
FaceNet人脸识别(三)
上一篇中,我们完成了人脸数据的处理以及制作一个数据处理类,接下来我们就可以来搭建模型,进行训练啦。
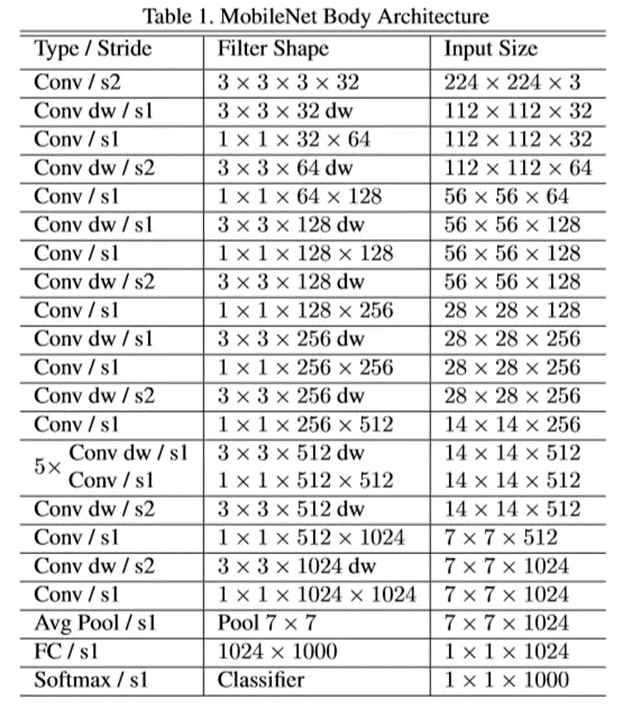
模型我们使用的Google 的MobileNetV2,别问为什么,问就是它快!代码如下,由于tensorflow中自带预训练模型的优势,我们很快就可以搭建出一个模型出来。具体思路为
加载预训练模型MobileNetV2
获取MobileNetV2的global_average_pooling2d层的输出
进行随机失活,并全连接到128层的特征向量
使用批量标准化层将数据标准化
创建基础模型结构
使用normalize以及 softmax 作为模型的输出
normalize层我们使用三元组损失进行训练、softmax我们使用交叉熵损失辅助训练,这是为了模型更快地进行收敛。
返回训练模型以及基础模型
新建一个model.py,具体代码为如下:
from tensorflow.keras.applications import MobileNetV2import tensorflow as tffrom tensorflow.keras.layers import *import tensorflow.keras.backend as Kdef Create_Model(inpt=(160,160,3),train=True,num_classes=10,embedding_size=128, dropout_keep_prob=0.4):inpt = tf.keras.Input(inpt)base_model = MobileNetV2(include_top=True, input_tensor=inpt)out = base_model.get_layer('global_average_pooling2d').outputx = Dropout(1.0 - dropout_keep_prob, name='Dropout')(out)# 全连接层到128# 128x = Dense(embedding_size, use_bias=False, name='Bottleneck')(x)x = BatchNormalization(momentum=0.995, epsilon=0.001, scale=False,name='BatchNorm_Bottleneck')(x)# 创建模型model = tf.keras.Model(inpt, x, name='mobilenet')logits = Dense(num_classes)(model.output)softmax = Activation("softmax", name="Softmax")(logits)normalize = Lambda(lambda x: K.l2_normalize(x, axis=1), name="Embedding")(model.output)combine_model = tf.keras.Model(inpt, [softmax, normalize])x = Lambda(lambda x: K.l2_normalize(x, axis=1), name="Embedding")(model.output)model = tf.keras.Model(inpt, x)if train:return combine_model,model
接着把前面行人重识别中的三元组损失代码拿过来:
import tensorflow as tffrom keras import backend as Kimport osdef triplet_loss(alpha = 0.2, batch_size = 32):def _triplet_loss(y_true, y_pred):anchor, positive, negative = y_pred[:batch_size], y_pred[batch_size:int(2*batch_size)], y_pred[-batch_size:]# 同一张人脸的 欧几里得距离pos_dist = K.sqrt(K.sum(K.square(anchor - positive), axis=-1))# 不同人脸的 欧几里得距离neg_dist = K.sqrt(K.sum(K.square(anchor - negative), axis=-1))# Triplet Lossbasic_loss = pos_dist - neg_dist + alpha #小idxs = tf.where(basic_loss > 0)select_loss = tf.gather_nd(basic_loss,idxs) #大loss = K.sum(K.maximum(basic_loss, 0)) / tf.cast(tf.maximum(1, tf.shape(select_loss)[0]), tf.float32)return lossreturn _triplet_loss
然后就可以编写训练文件进行训练啦,新建一个train.py文件,首先导入依赖:
import osfrom tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateaufrom loaddata import Face_Datasetfrom loss import triplet_lossfrom model import Create_Modelimport tensorflow.keras as kimport tensorflow as tfimport numpy as npimport matplotlib.pyplot as pltimport randomfrom utils import letterbox_image
接着,定义参数与模型:
# 训练参数batch_size=64input_size=(160,160,3)epoch =500init_epoch = 110image_dir = r'D:\data\face_datasets'base_path =os.getcwd()# 实例化数据集train_dataset=Face_Dataset(image_dir,batch_size)test_dataset_2=Face_Dataset(image_dir,1,train=False)# 创建模型model,pred_model = Create_Model(inpt=input_size,num_classes=len(train_dataset.json_key))model.load_weights('logs\ep110-loss0.011.h5')# 编译模型model.compile(loss={'Embedding':triplet_loss(batch_size=batch_size),'Softmax':"categorical_crossentropy"},optimizer=tf.keras.optimizers.Adam(lr=1e-5),metrics={'Softmax':'acc'})#回调函数evaluator = Evaluator()checkpoint_period = ModelCheckpoint(base_path+r'/logs/' + 'ep{epoch:03d}-loss{loss:.3f}.h5',monitor='loss', save_weights_only=False, save_best_only=True, period=1)reduce_lr = ReduceLROnPlateau(monitor='loss', factor=0.1, patience=5, verbose=1)early_stopping = EarlyStopping(monitor='loss', min_delta=0, patience=10, verbose=1)# 开始训练model.fit(train_dataset,steps_per_epoch=train_dataset.__len__(),# validation_data=test_dataset,validation_steps=test_dataset.__len__(),epochs=epoch,initial_epoch=init_epoch,callbacks=[checkpoint_period,reduce_lr,early_stopping,evaluator],workers=6)
接着,为了能够实时查看运行状态,我们还可以自定义一个回调函数,用来在每个训练周期的开始时可视化运行状态,代码如下:
def detect_image(image_1, image_2, model, np_data=True, input_shape=[160, 160, 3]):# ---------------------------------------------------## 对输入图片进行不失真的resize# ---------------------------------------------------#if not np_data:image_1 = letterbox_image(image_1, [input_shape[1], input_shape[0]])image_2 = letterbox_image(image_2, [input_shape[1], input_shape[0]])# ---------------------------------------------------## 进行图片的归一化# ---------------------------------------------------#image_1 = np.asarray(image_1).astype(np.float64) / 255image_2 = np.asarray(image_2).astype(np.float64) / 255photo1 = np.expand_dims(image_1, 0)photo2 = np.expand_dims(image_2, 0)# ---------------------------------------------------## 图片传入网络进行预测# ---------------------------------------------------#output1 = model.predict(photo1)output2 = model.predict(photo2)# ---------------------------------------------------## 计算二者之间的距离# ---------------------------------------------------#l1 = np.sqrt(np.sum(np.square(output1 - output2), axis=-1))return l1# 自定义回调函数class Evaluator(k.callbacks.Callback):def __init__(self):self.accs = []def on_epoch_begin(self, epoch, logs=None):for i in range(3):plt.clf()radmon_int = random.randint(0, test_dataset_2.__len__() - 1)image, _ = test_dataset_2.__getitem__(radmon_int)# print(image[0].shape)same_l1 = detect_image(image[0], image[1], model=pred_model)diff_l2 = detect_image(image[0], image[2], model=pred_model)plt.subplot(1, 3, 1)plt.imshow(np.array(image[0]))plt.subplot(1, 3, 2)plt.imshow(np.array(image[1]))plt.text(-12, -12, 'same:%.3f' % same_l1, ha='center', va='bottom', fontsize=11)plt.subplot(1, 3, 3)plt.imshow(np.array(image[2]))plt.text(-24, -12, 'diff:%.3f' % diff_l2, ha='center', va='bottom', fontsize=11)plt.savefig(base_path + r'/images/test_epoch_%s_%s.png' % (epoch, i))
最后新建两个文件夹images与logs分别用来存放可视化训练状态以及训练时保存的最优模型,就可以进行训练啦。
我们可以看一下可视化的训练状态,第0个周期时我们发现同一个人的距离和不同人的距离还是比较相近的。

到第160 个周期的时候,我们发现同一个人的距离被缩小了,而不同人的距离被拉大了。说明神经网络已经开始可以分辨出不同的人了。

以上就是本文的全部内容了,下一篇我们将会提到适合使用我们已经训练好的模型,感兴趣的同学可以关注一波噢
评论