
美团Service Mesh服务治理体系落地实践
点击上方蓝色字体,选择“设为星标”


美团主要的服务治理体系是围绕Octo搭建的,随着ServiceMesh的概念兴起,美团的服务治理解决方案,也在朝着Mesh方向演进。
美团服务治理的发展史,整体分为四个阶段:
基础治理的统一:实现了通信框架及注册中心的统一,由统一的治理平台支撑节点管理、流量管理、监控预警等运营能力;
提升性能及易用性:qps从2w提升到10w,99分为线1ms,建立分布式链路追踪、分阶段耗时精细化埋点等功能;
全方位丰富治理能力:落地了全链路压测平台、性能诊断优化平台、稳定性保障平台、鉴权加密等一系列平台,实现了链路级别的流量治理,全链路灰度发布等;
跨地域的容灾及扩展能力:每天数千万订单的单元化,实现了所有PaaS层组件及核心存储系统的打通;

目前所面对的特点有两个:业务发展多元化,治理需求精细化。
展开来说,比如业务和中间件强耦合,制约彼此迭代。中间件的bug会要求业务系统大面积的升级,整体迭代成本高。非java语言治理体系薄弱,很多主流中间件缺少相关sdk。
解决思路是,隔离出基础设施层建设标准化的治理运行时,在标准之上建立体系。
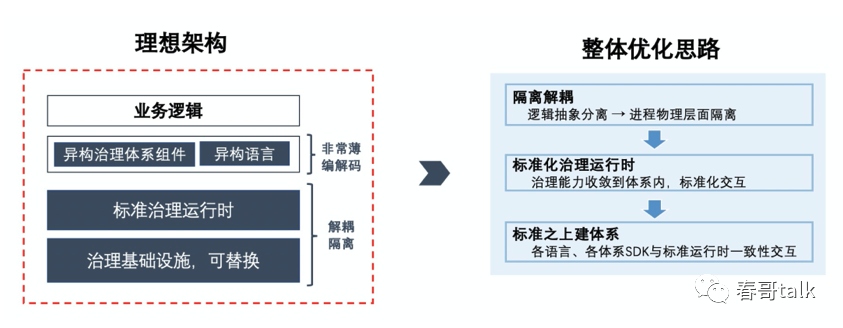
在业务进程旁附属一个Proxy进程,SDK发出及接收的流量会被附属的Proxy进程拦截。一些标准化的服务治理能力,如:限流、路由等,会由Proxy和中心化的控制大脑完成,并由控制面对接所有治理子系统集成。
这种方案下SDK很轻薄、异构语言、异构治理体系就很容易打通,和业界的Mesh思想很像(Proxy类似数据面,中心化控制类似于控制面)。
如图:

基于此思想,美团的整体服务治理方向,向着Mesh解决方案做迁移。
美团的数据面采用Envoy二次开发,控制面以自研为主,结合SDK协同升级方案。
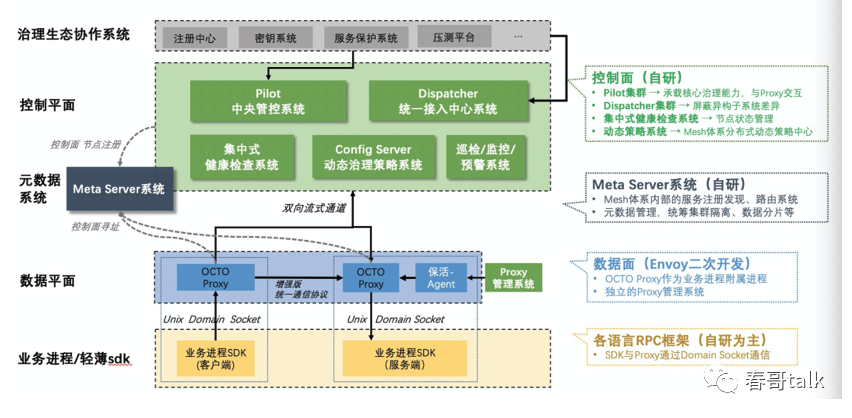
多语言轻薄的SDK与Proxy通过UDS交互,主要考虑到相比于透明流量劫持,UDS性能与可运维性更好。
控制面与Proxy通过双向流通信,控制面与治理生态的多个子系统交互,将计算处理后的数据与策略下发到Proxy执行,协同配合完成路由、限流等核心治理功能。
控制面中有多个自研独立服务:Pilot承载治理能力,与Proxy交互、Dispatcher负责屏蔽异构子系统差异、集中式健康检查节点状态、Config Server管理Mesh体系内相关策略、监控巡检系统负责提升稳定性。
Meta Server实现了Mesh体系内的节点注册和寻址,通过管理控制面和数据面连接关系,实现按业务群的隔离与水平扩展能力。
由于美团之前的服务治理体系是基于中心化Proxy的平台调度,迁移到Sidecar的Mesh方案下,需要做到业务无感,同时要保证较好的稳定性。
主要做法:
与现有基础设施及治理体系兼容,将Mesh与Octo深度打通,保障各子系统使用方式不变;在运行层面支持容器、虚拟机、物理机;打通运维体系,保障服务治理基础设施可管理、可检测。
协议兼容,服务间调用是多对多的关系,为实现Mesh与非Mesh的互通,需要在协议层面做到完全透明;对于异常处理,需要在SDK和Proxy之间达成共识,保证兼容;无法在控制面和数据面实现的能力,在SDK中执行通过上下文传递给Proxy,保障功能完全对齐。
Mesh与非Mesh模式的无缝切换,基于UDS通信,需要业务升级一次SDK版本,可以默认不开启Mesh状态;在可视化平台通过开关操作,可以无成本实现从Mesh模式与非Mesh模式之间的切换,并实时生效。
为解决异构性问题,采用了标准化服务治理运行时的手段。
比如,在架构层面由控制面实现统一的子治理系统对接,屏蔽了注册中心、鉴权、限流等具体实现机制的异构性问题。
将数据面+控制面定义为标准化的服务治理运行时,在标准运行时内打通所有治理能力。
建设统一接入中心Dispatcher,由其屏蔽对接子系统的异构性差异,从而实现外部系统的差异性对Pilot透明。
对于异构语言、异构体系使用增强的统一协议交互,实现互通。
如图:

以摩拜单车流量改造对比查看:
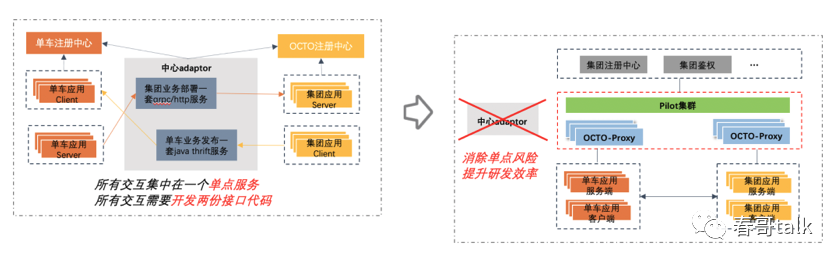
美团的服务规模还是比较庞大的,需要对Istio做一定的改造升级,才可以支持美团规模化Mesh使用的问题。
规模化Mesh的目标:具备支撑数万服务、百万节点体量的系统能力、支持水平扩展。
面对Istio需要解决的问题:
美团的体量是Istio产品上限的千倍。
美团场景下,有极高的实时性与准确性要求,配置下发或丢失将引发流量异常。

问题分析:
Istio的每个控制面实例由ETCD存储系统的全部数据,无法水平扩展。
每个Proxy独立与ETCD交互,同一个服务的Proxy请求内容相同,独立的交互方式有大量的IO冗余。当Proxy批量发版或网络抖动时,瞬时风暴会压垮ETCD。
每个节点都会探活其他节点,10w+节点规模集群,每个检测周期都是百亿次的探活,会引发网络风暴。
解决措施
横向数据分片
对于Istio控制面实例承载的全集群数据问题,对应的措施是通过横向数据分片实现扩展性支持:
proxy启动时,向Meta Server系统请求需要连接的Pilot IP,Meta Server将相同服务的Proxy尽量落到同一控制面节点,这样数据大体是一样的,每个Pilot实例按需加载,而不需要承载所有数据。
控制面节点异常或发布更新时,其所管理的Proxy会规律的迁移,恢复后,会接管其所负责的Proxy,实现了会话粘滞,实现了逻辑数据分片。
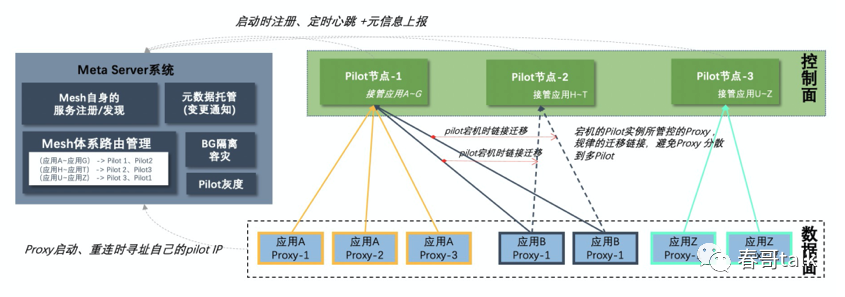
通过链接管理,实现了按事业群、按服务灰度的平台能力,同时解决了Mesh水平扩展问题。
纵向分层订阅
对于Istio独立管理各Proxy链接的IO冗余问题,对应的措施是通过分层订阅减少冗余IO。
Proxy不直接与存储系统对接,而是在中间经过多步处理:
基于快照缓存+索引机制,减少zk watcher同步。相同服务的Proxy所关注的内容是相同的,不同服务的Proxy的关注也会存在大量的冗余。分层订阅模式下,proxy不与注册中心直接交互,而是通过中间层的快照缓存分层方式,确保每个Pilot实例中zk相同路径的监听,最多1个watcher,获取到watcher通知后,pilot根据内存快照缓存+索引,向所有关注者分发,降低了冗余。
治理能力层和会话层,实现了类似于IO多路复用的能力,提升了并发吞吐。

基于此设计,有效的应对了网络抖动或批量发版的瞬间风暴压力。
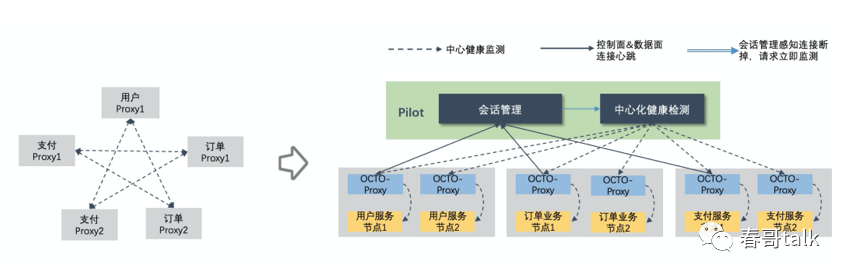
集中式健康检测
对于大规模集群内指数级膨胀的节点健康检测次数,对应措施是摒弃了P2P检测模式。
当Pilot感知到Proxy异常时,会立即通知中心化健康检测系统进行检测,而不是等待检测周期窗口的到来,可以有效提升业务调用的成功率。
对于交易属性的业务,Mesh接入更加谨慎。

在业务接入之前,基础架构平台建设了精细化运营体系:
基于SOA分级,将服务划分为非核心和核心服务,对于非核心服务进行线下环境的重点突破。
在运营平台,通过校验SDK版本、运行时环境等信息,筛选出满足条件的服务,服务负责同学在平台可以实现开关启关闭、节点选择、指定Mesh流量等工作,与内部IM联动,提升了数据运营效率。
服务接入Mesh后,运营层面有足够的详细数据,基于稳定性策略,可以在Mesh模式异常时,自动切换回非Mesh模式。
在UDS通信之外,还实现了增量聚合下发、序列化优化措施,实现了不必要的解包,提升了通信效率。
为提升整体Mesh架构的可用性,做了多级的流量保护:
当proxy不可用时,流量自动fallcack到非mesh模式;支持按节点的1/1000比例的流量灰度控制。
基于FD迁移+SDK配合协议交互,实现Proxy无损热重启的能力。
控制面配置下发错误比停发配置更加危险,针对于此建设了应用层面和系统层面的周期性巡检,实现了端到端应用视角的验证正确性,避免因变更引发的异常。
建设限流、熔断等对中心化控制面的服务保护,让系统柔性可用,当控制面全面异常时,可以通过缓存机制实现一段时间的可用。