
使用 Node.js 对文本内容分词和关键词抽取
(给程序员成长指北加星标,提升前端技能)
转自:掘金 - 十年踪迹
在讨论技术前先卖个萌,吃货的世界你不懂~~
众成翻译的文章有 tag,用户可以基于 tag 来快速筛选感兴趣的文章,文章也可以依照 tag 关联来进行相关推荐。但是现在众成翻译的 tag 是在推荐文章的时候设置的,都是英文的,而且人工设置难免不规范和不完全。虽然发布文章后也可以人工编辑,但是我们也不能指望用户或管理员能够时时刻刻编辑出恰当的 tag,所以我们需要用工具来自动生成 tag。
在现在开源的分词工具里面,jieba是一个功能强大性能优越的分词组件,更幸运地是,它有 node 版本。
nodejieba 的安装和使用十分简单:
npm install nodejieba
var nodejieba = require("nodejieba");
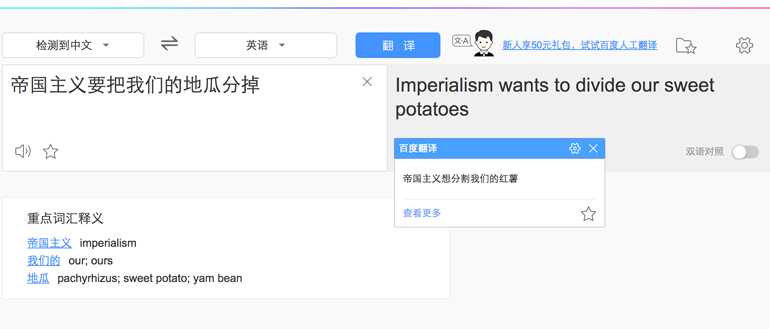
var result = nodejieba.cut("帝国主义要把我们的地瓜分掉");
console.log(result);
//[ '帝国主义', '要', '把', '我们', '的', '地', '瓜分', '掉' ]
result = nodejieba.cut('土地,俺老孙的金箍棒在哪里?');
console.log(result);
//[ '土地', ',', '俺', '老', '孙', '的', '金箍棒', '在', '哪里', '?' ]
result = nodejieba.cut('大圣,您的金箍棒就棒在特别配您的头型!');
console.log(result);
//[ '大圣',',','您','的','金箍棒','就','棒','在','特别','配','您','的','头型','!' ]
我们可以载入自己的字典,在字典里给每个词分别设置权重和词性:
编辑 user.uft8
地瓜 9999 n
金箍 9999 n
棒就棒在 9999
然后通过 nodejieba.load 加载字典。
var nodejieba = require("nodejieba");
nodejieba.load({
userDict: './user.utf8',
});
var result = nodejieba.cut("帝国主义要把我们的地瓜分掉");
console.log(result);
//[ '帝国主义', '要', '把', '我们', '的', '地瓜', '分', '掉' ]
result = nodejieba.cut('土地,俺老孙的金箍棒在哪里?');
console.log(result);
//[ '土地', ',', '俺', '老', '孙', '的', '金箍棒', '在', '哪里', '?' ]
result = nodejieba.cut('大圣,您的金箍棒就棒在特别配您的头型!');
console.log(result);
//[ '大圣', ',', '您', '的', '金箍', '棒就棒在', '特别', '配', '您', '的', '头型', '!' ]
除了分词以外,我们可以利用 nodejieba 提取关键词:
const content = `
HTTP、HTTP/2与性能优化
本文的目的是通过比较告诉大家,为什么应该从HTTP迁移到HTTPS,以及为什么应该添加到HTTP/2的支持。在比较HTTP和HTTP/2之前,先看看什么是HTTP。
什么是HTTP
HTTP是在万维网上通信的一组规则。HTTP属于应用层协议,跑在TCP/IP层之上。用户通过浏览器请求网页时,HTTP负责处理请求并在Web服务器与客户端之间建立连接。
有了HTTP/2,不使用雪碧图、压缩、拼接,也可以提升性能。然而,这不代表不应该使用这些技术。不过这已经清楚表明了我们从HTTP/1.1移动到HTTP/2的必要性。
`;
const nodejieba = require("nodejieba");
const result = nodejieba.extract(content, 20);
console.log(result);
输出的结果类似下面这样:
[ { word: 'HTTP', weight: 140.8704516850025 },
{ word: '请求', weight: 14.23018001394 },
{ word: '应该', weight: 14.052171126120001 },
{ word: '万维网', weight: 12.2912397395 },
{ word: 'TCP', weight: 11.739204307083542 },
{ word: '1.1', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '雪碧图', weight: 11.739204307083542 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: 'IP', weight: 11.739204307083542 },
{ word: '应用层', weight: 11.2616203224 },
{ word: '客户端', weight: 11.1926274509 },
{ word: '浏览器', weight: 10.8561552143 },
{ word: '拼接', weight: 9.85762638414 },
{ word: '比较', weight: 9.5435285574 },
{ word: '网页', weight: 9.53122979951 },
{ word: '服务器', weight: 9.41204128224 },
{ word: '使用', weight: 9.03259988558 },
{ word: '必要性', weight: 8.81927328699 },
{ word: '添加', weight: 8.0484751722 } ]
我们添加一些新的关键词到字典里:
性能
HTTP/2
输出结果如下:
[ { word: 'HTTP', weight: 105.65283876375187 },
{ word: 'HTTP/2', weight: 58.69602153541771 },
{ word: '请求', weight: 14.23018001394 },
{ word: '应该', weight: 14.052171126120001 },
{ word: '性能', weight: 12.61259281884 },
{ word: '万维网', weight: 12.2912397395 },
{ word: 'IP', weight: 11.739204307083542 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: '1.1', weight: 11.739204307083542 },
{ word: 'TCP', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '雪碧图', weight: 11.739204307083542 },
{ word: '应用层', weight: 11.2616203224 },
{ word: '客户端', weight: 11.1926274509 },
{ word: '浏览器', weight: 10.8561552143 },
{ word: '拼接', weight: 9.85762638414 },
{ word: '比较', weight: 9.5435285574 },
{ word: '网页', weight: 9.53122979951 },
{ word: '服务器', weight: 9.41204128224 },
{ word: '使用', weight: 9.03259988558 } ]
在这个基础上,我们采用白名单的方式过滤出一些可以作为 tag 的词:
const content = `
HTTP、HTTP/2与性能优化
本文的目的是通过比较告诉大家,为什么应该从HTTP迁移到HTTPS,以及为什么应该添加到HTTP/2的支持。在比较HTTP和HTTP/2之前,先看看什么是HTTP。
什么是HTTP
HTTP是在万维网上通信的一组规则。HTTP属于应用层协议,跑在TCP/IP层之上。用户通过浏览器请求网页时,HTTP负责处理请求并在Web服务器与客户端之间建立连接。
有了HTTP/2,不使用雪碧图、压缩、拼接,也可以提升性能。然而,这不代表不应该使用这些技术。不过这已经清楚表明了我们从HTTP/1.1移动到HTTP/2的必要性。
`;
const nodejieba = require("nodejieba");
nodejieba.load({
userDict: './user.utf8',
});
const result = nodejieba.extract(content, 20);
const tagList = ['HTTPS', 'HTTP', 'HTTP/2', 'Web', '浏览器', '性能'];
console.log(result.filter(item => tagList.indexOf(item.word) >= 0));
最后得到:
[ { word: 'HTTP', weight: 105.65283876375187 },
{ word: 'HTTP/2', weight: 58.69602153541771 },
{ word: '性能', weight: 12.61259281884 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '浏览器', weight: 10.8561552143 } ]
这就是我们想要的结果。
以上就是分词库 nodejieba 基本的使用方法,在将来我们可以利用它对众成翻译发布的译文自动分析添加相应的 tag,以为各位译者和读者提供更好的用户体验。
❤️爱心三连击 1.看到这里了就点个在看支持下吧,你的「点赞,在看」是我创作的动力。
2.关注公众号
程序员成长指北,回复「1」加入高级前端交流群!「在这里有好多 前端 开发者,会讨论 前端 Node 知识,互相学习」!3.也可添加微信【ikoala520】,一起成长。
“在看转发”是最大的支持
评论