
微软翻译又添新语言 —— 文言文
在阅读古诗词时,我们常常惊叹于古人携风月入墨,落笔如画,仿佛世间最美的风景,都在古诗词和文言文中。
比如,我们可以在“落霞与孤鹜齐飞,秋水共长天一色”中享受绝美,在“大漠孤烟直,长河落日圆”里体会苍凉,在“气蒸云梦泽,波撼岳阳城”中感受壮阔。古代文人对人、事、物、景的诸多描写,为我们留下了灿烂的文化瑰宝。
然而,当我们读到北宋词人柳永笔下描绘的清明节旖旎春色和社会风情——“拆桐花烂熳,乍疏雨、洗清明。正艳杏烧林,缃桃绣野,芳景如屏。倾城,尽寻胜去,骤雕鞍绀幰出郊坰(zhòu diāo ān gàn xiǎn chū jiāo jiōng)。风暖繁弦脆管,万家竞奏新声”,这些略显拗口的古文,对于大多数人来说理解起来不免有些困难,很难完全体会出诗人所表达的意境。

图1:图片出自明代沈周《西山观雨图》,图中配诗为北宋柳永《木兰花慢·拆桐花烂漫》
为了解决这个问题,微软亚洲研究院的研究员们通过采用最新的神经网络机器翻译模型和训练框架,实现了文言文/古文与现代汉语之间的双向互译,以及文言文与微软翻译支持的其他90多种语言和方言的互译。目前,文言文翻译已经集成到了微软翻译应用、Azure 认知服务的翻译工具 API,以及微软翻译服务支持的包括 Office 在内的多个微软产品中。

让更多人领略中华传统文化的魅力
不少人与文言文的上一次“亲密接触”大概还停留在学生时代,有些甚至早已遗忘。近年来,无论是汉服文化的流行,还是九大博物馆联手让国宝活起来的《国家宝藏》,以现代音乐奏响经典诗词的《经典咏流传》,聚焦文化典籍的《典籍里的中国》等等,全新的展示形式让越来越多的人重新关注中华传统文化的魅力。
文言文是中华传统文化的重要载体。卷帙浩繁的古书、古文记录了中华五千年来博大精深的文化,其中沉淀、蕴含的思想和智慧,值得不断地探索与思考。因此,文言文对于传承和传播中华文化至关重要,正如想理解西方文化的精髓要从读懂莎士比亚开始一样。
有了机器翻译的帮助,游客们在游山玩水时可以看懂古建筑、古碑文上的古文和诗词,学生们在进行大语文学习时多了一个通过实践举一反三的工具,对于古籍的整理和翻译研究工作来说,也可以提升效率、事半功倍。
“从技术角度上,文言文可以看作是一个单独的语种,当文言文与现代汉语实现自由互译后,文言文与英语、法语、德语等语言的互译也就水到渠成,”微软亚洲研究院高级研究员张冬冬说道。届时,国际友人在阅读中国经典古籍时也能瞬间秒懂,了解更加原汁原味的中华传统文化。
文言文翻译 AI 模型的最大难关:训练数据少
人工智能模型训练最关键的要素是数据,数据体量足够大、质量足够高,才能训练出更加精准的模型。在机器翻译中,模型的训练更是需要双语数据:原文数据和目标语言数据。由于文言文翻译极为特殊,它并非日常用语,所以与其他语种的翻译相比,文言文翻译的训练数据非常少,并不利于机器翻译模型的训练。
尽管微软亚洲研究院的研究员们前期收集了不少公开的古今汉语数据,但原始数据却无法直接使用,需要通过数据清洗,对数据的不同源头、多样的格式以及标点符号、全角/半角等进行标准化的统一,尽可能减少无效数据对模型训练的干扰。这样下来,切实可用的高质量数据又进一步减少。据微软亚洲研究院研究员马树铭介绍,为了解决数据少的问题,研究员们做了大量的数据合成和增强工作,包括:
首先,共用字符对齐、扩展,扩大数据量。与英文、法文、俄文等其他语言的翻译不同,文言文与现代文有相同、共通的字符。利用这个特点,微软亚洲研究院的研究员们通过创新算法,让机器翻译通过对共同字符进行召回、自然对齐,再进一步扩展到词语、短语、短句,从而合成了大量可用的数据。
其次,句式变形,提升机器翻译的鲁棒性。针对句子、诗文不同的断句,研究员们增加了多种变形,让机器在古诗文学习方面更全面,例如,古诗《寻隐者不遇》,一般的断句方式是“松下问童子,言师采药去”。但对于人来说,即使是“言师采药去,只在此山中”这样非正常断句,看见时也知道它的上下句关系和意思。但对于没见过如此断句的翻译模型来说,就会“懵”,因此,通过数据格式的变形不仅能扩大训练的数据量,也能提升训练模型翻译的鲁棒性。
第三,繁简字互译训练,增加模型适应性。汉语言中,无论是文言文还是现代文,都存在繁体字。因此,为了提升模型的适应性,研究员们在训练翻译模型时,不仅有简体中文的训练,还加入了繁体中文的数据,以及繁简字夹杂的数据,让翻译模型都能看懂,翻译也就更精准。
第四,增加集外词训练,提升翻译准确度。在现代语言向文言文翻译时,还会出现一些集外词,也就是古汉语中从未出现过的新名词,如微软、电脑、高铁等近现代才出现的实体词。针对这样的“意外”,研究员们训练了一个小模型来识别实体,先将实体之外的意思翻译完成,再把实体填写回去,以确保机器对集外词处理的准确性。
此外,针对非正式文体,如博客、论坛、微博等非正规的文体,该机器翻译模型也都进行了针对性的训练,进一步提升了现代汉语与文言文之间翻译的鲁棒性。
张冬冬表示,“基于当前的翻译系统,我们还将在丰富数据集、改进模型训练方法上不断精进,使方法变得更加鲁棒、通用,未来或许不只是在文言文翻译中能够使用,还可以扩展到更多应用场景中。”
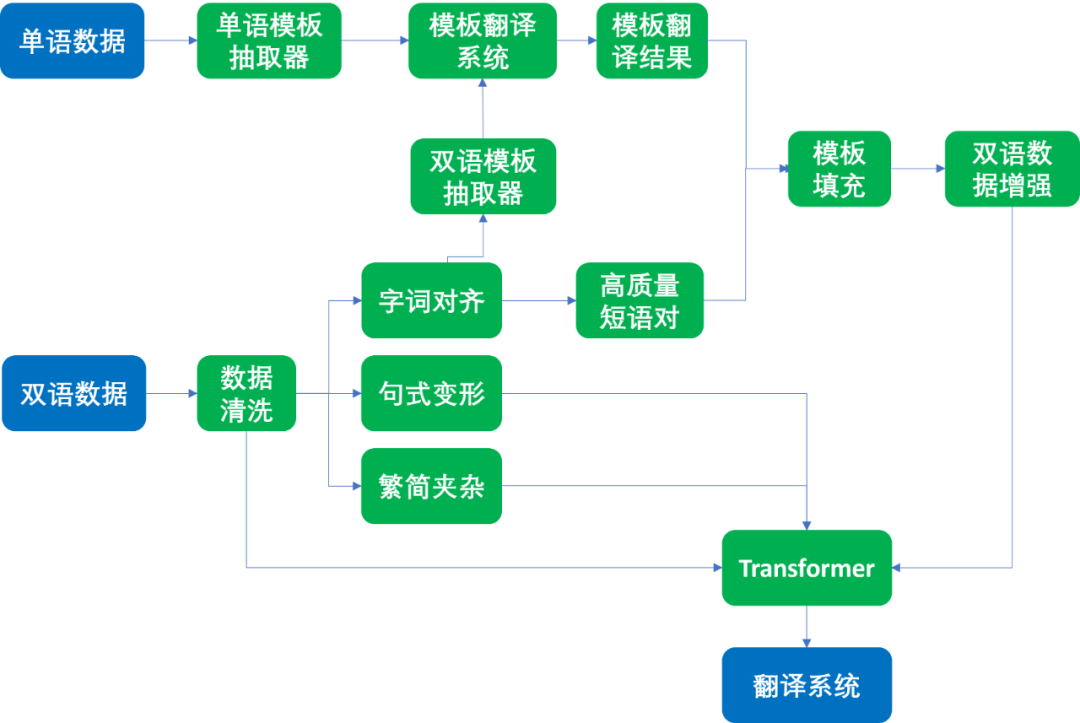
图2:文言文翻译流程
创新技术助力文化遗产的保护与传承
中华文明上下五千年的历史,由于时间和空间的限制,能够传承下来,又被后人了解和记录的内容很有限。多年来,微软亚洲研究院一直致力于将最前沿的技术和研究成果应用于历史、文化、考古等方面的保护和传承,让文化遗产以更直观、互动的方式展现在人们面前。
自2005年起,微软亚洲研究院就基于自然语言处理、机器学习等人工智能技术研发了微软对联系统,并逐渐增加了微软字谜和微软绝句。2010年,微软亚洲研究院与故宫博物院和北京大学三方合作完成了“走进清明上河图”沉浸式数字音画展示项目的研发,独创性的三维布局恢复算法和虚拟环境组织方法,让观众可以身临其境地欣赏画中的每个细节,不仅以新方式保护和传承了书画类历史文物,也给传统博物馆在新技术时代的发展带来启示。2011年,微软亚洲研究院向敦煌研究院捐赠了专门为敦煌莫高窟量身定制的“飞天号”十亿级像素数字相机系统,突破性地解决了敦煌壁画和佛龛数字化拍摄过程中的难题。
微软亚洲研究院还在积极探索与文言文专业研究机构的沟通与合作,期待从技术角度提升文言文翻译系统准确性的同时,也能够获得专业性的意见和建议。
最后,让我们来测试一下你的文言文底蕴到底有多深。请选出以下文言文语句的正确意思:
你答对了么?