
操作系统总结,写的很棒!
点击上方“C语言与CPP编程”,选择“关注/置顶/星标公众号”
干货福利,第一时间送达!
一、概述
基本特征
1. 并发
2. 共享
3. 虚拟
4. 异步
基本功能
1. 进程管理
2. 内存管理
3. 文件管理
4. 设备管理
系统调用
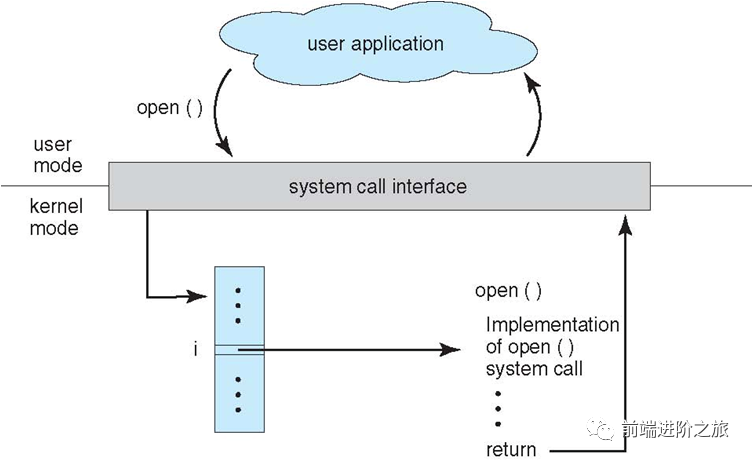
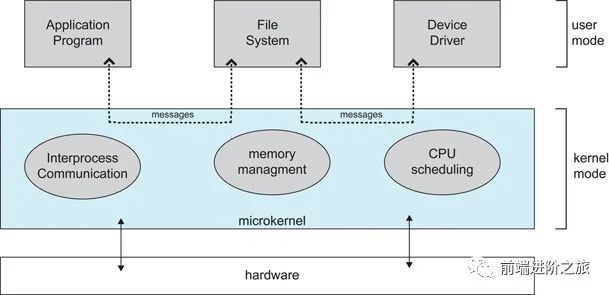
大内核和微内核
1. 大内核
2. 微内核
中断分类
1. 外中断
2. 异常
3. 陷入
二、进程管理
进程与线程
1. 进程
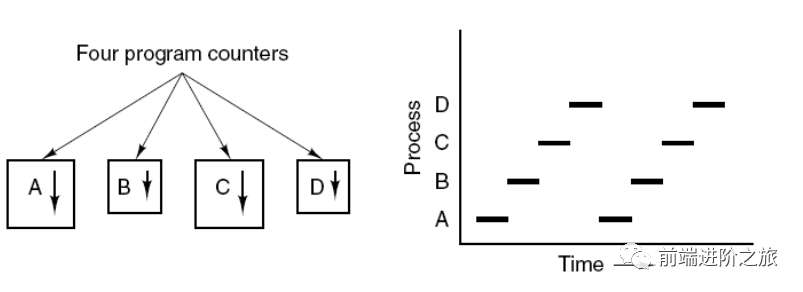
2. 线程
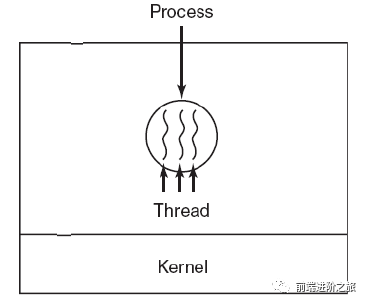
3. 区别
进程状态的切换
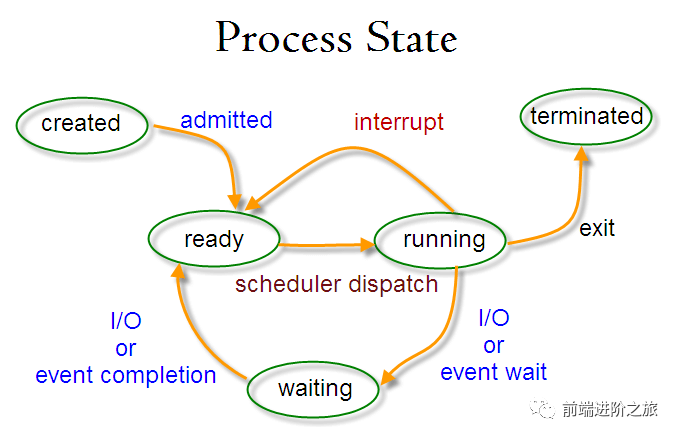
就绪状态(ready):等待被调度 运行状态(running) 阻塞状态(waiting):等待资源
只有就绪态和运行态可以相互转换,其它的都是单向转换。就绪状态的进程通过调度算法从而获得 CPU 时间,转为运行状态;而运行状态的进程,在分配给它的 CPU 时间片用完之后就会转为就绪状态,等待下一次调度。 阻塞状态是缺少需要的资源从而由运行状态转换而来,但是该资源不包括 CPU 时间,缺少 CPU 时间会从运行态转换为就绪态。
进程调度算法
1. 批处理系统
2. 交互式系统
因为进程切换都要保存进程的信息并且载入新进程的信息,如果时间片太小,会导致进程切换得太频繁,在进程切换上就会花过多时间。 而如果时间片过长,那么实时性就不能得到保证。
3. 实时系统
进程同步
1. 临界区
// entry section// critical section;// exit section
2. 同步与互斥
同步:多个进程因为合作产生的直接制约关系,使得进程有一定的先后执行关系。 互斥:多个进程在同一时刻只有一个进程能进入临界区。
3. 信号量
down : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0; up :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
typedef int semaphore;semaphore mutex = 1;void P1() {down(&mutex);// 临界区up(&mutex);}void P2() {down(&mutex);// 临界区up(&mutex);}
#define N 100typedef int semaphore;semaphore mutex = 1;semaphore empty = N;semaphore full = 0;void producer() {while(TRUE) {int item = produce_item();down(&empty);down(&mutex);insert_item(item);up(&mutex);up(&full);}}void consumer() {while(TRUE) {down(&full);down(&mutex);int item = remove_item();consume_item(item);up(&mutex);up(&empty);}}
4. 管程
monitor ProducerConsumerinteger i;condition c;procedure insert();begin// ...end;procedure remove();begin// ...end;end monitor;
// 管程monitor ProducerConsumercondition full, empty;integer count := 0;condition c;procedure insert(item: integer);beginif count = N then wait(full);insert_item(item);count := count + 1;if count = 1 then signal(empty);end;function remove: integer;beginif count = 0 then wait(empty);remove = remove_item;count := count - 1;if count = N -1 then signal(full);end;end monitor;// 生产者客户端procedure producerbeginwhile true dobeginitem = produce_item;ProducerConsumer.insert(item);endend;// 消费者客户端procedure consumerbeginwhile true dobeginitem = ProducerConsumer.remove;consume_item(item);endend;
经典同步问题
1. 哲学家进餐问题
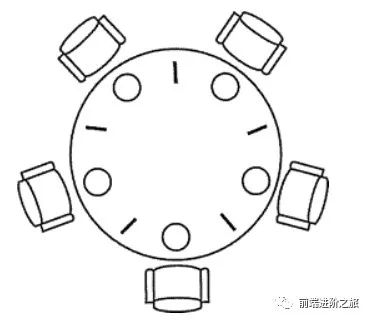
#define N 5void philosopher(int i) {while(TRUE) {think();take(i); // 拿起左边的筷子take((i+1)%N); // 拿起右边的筷子eat();put(i);put((i+1)%N);}}
必须同时拿起左右两根筷子; 只有在两个邻居都没有进餐的情况下才允许进餐。
#define N 5#define LEFT (i + N - 1) % N // 左邻居#define RIGHT (i + 1) % N // 右邻居#define THINKING 0#define HUNGRY 1#define EATING 2typedef int semaphore;int state[N]; // 跟踪每个哲学家的状态semaphore mutex = 1; // 临界区的互斥,临界区是 state 数组,对其修改需要互斥semaphore s[N]; // 每个哲学家一个信号量void philosopher(int i) {while(TRUE) {think(i);take_two(i);eat(i);put_two(i);}}void take_two(int i) {down(&mutex);state[i] = HUNGRY;check(i);up(&mutex);down(&s[i]); // 只有收到通知之后才可以开始吃,否则会一直等下去}void put_two(i) {down(&mutex);state[i] = THINKING;check(LEFT); // 尝试通知左右邻居,自己吃完了,你们可以开始吃了check(RIGHT);up(&mutex);}void eat(int i) {down(&mutex);state[i] = EATING;up(&mutex);}// 检查两个邻居是否都没有用餐,如果是的话,就 up(&s[i]),使得 down(&s[i]) 能够得到通知并继续执行void check(i) {if(state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] !=EATING) {state[i] = EATING;up(&s[i]);}}
2. 读者-写者问题
typedef int semaphore;semaphore count_mutex = 1;semaphore data_mutex = 1;int count = 0;void reader() {while(TRUE) {down(&count_mutex);count++;if(count == 1) down(&data_mutex); // 第一个读者需要对数据进行加锁,防止写进程访问up(&count_mutex);read();down(&count_mutex);count--;if(count == 0) up(&data_mutex);up(&count_mutex);}}void writer() {while(TRUE) {down(&data_mutex);write();up(&data_mutex);}}
int readcount, writecount; //(initial value = 0)semaphore rmutex, wmutex, readLock, resource; //(initial value = 1)//READERvoid reader() {down(&readLock); // reader is trying to enterdown(&rmutex); // lock to increase readcountreadcount++;if (readcount == 1)down(&resource); //if you are the first reader then lock the resourceup(&rmutex); //release for other readersup(&readLock); //Done with trying to access the resource//reading is performeddown(&rmutex); //reserve exit section - avoids race condition with readersreadcount--; //indicate you're leavingif (readcount == 0) //checks if you are last reader leavingup(&resource); //if last, you must release the locked resourceup(&rmutex); //release exit section for other readers}//WRITERvoid writer() {down(&wmutex); //reserve entry section for writers - avoids race conditionswritecount++; //report yourself as a writer enteringif (writecount == 1) //checks if you're first writerdown(&readLock); //if you're first, then you must lock the readers out. Prevent them from trying to enter CSup(&wmutex); //release entry sectiondown(&resource); //reserve the resource for yourself - prevents other writers from simultaneously editing the shared resource//writing is performedup(&resource); //release filedown(&wmutex); //reserve exit sectionwritecount--; //indicate you're leavingif (writecount == 0) //checks if you're the last writerup(&readLock); //if you're last writer, you must unlock the readers. Allows them to try enter CS for readingup(&wmutex); //release exit section}
int readCount; // init to 0; number of readers currently accessing resource// all semaphores initialised to 1Semaphore resourceAccess; // controls access (read/write) to the resourceSemaphore readCountAccess; // for syncing changes to shared variable readCountSemaphore serviceQueue; // FAIRNESS: preserves ordering of requests (signaling must be FIFO)void writer(){down(&serviceQueue); // wait in line to be servicexs//down(&resourceAccess); // request exclusive access to resource//up(&serviceQueue); // let next in line be serviced//writeResource(); // writing is performed////up(&resourceAccess); // release resource access for next reader/writer//}void reader(){down(&serviceQueue); // wait in line to be serviceddown(&readCountAccess); // request exclusive access to readCount//if (readCount == 0) // if there are no readers already reading:down(&resourceAccess); // request resource access for readers (writers blocked)readCount++; // update count of active readers//up(&serviceQueue); // let next in line be servicedup(&readCountAccess); // release access to readCount//readResource(); // reading is performed//down(&readCountAccess); // request exclusive access to readCount//readCount--; // update count of active readersif (readCount == 0) // if there are no readers left:up(&resourceAccess); // release resource access for all//up(&readCountAccess); // release access to readCount}
进程通信
进程同步:控制多个进程按一定顺序执行; 进程通信:进程间传输信息。
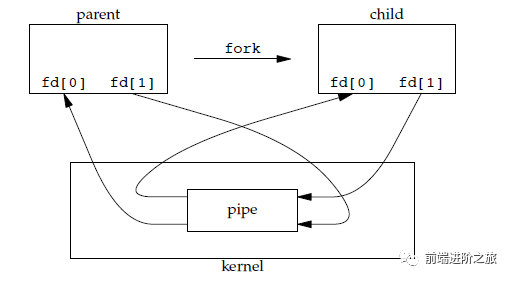
1. 管道
#includeint pipe(int fd[2]);
只支持半双工通信(单向交替传输); 只能在父子进程或者兄弟进程中使用。
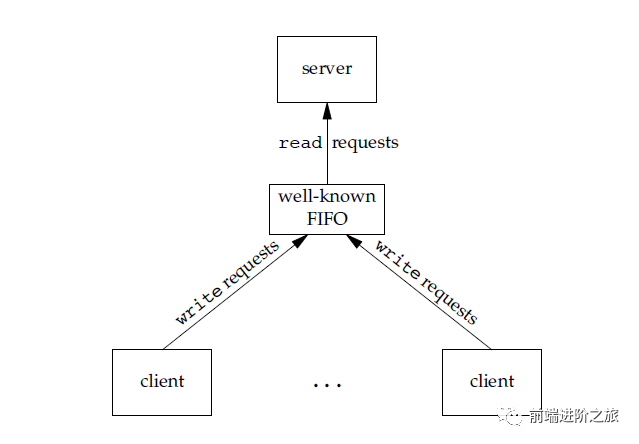
2. FIFO
#includeint mkfifo(const char *path, mode_t mode);int mkfifoat(int fd, const char *path, mode_t mode);
3. 消息队列
消息队列可以独立于读写进程存在,从而避免了 FIFO 中同步管道的打开和关闭时可能产生的困难; 避免了 FIFO 的同步阻塞问题,不需要进程自己提供同步方法; 读进程可以根据消息类型有选择地接收消息,而不像 FIFO 那样只能默认地接收。
4. 信号量
5. 共享存储
6. 套接字
三、内存管理
虚拟内存

分页系统地址映射
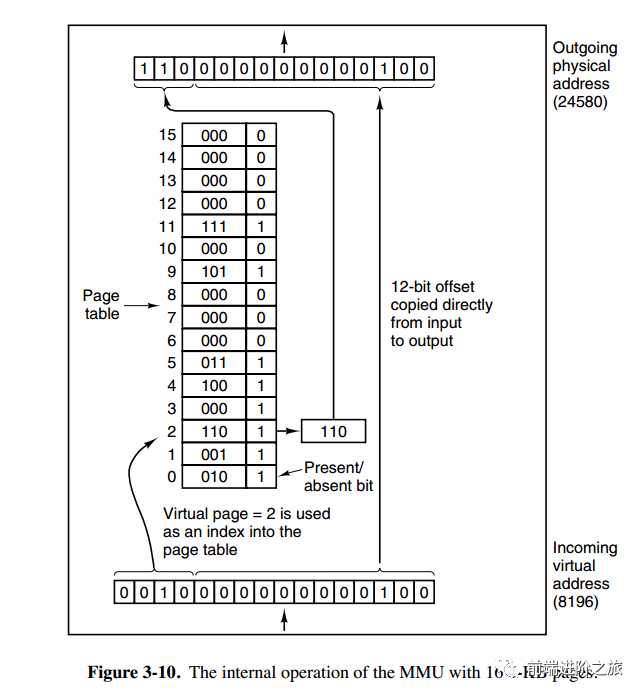
页面置换算法
1. 最佳
OPT, Optimal replacement algorithm
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
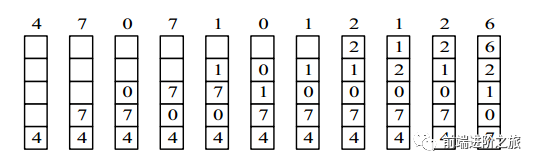
2. 最近最久未使用
LRU, Least Recently Used
4,7,0,7,1,0,1,2,1,2,6
3. 最近未使用
NRU, Not Recently Used
R=0,M=0 R=0,M=1 R=1,M=0 R=1,M=1
4. 先进先出
FIFO, First In First Out
5. 第二次机会算法

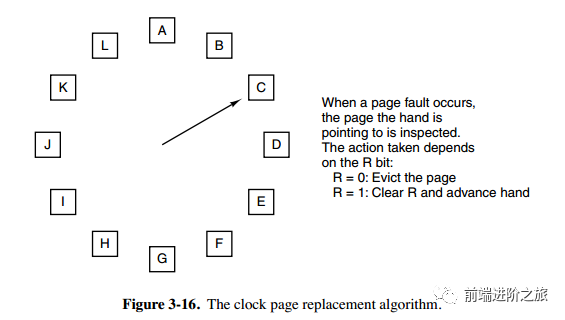
6. 时钟
Clock
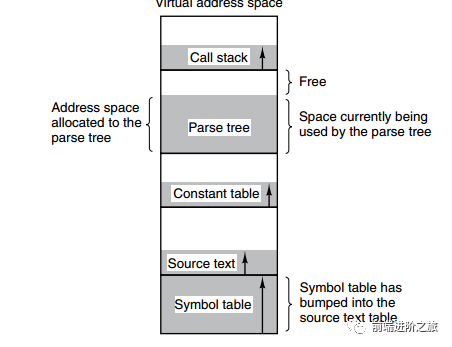
分段
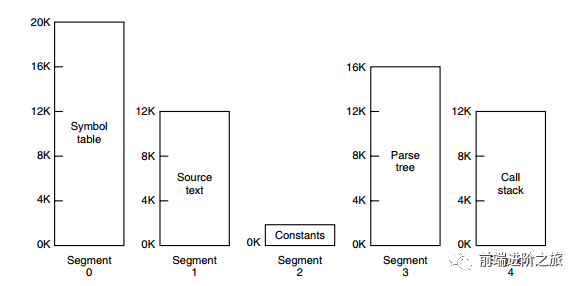
段页式
分页与分段的比较
对程序员的透明性:分页透明,但是分段需要程序员显式划分每个段。
地址空间的维度:分页是一维地址空间,分段是二维的。
大小是否可以改变:页的大小不可变,段的大小可以动态改变。
出现的原因:分页主要用于实现虚拟内存,从而获得更大的地址空间;分段主要是为了使程序和数据可以被划分为逻辑上独立的地址空间并且有助于共享和保护。
四、设备管理
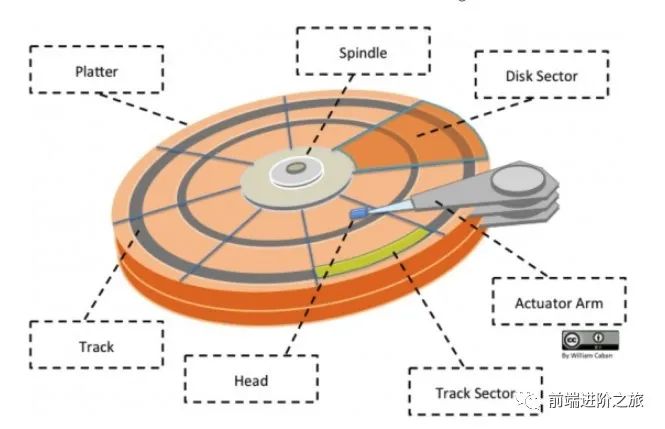
磁盘结构
盘面(Platter):一个磁盘有多个盘面; 磁道(Track):盘面上的圆形带状区域,一个盘面可以有多个磁道; 扇区(Track Sector):磁道上的一个弧段,一个磁道可以有多个扇区,它是最小的物理储存单位,目前主要有 512 bytes 与 4 K 两种大小; 磁头(Head):与盘面非常接近,能够将盘面上的磁场转换为电信号(读),或者将电信号转换为盘面的磁场(写); 制动手臂(Actuator arm):用于在磁道之间移动磁头; 主轴(Spindle):使整个盘面转动。
磁盘调度算法
旋转时间(主轴转动盘面,使得磁头移动到适当的扇区上) 寻道时间(制动手臂移动,使得磁头移动到适当的磁道上) 实际的数据传输时间
1. 先来先服务
FCFS, First Come First Served
2. 最短寻道时间优先
SSTF, Shortest Seek Time First
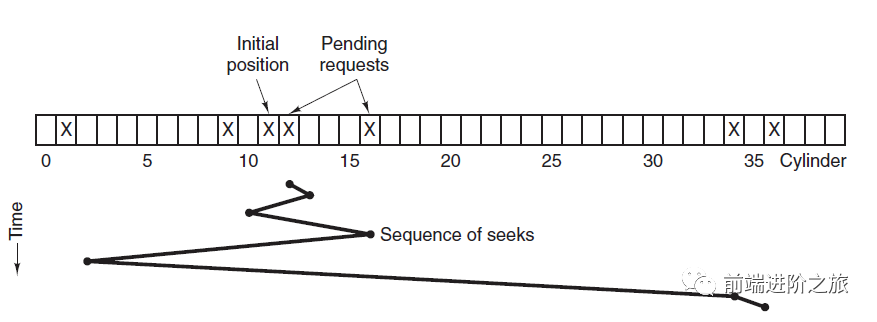
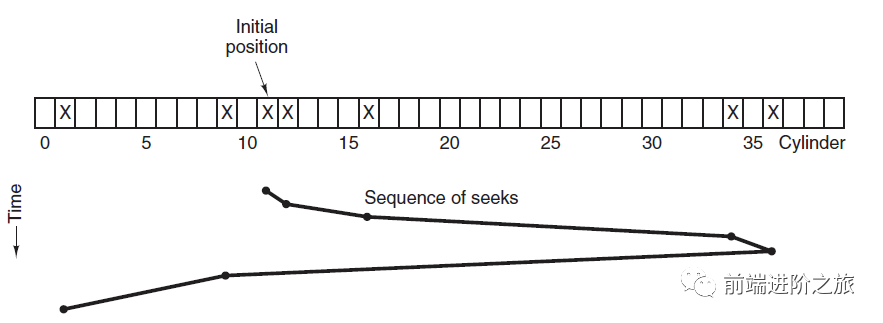
3. 电梯算法
SCAN
五、链接
编译系统
#includeint main(){printf("hello, world\n");return 0;}
gcc -o hello hello.c

预处理阶段:处理以 # 开头的预处理命令; 编译阶段:翻译成汇编文件; 汇编阶段:将汇编文件翻译成可重定位目标文件; 链接阶段:将可重定位目标文件和 printf.o 等单独预编译好的目标文件进行合并,得到最终的可执行目标文件。
静态链接
符号解析:每个符号对应于一个函数、一个全局变量或一个静态变量,符号解析的目的是将每个符号引用与一个符号定义关联起来。 重定位:链接器通过把每个符号定义与一个内存位置关联起来,然后修改所有对这些符号的引用,使得它们指向这个内存位置。
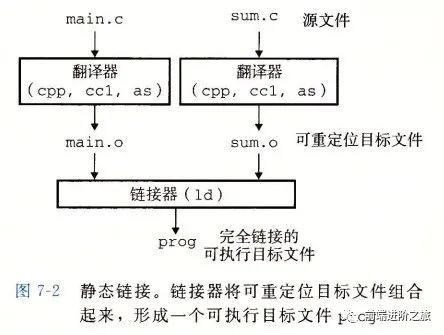
目标文件
可执行目标文件:可以直接在内存中执行; 可重定位目标文件:可与其它可重定位目标文件在链接阶段合并,创建一个可执行目标文件; 共享目标文件:这是一种特殊的可重定位目标文件,可以在运行时被动态加载进内存并链接;
动态链接
当静态库更新时那么整个程序都要重新进行链接; 对于 printf 这种标准函数库,如果每个程序都要有代码,这会极大浪费资源。
在给定的文件系统中一个库只有一个文件,所有引用该库的可执行目标文件都共享这个文件,它不会被复制到引用它的可执行文件中; 在内存中,一个共享库的 .text 节(已编译程序的机器代码)的一个副本可以被不同的正在运行的进程共享。

六、死锁
必要条件
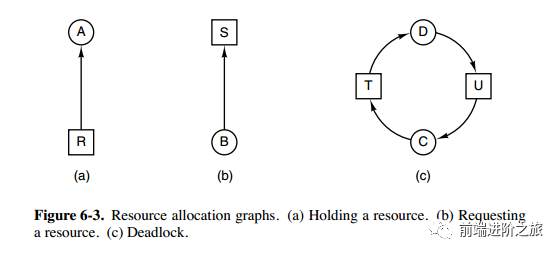
互斥:每个资源要么已经分配给了一个进程,要么就是可用的。 占有和等待:已经得到了某个资源的进程可以再请求新的资源。 不可抢占:已经分配给一个进程的资源不能强制性地被抢占,它只能被占有它的进程显式地释放。 环路等待:有两个或者两个以上的进程组成一条环路,该环路中的每个进程都在等待下一个进程所占有的资源。
处理方法
鸵鸟策略 死锁检测与死锁恢复 死锁预防 死锁避免
鸵鸟策略
死锁检测与死锁恢复
1. 每种类型一个资源的死锁检测
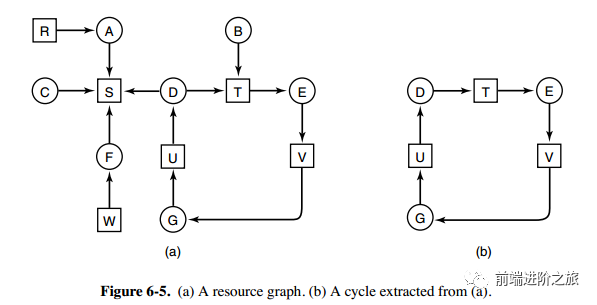
2. 每种类型多个资源的死锁检测

E 向量:资源总量 A 向量:资源剩余量 C 矩阵:每个进程所拥有的资源数量,每一行都代表一个进程拥有资源的数量 R 矩阵:每个进程请求的资源数量
寻找一个没有标记的进程 Pi,它所请求的资源小于等于 A。 如果找到了这样一个进程,那么将 C 矩阵的第 i 行向量加到 A 中,标记该进程,并转回 1。 如果没有这样一个进程,算法终止。
3. 死锁恢复
利用抢占恢复 利用回滚恢复 通过杀死进程恢复
死锁预防
1. 破坏互斥条件
2. 破坏占有和等待条件
3. 破坏不可抢占条件
4. 破坏环路等待
死锁避免
1. 安全状态
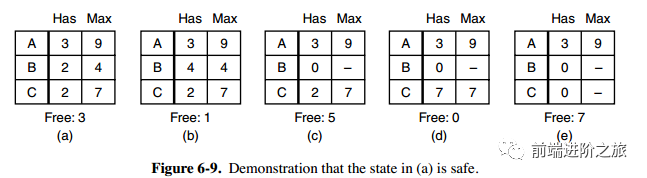
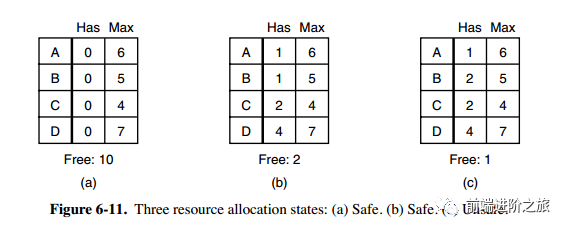
2. 单个资源的银行家算法
3. 多个资源的银行家算法
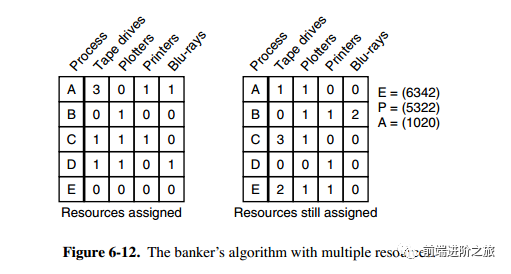
查找右边的矩阵是否存在一行小于等于向量 A。如果不存在这样的行,那么系统将会发生死锁,状态是不安全的。 假若找到这样一行,将该进程标记为终止,并将其已分配资源加到 A 中。 重复以上两步,直到所有进程都标记为终止,则状态时安全的。
评论