpoint/CPython-Internals/blob/master/README_CN.md
推荐阅读