
字节跳动《机器学习图文手册》火了,图文并茂,限时PDF下载!
手册内容展示
图文并茂
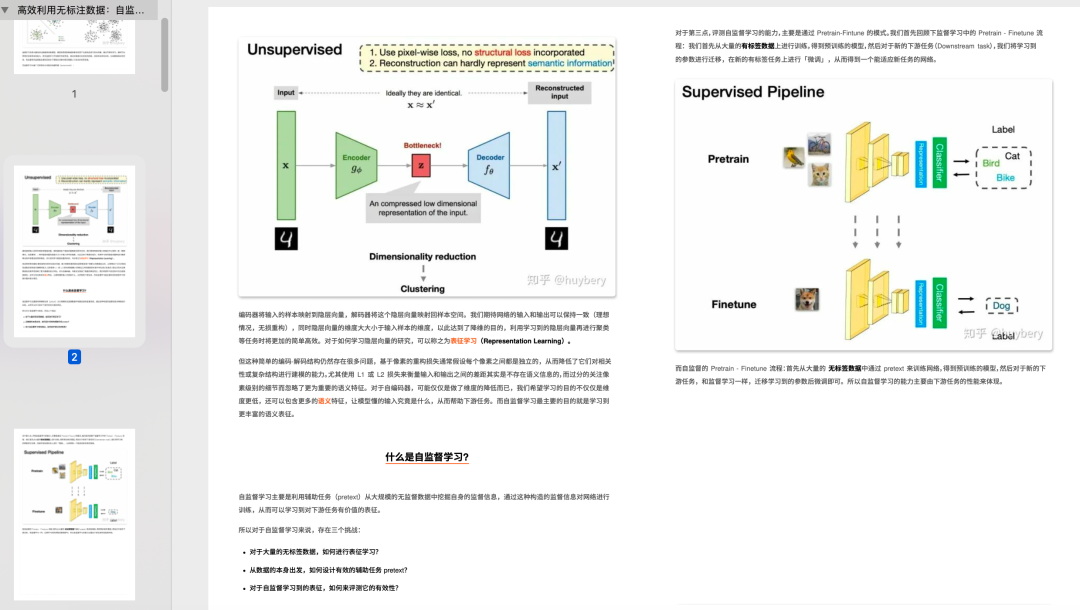
自然语言处理

论文解读
├── 机器学习
│ ├── AdaX:一个比Adam更优秀,带”长期记忆“的优化器.pdf
│ ├── 数学基础
│ │ ├── 线性代数应该这样讲-三--向量2范数与模型泛化.pdf
│ │ ├── 线性代数应该这样讲-四--奇异值分解与主成分分析.pdf
│ │ ├── 线性代数应该这样讲(一).pdf
│ │ └── 线性代数应该这样讲(二).pdf
│ ├── 硬核推导Google AdaFactor:一个省显存的宝藏优化器.pdf
│ ├── 一时学习一时爽,_持续学习_持续爽.pdf
│ ├── 强化学习扫盲贴:从Q-learning到DQN.pdf
│ ├── 经典统计机器学习模型
│ │ ├── LightGBM最强解析,从算法原理到代码实现~.pdf
│ │ ├── 深入解析GBDT二分类算法(附代码实现).pdf
│ │ ├── 机器学习系列-强填EM算法在理论与工程之间的鸿沟(上).pdf
│ │ ├── 机器学习系列-强填EM算法在理论与工程之间的鸿沟(下).pdf
│ │ ├── 深度前馈网络与Xavier初始化原理.pdf
│ │ ├── 从逻辑回归到最大熵模型.pdf
│ │ ├── 朴素贝叶斯与拣鱼的故事.pdf
│ │ ├── 从逻辑回归到受限玻尔兹曼机.pdf
│ │ ├── 逻辑回归与朴素贝叶斯的战争.pdf
│ │ ├── 从点到线:逻辑回归到条件随机场.pdf
│ │ └── 解开玻尔兹曼机的封印会发生什么?.pdf
│ ├── 史上最萌最认真的机器学习-深度学习-模式识别入门指导手册-一-.pdf
│ ├── 史上最萌最认真的机器学习-深度学习-模式识别入门指导手册-三-.pdf
│ ├── 史上最萌最认真的机器学习-深度学习-模式识别入门指导手册-二-.pdf
│ ├── 如何优雅而时髦的解决不均衡分类问题.pdf
│ ├── 别让数据坑了你!用置信学习找出错误标注(附开源实现).pdf
│ ├── 数据缺失、混乱、重复怎么办?最全数据清洗指南让你所向披靡.pdf
│ └── 还在随缘炼丹?一文带你详尽了解机器学习模型可解释性的奥秘.pdf
├── 编程基础
│ ├── 7款优秀Vim插件帮你打造完美IDE.pdf
│ ├── All in Linux:一个算法工程师的IDE断奶之路.pdf
│ ├── Git从入门到进阶,你想要的全在这里.pdf
│ └── 算法工程师的效率神器——vim篇.pdf
├── 有毒的文章
│ ├── 如果你跟夕小瑶恋爱了---(上).pdf
│ ├── 如果你跟夕小瑶恋爱了---(下).pdf
│ ├── 他与她,一个两年前的故事.pdf
│ ├── 如何优雅的追到女神夕小瑶.pdf
│ ├── 万万没想到,我的炼丹炉玩坏了.pdf
│ └── 一位老师,一位领导,一个让全体学生考上目标学校的故事.pdf
├── 自然语言处理
│ ├── 2020年学术最前沿
│ │ ├── ACL20 - 让笨重的BERT问答匹配模型变快!.pdf
│ │ ├── ACL2020 - 线上搜索结果大幅提升!亚马逊提出对抗式query-doc相关性模型.pdf
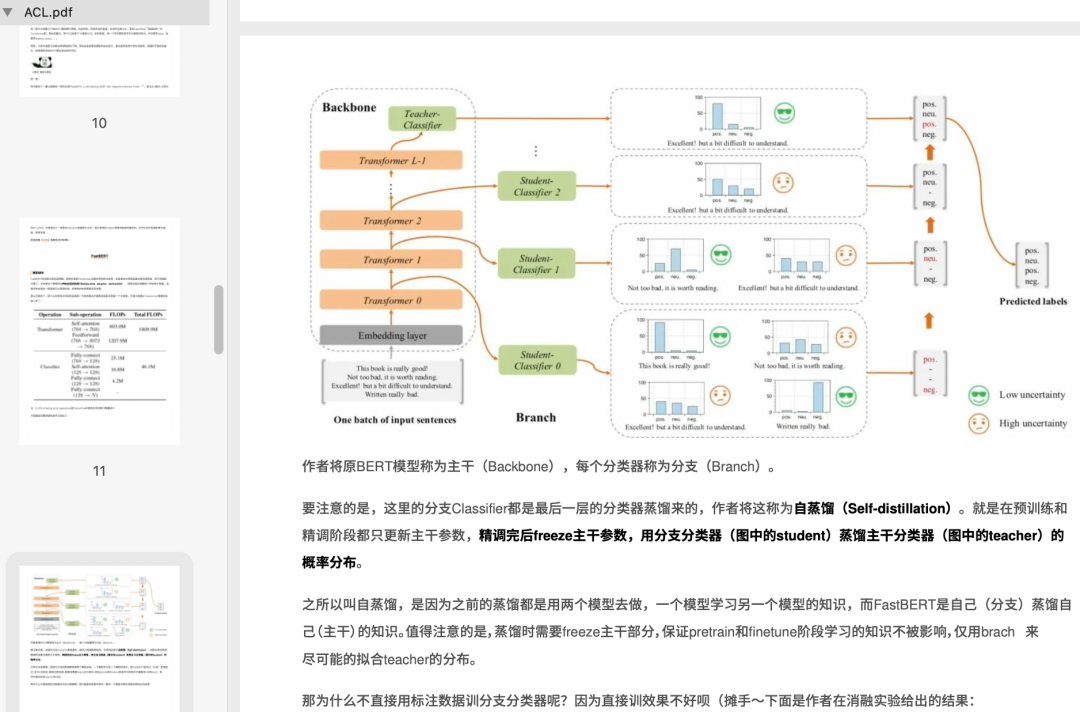
│ │ ├── ACL2020---FastBERT:放飞BERT的推理速度.pdf
│ │ ├── ACL2020---基于Knowledge-Embedding的多跳知识图谱问答.pdf
│ │ ├── ACL2020---对话数据集Mutual:论对话逻辑,BERT还差的很远.pdf
│ │ ├── GPT-3诞生,Finetune也不再必要了!NLP领域又一核弹!.pdf
│ │ ├── Google - 突破瓶颈,打造更强大的Transformer.pdf
│ │ ├── LayerNorm是Transformer的最优解吗?.pdf
│ │ ├── 当NLPer爱上CV:后BERT时代生存指南之VL-BERT篇.pdf
│ │ ├── 吊打BERT-Large的小型预训练模型ELECTRA终于开源!真相却让人---.pdf
│ │ ├── 万能的BERT连文本纠错也不放过.pdf
│ │ ├── 如何让BERT拥有视觉感知能力?两种方式将视频信息注入BERT.pdf
│ │ ├── 别再蒸馏3层BERT了!变矮又能变瘦的DynaBERT了解一下.pdf
│ │ ├── 卖萌屋上线Arxiv论文速刷神器,直达学术最前沿!.pdf
│ │ ├── 告别自注意力,谷歌为Transformer打造新内核Synthesizer.pdf
│ │ └── 如何优雅地编码文本中的位置信息?三种positioanl encoding方法简述.pdf
│ ├── 基础知识
│ │ ├── 45个小众而实用的NLP开源字典和工具.pdf
│ │ ├── NLP-Subword三大算法原理:BPE、WordPiece、ULM.pdf
│ │ ├── NLP最佳入门与提升路线.pdf
│ │ ├── NLP的游戏规则从此改写?从word2vec,-ELMo到BERT.pdf
│ │ ├── Step-by-step-to-Transformer:深入解析工作原理(以Pytorch机器翻译为例).pdf
│ │ ├── 那些击溃了所有NLP系统的样本.pdf
│ │ ├── 如何打造高质量的NLP数据集.pdf
│ │ ├── 文本分类问题不需要ResNet?小夕解析DPCNN设计原理(上).pdf
│ │ ├── 文本分类问题不需要ResNet?小夕解析DPCNN设计原理(下).pdf
│ │ ├── 搜索引擎核心技术与算法-——-倒排索引初体验.pdf
│ │ ├── 斯坦福大学最甜网剧:知识图谱CS520面向大众开放啦!.pdf
│ │ ├── 如何优雅地编码文本中的位置信息?三种positioanl encoding方法简述的副本.pdf
│ │ ├── 中文分词的古今中外,你想知道的都在这里.pdf
│ │ ├── 文本分类有哪些论文中很少提及却对性能有重要影响的tricks?.pdf
│ │ └── 史上最可爱的关系抽取指南?从一条规则到十个开源项目.pdf
│ └── 子方向综述
│ ├── NLP数据增强方法综述:EDA、BT、MixMatch、UDA.pdf
│ ├── NLP中的少样本困境问题探究.pdf
│ ├── NLP进入预训练模型时代:从word2vec,ELMo到BERT.pdf
│ ├── 后BERT时代:15个预训练模型对比分析与关键点探究.pdf
│ ├── 超一流 - 从XLNet的多流机制看最新预训练模型的研究进展.pdf
│ ├── 如何提高NLP模型鲁棒性和泛化能力?对抗训练论文综述.pdf
│ ├── 搜索中的Query理解及应用.pdf
│ ├── 工业界求解NER问题的12条黄金法则.pdf
│ ├── 从零构建知识图谱.pdf
│ ├── 对话系统的设计艺术.pdf
│ ├── 多轮对话与检索式聊天机器人(chatbot)综述.pdf
│ ├── 文本匹配相关方向打卡点总结.pdf
│ ├── 文本生成评价指标的进化与推翻.pdf
│ ├── 限定域文本语料的短语挖掘综述.pdf
│ ├── 任务完成型对话之对话状态追踪DST综述.pdf
│ ├── 基于知识图谱的篇章标签生成综述.pdf
│ ├── 智能问答系统与机器阅读理解分方向综述.pdf
│ ├── 预训练模型关键问题梳理与面试必备高频FAQ.pdf
│ └── 中文分词的古今中外,你想知道的都在这里.pdf
├── 算法岗求职必备
│ ├── 13个offer,8家SSP,谈谈我的秋招经验.pdf
│ ├── Google、MS和BAT教给我的面试真谛.pdf
│ ├── 面试必备基础知识
│ │ ├── 算法与数据结构--空间复杂度O-1-遍历树.pdf
│ │ ├── 「小公式」平均数与级数.pdf
│ │ ├── 算法工程师思维导图—深度学习篇.pdf
│ │ ├── 「小算法」回文数与数值合法性检验.pdf
│ │ ├── 算法工程师思维导图—数据结构与算法.pdf
│ │ ├── 算法工程师思维导图—统计机器学习篇.pdf
│ │ ├── 预训练模型关键问题梳理与面试必备高频FAQ.pdf
│ │ └── 卖萌屋算法岗面试手册上线!通往面试自由之路.pdf
│ ├── 别再搜集面经啦!小夕教你斩下NLP算法岗offer!.pdf
│ ├── 在大厂和小厂做算法有什么不同?.pdf
│ └── 拒绝跟风,谈谈几种算法岗的区别和体验.pdf
└── 深度学习与炼丹技巧
├── 基础篇
│ ├── 深度解析LSTM神经网络的设计原理.pdf
│ ├── 训练神经网络时如何确定batch的大小?.pdf
│ ├── 不要再纠结卷积的公式啦!0公式深度解析全连接前馈网络与卷积神经网络.pdf
│ ├── 你的模型真的陷入局部最优点了吗?.pdf
│ └── 从前馈到反馈:解析循环神经网络(RNN)及其tricks.pdf
├── 实践篇
│ ├── All in Linux:一个算法工程师的IDE断奶之路.pdf
│ ├── BERT重计算:用22.5%的训练时间节省5倍的显存开销(附代码).pdf
│ ├── 训练效率低?GPU利用率上不去?快来看看别人家的tricks吧~.pdf
│ ├── 算法工程师的效率神器——vim篇.pdf
│ ├── 万万没想到,我的炼丹炉玩坏了.pdf
│ ├── 显存不够,如何训练大型神经网络?.pdf
│ ├── 模型训练太慢?显存不够用?这个算法让你的GPU老树开新花.pdf
│ └── 别再喊我调参侠!夕小瑶“科学炼丹”手册了解一下.pdf
└── 理论篇
├── AdaX:一个比Adam更优秀,带”长期记忆“的优化器.pdf
├── ICLR2020---如何判断两个神经网络学到的知识是否一致.pdf
├── ICLR2020满分论文 - 为什么梯度裁剪能加速模型训练?.pdf
├── 硬核推导Google AdaFactor:一个省显存的宝藏优化器.pdf
├── 一时学习一时爽,_持续学习_持续爽.pdf
├── 高效利用无标注数据:自监督学习简述.pdf
└── 别让数据坑了你!用置信学习找出错误标注(附开源实现).pdf获取方式
1. 首先扫描下方二维码
2. 后台回复「机器学习」即可获取
评论