
go-zero微服务实战系列(六、缓存一致性保证)
只要我们使用缓存,就必然会面对缓存和数据库间的一致性问题。如果缓存中的数据和数据库的数据不一致,那么业务应用从缓存中读取的数据就不是最新的数据,对业务的影响可想而知。比如我们把商品的库存数据存在缓存中,如果缓存中库存数据不对,那么可能就会影响下单操作,这是业务上很难接受的。本篇文章我们来一起聊一聊缓存的一致性问题。
如何解决缓存不一致
先删缓存再更新数据库
假设线程A删除缓存后,还没来得及更新数据库,这时候线程B开始读数据,线程B发现缓存缺失就只能去读数据库,等到线程B从数据库中读取完数据回塞缓存后,线程A才开始更新数据库,此时,缓存中的数据是旧值,而数据库中是最新值,两者已经不一致了。
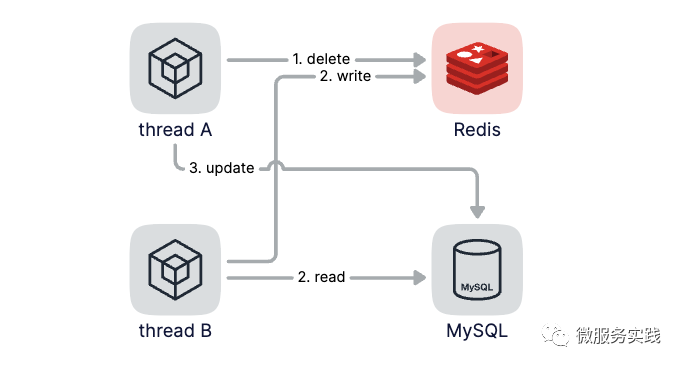
这种场景的解决方案是在线程A更新完数据库的值后,可以让它sleep一小段时间,再进行一次缓存删除操作,之所以要加上sleep的一段时间,就是为了让线程B能够先从数据库读取出数据然后再把缓存miss的数据回塞到缓存,然后线程A再进行删除。所以线程A的sleep时间就需要大于线程B读取数据再写入缓存的时间。这个时间是多少呢?这个是需要我们在业务中加入打点监控来统计的,根据这个统计值来估算该时间。这样一来,其他线程读取数据时,会发现缓存缺失,就会从数据库中读取最新的值。我们把这种模型叫做 "延时双删"。
先更新数据库再删除缓存
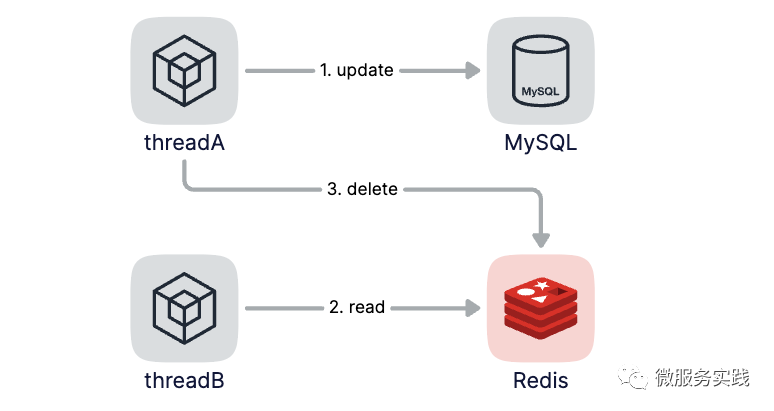
如果线程A更新了数据库中的值,但还没来得及删除缓存中的值,线程B这时候开始读取数据,此时,线程B查询缓存时,命中了缓存,就会直接使用缓存中的值,该值为旧值。不过在这种场景下,如果并发请求量不高的话,其实基本上不会有线程读到旧值,而且线程A更新完数据库后,删除缓存是非常快的操作,所以,这种情况总体对业务影响较小。一般在生产环境中,也推荐大家采用该模式。
重试机制
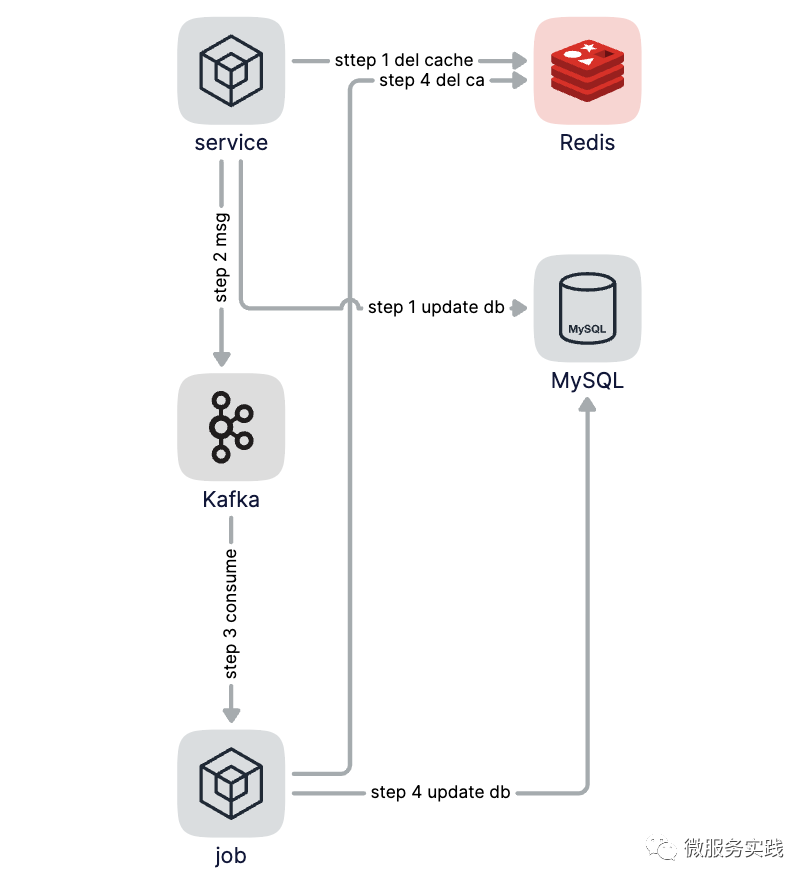
可以把要删除的缓存值或者要更新的数据库的值放到消息队列中,当应用没能够成功地删除缓存或者是更新数据库的值的时候,可以从消息队列中消费这些值,这里消费消息队列的服务叫job,然后再次进行删除或者更新,起到一个兜底补偿的作用,以此来保证最终的一致性。
如果能够成功地删除或更新,就需要把这些值从消息队列中去除,以免重复操作,此时,我们也可以保证数据库和缓存数据的一致了,否则的话,我们还需要再次进行重试,如果重试超过一定次数还是失败,这时候一般都需要记录错误日志或者发送告警通知。
并发读写
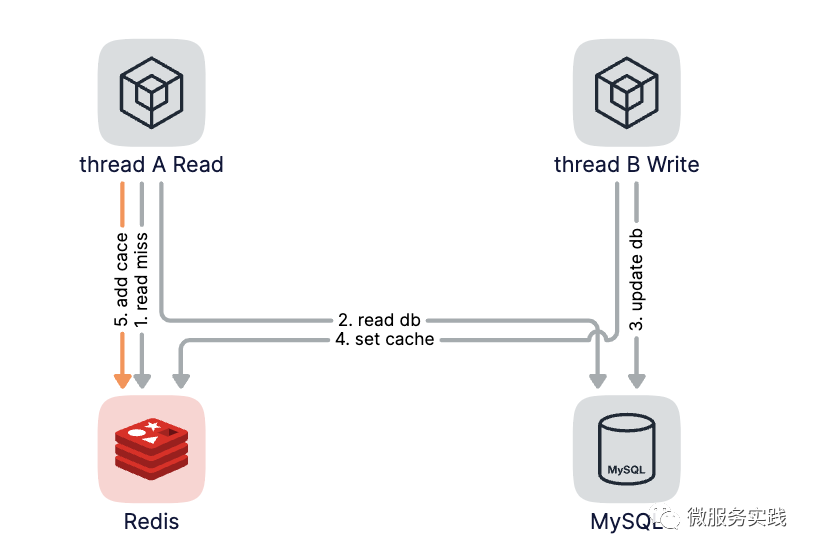
首先第一步线程A读取缓存,这时候缓存没有命中,由于使用的是cache aside这种模式,所以接下来第二步线程A会去读数据库,这个时候线程B更新数据库,更新完数据库后通过set cache更新了缓存,最后第五步线程A把从数据库读到的值通过set cache也更新了缓存,但是这时候线程A中的数据已经是脏数据了,由于第四步和第五步都是设置缓存,导致写入的值相互覆盖,并且操作的顺序具有不确定性,从而导致了缓存不一致情况的发生。
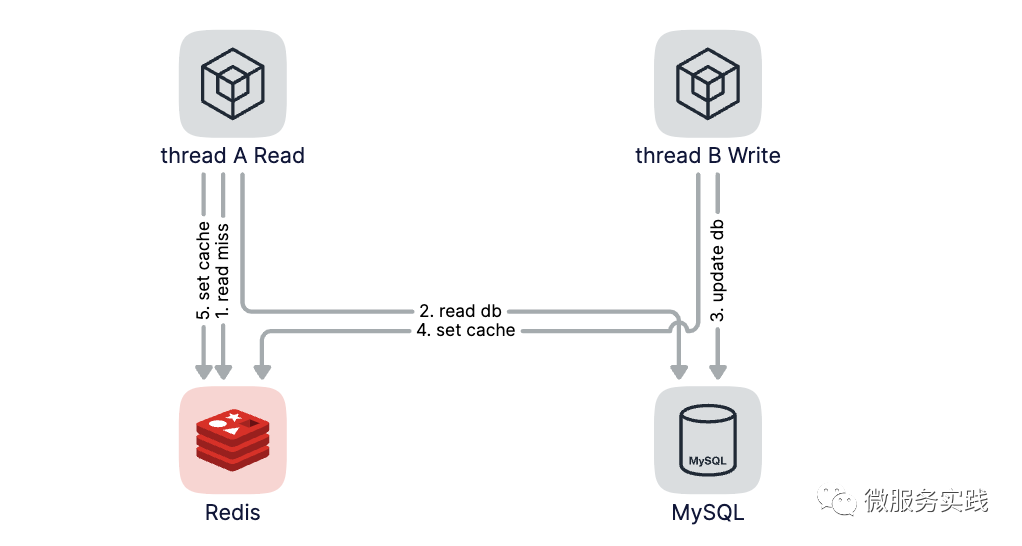
怎么解决这个问题呢?其实非常地简单,我们只需要把第五步的set cache操作替换成add cache即可,add cache即setnx操作,只有缓存不存在的时候才会成功写入,相当于加了优先级,即更新数据库后的更新缓存优先级更高,而读数据库后回塞缓存的优先级较低,从而保证写操作的最新数据不会被读操作的回塞数据覆盖。
结束语
本篇文章说明了在使用缓存时最常遇见的一个问题,也就是缓存和数据库不一致的问题,针对这个问题我们列举了一些可能导致不一致的场景以及对应场景的解决方案,特别地,对于job异步补偿的场景我们可以使用set操作来强行覆盖缓存,保证缓存的更新为最新的数据,而对于读数据库回塞缓存的操作我们一般使用add来更新缓存。
希望本篇文章对你有所帮助,谢谢。
代码仓库: https://github.com/zhoushuguang/lebron
推荐阅读