
教妹学Java第10讲:不可不知的Unicode
hello,小伙伴们,大家好,我是沉默王二,一枚沉默但有趣的程序员。又到了《教妹学 Java》的时间,很开心,很期待,很舒适,有没有?这是《教妹学 Java》专栏的第 10 篇文章,我们来谈谈“Unicode”。
强烈推荐:我在 GitHub 上发现了一个宝藏项目,里面罗列了几百本 Java 经典电子书,包含入门、工具、框架、数据库、并发编程、底层、性能优化、设计模式、计算机网络、操作系统、数据结构与算法、面试、大数据、架构等等方面,应有尽有,需要的小伙伴可以到 GitHub 上自取:
https://github.com/itwanger/JavaBooks
上一篇文章发表后,就有小伙伴留言说“妹妹大一就开始学习 Java 了,有点厉害。”我只能说从娃娃抓起,嘿嘿。专栏名你们也看到了,对,初衷真的是教我妹学 Java。不过,我相信小伙伴们在阅读的过程中也一定能感受到思维的乐趣,还能真的学习到知识。

再次强调,《教妹学 Java》专栏面向的是零基础的 Java 学习者,我希望这个专栏能够带领 Java 初学者轻松迈进编程世界的大门,并且能够读写编写出规范、有用的 Java 代码。同时,为后续的深入学习打下坚实的基础。

我妹(亲妹)今年上大学了,学的计算机编程,没成想,她的一名老师竟然是我的读者,我妹是又惊喜又恐慌,惊喜是她哥我的读者群体还挺广泛的嘛,恐慌的是万一学不好岂不是很丢他哥的脸?但我相信她一定能学好!
------我是正儿八经的分割线--------
“二哥,上一篇文章中提到了 Unicode,说 Java 中的
char 类型之所以占 2 个字节,是因为 Java 使用的是 Unicode 字符集而不是 ASCII 字符集,我有点迷,想了解一下,能细致给我说说吗?”
“当然没问题啊,三妹。”
1)ASCII
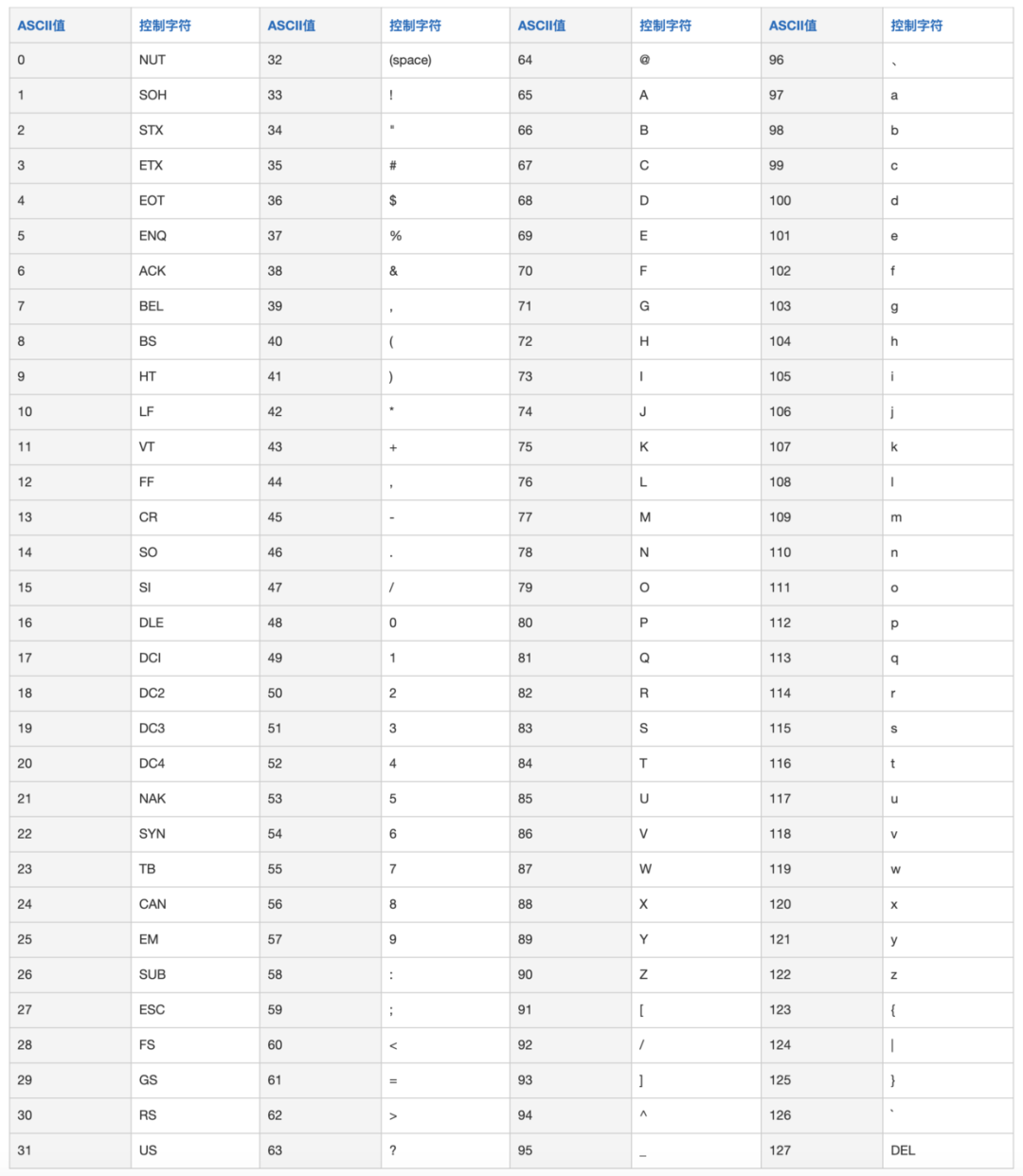
对于计算机来说,只认 0 和 1,所有的信息最终都是一个二进制数。一个二进制数要么是 0,要么是 1,所以 8 个二进制数放在一起(一个字节),就会组合出 256 种状态,也就是 2 的 8 次方(2^8),从 00000000 到 11111111。
ASCII 码由电报码发展而来,第一版标准发布于 1963 年,最后一次更新则是在1986 年,至今为止共定义了 128 个字符。其中 33 个字符无法显示在一般的设备上,需要用特殊的设备才能显示。
ASCII 码的局限在于只能显示 26 个基本拉丁字母、阿拉伯数字和英式标点符号,因此只能用于显示现代美国英语,对于其他一些语言则无能无力,比如在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。
PS:拉丁字母(也称为罗马字母)是多数欧洲语言采用的字母系统,是世界上最通行的字母文字系统,是罗马文明的成果之一。
虽然名称上叫作拉丁字母,但拉丁文中并没有用 J、U 和 W 这三个字母。
在我们的印象中,可能说拉丁字母多少有些陌生,说英语字母可能就有直观的印象了。

PPS:阿拉伯数字,我们都很熟悉了。

但是,阿拉伯数字并非起源于阿拉伯,而是起源于古印度。学过历史的我们应该有一些印象,阿拉伯分布于西亚和北非,以阿拉伯语为主要语言,以伊斯兰教为主要信仰。
处在这样的地理位置,做起东亚和欧洲的一些生意就很有优势,于是阿拉伯数字就由阿拉伯人传到了欧洲,因此得名。
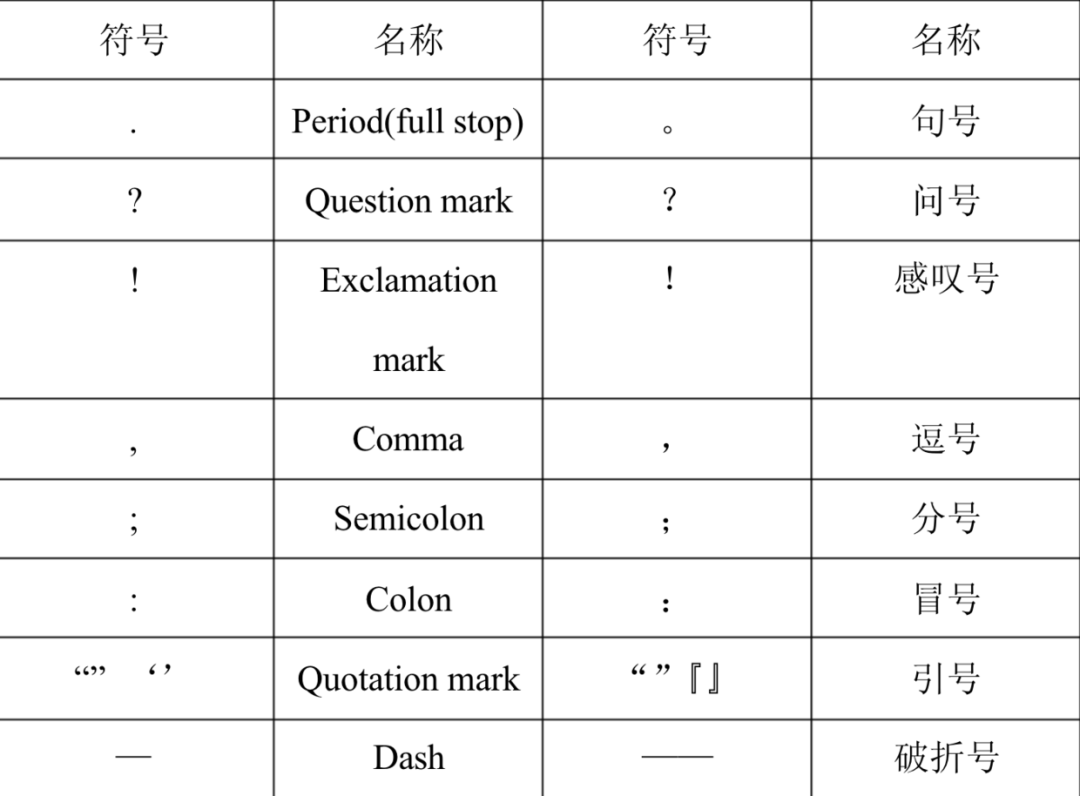
PPPS:英式标点符号,也叫英文标点符号,和中文标点符号很相近。标点符号是辅助文字记录语言的符号,是书面语的组成部分,用来表示停顿、加强语气等。
英文标点符号在 16 世纪时,分为朗诵学派和句法学派,主要由古典时期的希腊文和拉丁文演变而来,在 17 世纪后进入稳定阶段。俄文的标点符号依据希腊文而来,到了 18 世纪后也采用了英文标点符号。
在很多人的印象中,古文是没有标点符号的,但管锡华博士研究指出,中国早在先秦时代就有标点符号了,后来融合了一些英文标点符号后,逐渐形成了现在的中文标点符号。
2)Unicode
这个世界上,除了英语,还有法语、葡萄牙语、西班牙语、德语、俄语、阿拉伯语、韩语、日语等等等等。ASCII 码用来表示英语是绰绰有余的,但其他这些语言就没办法了。
像我们的母语,博大精深,汉字的数量很多很多,东汉的《说文解字》收字 9353 个,清朝《康熙字典》收字 47035 个,当代的《汉语大字典》收字 60370 个。1994 年中华书局、中国友谊出版公司出版的《中华字海》收字 85568 个。
PS:常用字大概 2500 个,次常用字 1000 个。
一个字节只能表示 256 种符号,所以如果拿 ASCII 码来表示汉字的话,是远远不够用的,那就必须要用更多的字节。简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,理论上最多可以表示 256 x 256 = 65536 个符号。
要知道,世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
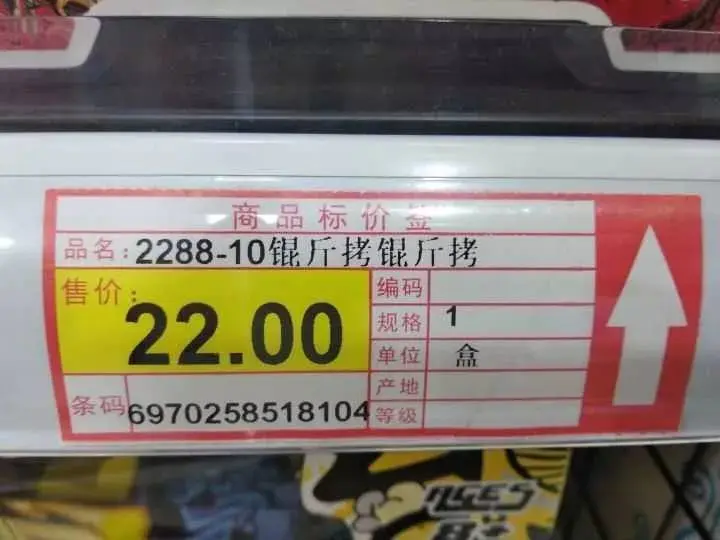
PPS:这“锟斤拷”价格挺公道的啊!!!(逃
如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会彻底消失。
这个艰巨的任务有谁来完成呢?Unicode,中文译作万国码、国际码、统一码、单一码,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 至今仍在不断增修,每个新版本都会加入更多新的字符。目前最新的版本为 2020 年 3 月公布的 13.0,收录了 13 万个字符。

Unicode 是一个很大的集合,现在的规模可以容纳 100 多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母 Ain,U+0041 表示英语的大写字母 A,U+4E25 表示汉字严。
具体的符号对应表,可以查询 unicode.org,或者专门的汉字对应表。
曾有人这样说:
Unicode 支持的字符上限是 65536 个,Unicode 字符必须占两个字节。
但这是一种误解,记住,Unicode 只是一个用来映射字符和数字的标准。它对支持字符的数量没有限制,也不要求字符必须占两个、三个或者其它任意数量的字节,所以它可以无穷大。
Unicode 虽然统一了全世界字符的编码,但没有规定如何存储。如果统一规定的话,每个符号就要用 3 个或 4 个字节表示,因为 2 个字节只能表示 65536 个,根本表示不全。
那怎么办呢?
UTF(Unicode Transformation Formats,Unicode 的编码方式)来了!最常见的就是 UTF-8 和 UTF-16。
在 UTF-8 中,0-127 号的字符用 1 个字节来表示,使用和 ASCII 相同的编码。只有 128 号及以上的字符才用 2 个、3 个或者 4 个字节来表示。
如果只有一个字节,那么最高的比特位为 0;如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
0xxxxxxx:一个字节;110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1);1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1);11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
也就是说,UTF-8 是一种可变长度的编码方式——这是它的优势也是劣势。
怎么讲呢?优势就是它包罗万象,劣势就是浪费空间。举例来说吧,UTF-8 采用了 3 个字节(256256256=16777216)来编码常用的汉字,但常用的汉字没有这么多,这对于计算机来说,就是一种严重的资源浪费。
基于这样的考虑,中国国家标准总局于 1980 年发布了 GB 2312 编码,即中华人民共和国国家标准简体中文字符集。GB 2312 标准共收录 6763 个汉字(2 个字节就够用了),其中一级汉字 3755 个,二级汉字 3008 个;同时收录了包括拉丁字母、希腊字母、日文平假名及片假名字母、俄语西里尔字母在内的 682 个字符。
GB 2312 的出现,基本满足了汉字的计算机处理需求。对于人名、古汉语等方面出现的罕用字和繁体字,GB 2312 不能处理,就有了 GBK(K 为“扩展”的汉语拼音(kuòzhǎn)第一个声母)。
来看一段代码:
public class Demo {
public static void main(String[] args) {
String wanger = "沉默王二";
byte[] bytes = wanger.getBytes(Charset.forName("GBK"));
String result = new String(bytes, Charset.forName("UTF-8"));
System.out.println(result);
}
}
先用 GBK 编码,再用 UTF-8 解码,程序会输出什么呢?
��Ĭ����
嘿嘿,乱码来了!在 Unicode 中,� 是一个特殊的符号,它用来表示无法显示,它的十六进制是 0xEF 0xBF 0xBD。那么两个 �� 就是 0xEF 0xBF 0xBD 0xEF 0xBF 0xBD,如果用 GBK 进行解码的话,就是大名鼎鼎的“锟斤拷”。
可以通过代码来验证一下:
// 输出 efbfbdefbfbd
System.out.println(HexUtil.encodeHex("��", Charset.forName("UTF-8")));
// 借助 hutool 转成二进制
byte[] testBytes = HexUtil.decodeHex("efbfbdefbfbd");
// 使用 GBK 解码
String testResult = new String(testBytes, Charset.forName("GBK"));
// 输出锟斤拷
System.out.println(testResult);
PPPS:hutool 的使用方法可以参照我的另外一篇文章。
所以,以后再见到锟斤拷,第一时间想到 UTF-8 和 GBK 的转换问题准没错。
UTF-16 使用 2 个或者 4 个字节来存储字符。
对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储。
对于 Unicode 编号范围在 10000 ~ 10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
3)char
搞清楚了 Unicode 之后,再回头来看 char 为什么是两个字节的问题,就很容易搞明白了。
在 Unicode 的设计之初,人们认为两个字节足以对世界上各种语言的所有字符进行编码,在 1991 年发布的 Unicode 1.0 中,仅用了 65536 个代码值中不到一半的部分。
所以,Java 决定采用 16 位的 Unicode 字符集(诞生于 90 年代)。也就是说,当时的 char 类型可以表示任意一个 Unicode 字符。
但是,不可避免的事情发生了,Unicode 收录的字符越来越多,超过了 65536 个(2 个字节的最大表示范围)。超过的部分怎么办呢?只能用两个 char 来表示了。
这个 ? 字符很特殊,Unicode 编码是 U+10437,它就无法使用一个 char 来表示,当你尝试用 char 来表示时,它会被 IDEA 转成 UTF-16 十六进制字符代码 \uD801\uDC37(与此同时,编译器会提醒你最好把它声明成 String 类型)。

也就是说,在 Java 中,char 会占用两个字节,超出 char 的承受范围('\u0000'(0)和 '\uffff'(65,535))的字符,都将无法表示。
“好了,三妹,关于 Unicode 就先说这么多吧,你是不是已经清楚了?”转动了一下僵硬的脖子后,我对三妹说。
“差不多,二哥,我觉得还得再消化会。”
这是《教妹学 Java》专栏的第 10 篇文章,能看到这里的小伙伴都是最帅的,最美的,升职加薪就是你了?。

写这个专栏的初衷就是为了帮助那些零基础学 Java,或者自学 Java 感觉特别痛苦,特别难入门的小伙伴。
另外,我还创建了一些「技术交流群」,群里氛围很不错,有不少小伙伴会分享一些校招或者社招经验,更重要的是,群里时不时会有「红包」等福利,当然,群里不允许任何形式的广告。扫描下方的二维码,回复「加群」即可。
示例代码已经同步到 GitHub,地址为 github.com/itwanger,也可以点击阅读原文进行跳转,欢迎 star。