
Nodejs 整体架构与九个核心模块实现
作者介绍:陈跃标,ByteDance Web Infra 团队成员,目前主要负责 Node.js 基础架构方向的工作
本文内容主要分为两大部分,第一部分是 Node.js 的基础和架构,第二部分是 Node.js 核心模块的实现。
一 Node.js 基础和架构 Node.js 的组成 Node.js 代码架构 Node.js 启动过程 Node.js 事件循环 二 Node.js 核心模块的实现 进程和进程间通信 线程和线程间通信 Cluster Libuv 线程池 信号处理 文件 TCP UDP DNS
1. Nodejs 组成
Node.js 主要由 V8、Libuv 和第三方库组成:
Libuv:跨平台的异步 IO 库,但它提供的功能不仅仅是 IO,还包括进程、线程、信号、定时器、进程间通信,线程池等。 第三方库:异步 DNS 解析( cares )、HTTP 解析器(旧版使用 http_parser,新版使用 llhttp)、HTTP2 解析器( nghttp2 )、 解压压缩库( zlib )、加密解密库( openssl )等等。 V8:实现 JS 解析、执行和支持自定义拓展,得益于 V8 支持自定义拓展,才有了 Node.js。
2. Node.js代码架构
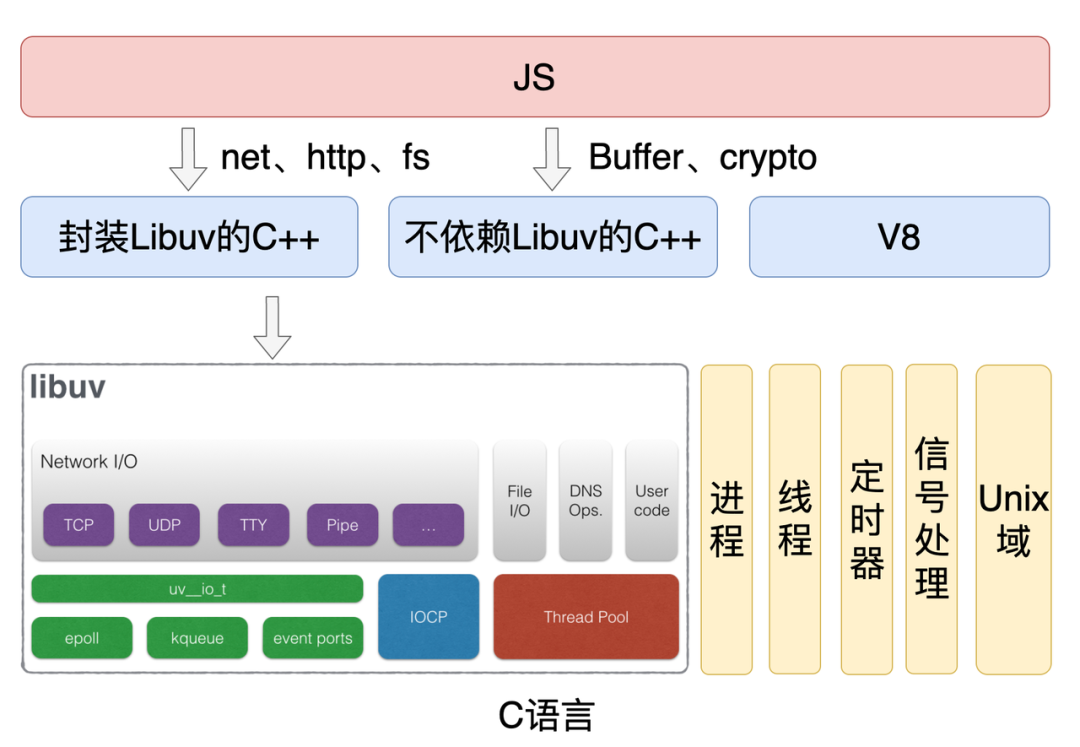
上图是 Node.js 的代码架构,Node.js的代码主要分为 JS、C++、C 三种:
JS 是我们平时使用的那些模块(http/fs)。 C++ 代码分为三个部分,第一部分是封装了 Libuv 的功能,第二部分则是不依赖于 Libuv ( crypto 部分 API 使用了 Libuv 线程池),比如 Buffer 模块,第三部分是 V8 的代码。 C 语言层的代码主要是封装了操作系统的功能,比如 TCP、UDP。
了解了 Node.js 的组成和代码架构后,我们看看 Node.js 启动的过程都做了什么。
3. Node.js启动过程
3.1 注册 C++ 模块

首先 Node.js 会调用 registerBuiltinModules 函数注册 C++ 模块,这个函数会调用一系列 registerxxx 的函数,我们发现在 Node.js 源码里找不到这些函数,因为这些函数是在各个 C++ 模块中,通过宏定义实现的,宏展开后就是上图黄色框的内容,每个 registerxxx 函数的作用就是往 C++ 模块的链表了插入一个节点,最后会形成一个链表。
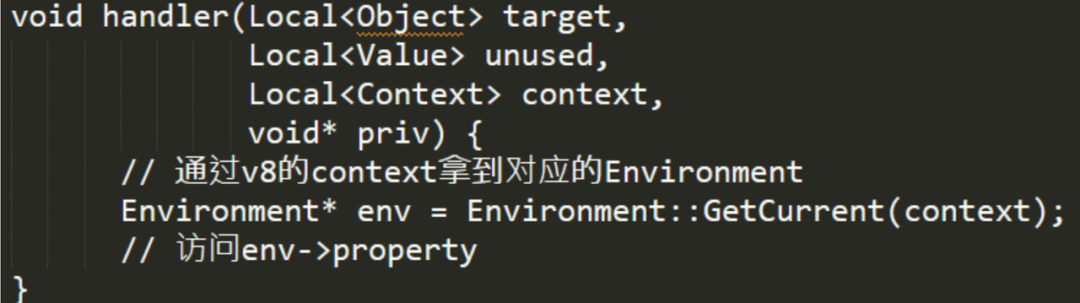
那么 Node.js 里是如何访问这些 C++ 模块的呢?在 Node.js 中,是通过 internalBinding 访问 C++ 模块的,internalBinding 的逻辑很简单,就是根据模块名从模块队列中找到对应模块。但是这个函数只能在 Node.js 内部使用,不能在用户 JS 模块使用,用户可以通过 process.binding 访问 C++ 模块。
3.2 Environment 对象和绑定 Context
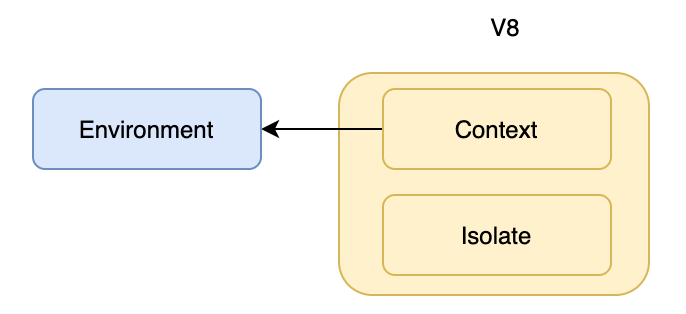
注册完 C++ 模块后就开始创建 Environment 对象,Environment 是 Node.js 执行时的环境对象,类似一个全局变量的作用,他记录了 Node.js 在运行时的一些公共数据。创建完 Environment 后,Node.js 会把该对象绑定到 V8 的 Context 中,为什么要这样做呢?主要是为了在 V8 的执行上下文里拿到 env 对象,因为 V8 中只有 Isolate、Context 这些对象,如果我们想在 V8 的执行环境中获取 Environment 对象的内容,就可以通过 Context 获取 Environment 对象。
3.3 初始化模块加载器
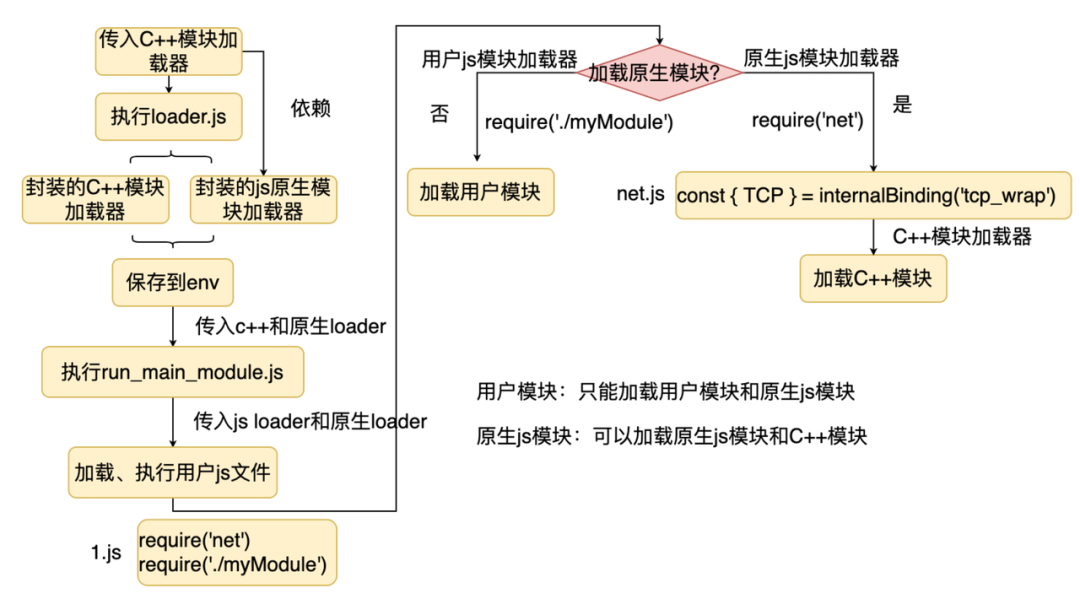
Node.js 首先传入 C++ 模块加载器,执行 loader.js,loader.js 主要是封装了 C++ 模块加载器和原生 JS 模块加载器,并保存到 env 对象中。 接着传入 C++ 和原生 JS 模块加载器,执行 run_main_module.js。 在 run_main_module.js 中传入普通 JS 和原生 JS 模块加载器,执行用户的 JS。
假设用户 JS 如下:
require('net') require('./myModule')
分别加载了一个用户模块和原生 JS 模块,我们看看加载过程,执行 require 的时候:
Node.js 首先会判断是否是原生 JS 模块,如果不是则直接加载用户模块,否则,会使用原生模块加载器加载原生 JS 模块。 加载原生 JS 模块的时候,如果用到了 C++ 模块,则使用 internalBinding 去加载。
3.4 执行用户代码,Libuv 事件循环
接着 Node.js 就会执行用户的 JS,通常用户的 JS 会给事件循环生产任务,然后就进入了事件循环系统,比如我们 listen 一个服务器的时候,就会在事件循环中新建一个 TCP handle。Node.js 就会在这个事件循环中一直运行。
net.createServer(() => {}).listen(80)
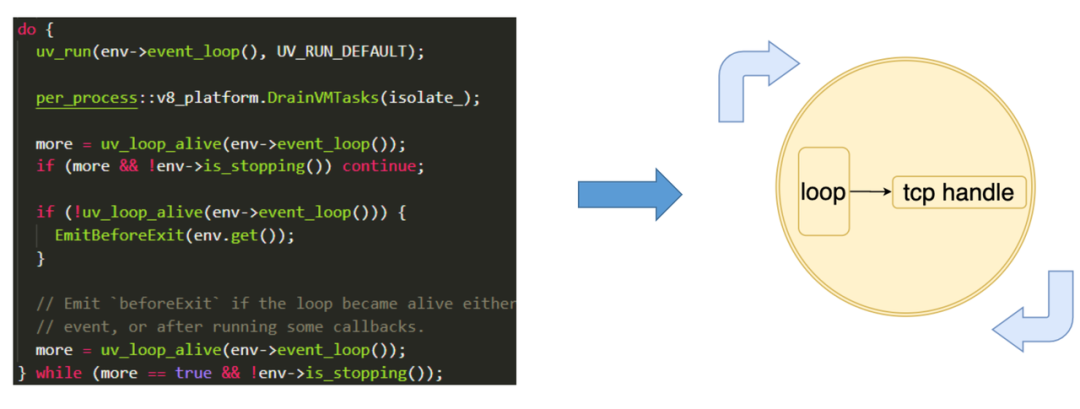
4. 事件循环
下面我们看一下事件循环的实现。事件循环主要分为 7 个阶段,timer 阶段主要是处理定时器相关的任务,pending 阶段主要是处理 Poll IO 阶段回调里产生的回调,check、prepare、idle 阶段是自定义的阶段,这三个阶段的任务每次事件序循环都会被执行,Poll IO 阶段主要是处理网络 IO、信号、线程池等等任务,closing 阶段主要是处理关闭的 handle,比如关闭服务器。

timer 阶段: 用二叉堆实现,最快过期的在根节点。 pending 阶段:处理 Poll IO 阶段回调里产生的回调 check、prepare、idle 阶段:每次事件循环都会被执行。 Poll IO 阶段:处理文件描述符相关事件。 closing 阶段:执行调用 uv_close 函数时传入的回调。下面我们详细看一下每个阶段的实现。
4.1 定时器阶段
定时器的底层数据结构是二叉堆,最快到期的节点在最上面。在定时器阶段的时候,就会逐个节点遍历,如果节点超时了,那么就执行他的回调,如果没有超时,那么后面的节点也不用判断了,因为当前节点是最快过期的,如果他都没有过期,说明其他节点也没有过期。节点的回调被执行后,就会被删除,为了支持 setInterval 的场景,如果设置 repeat 标记,那么这个节点会被重新插入到二叉堆。
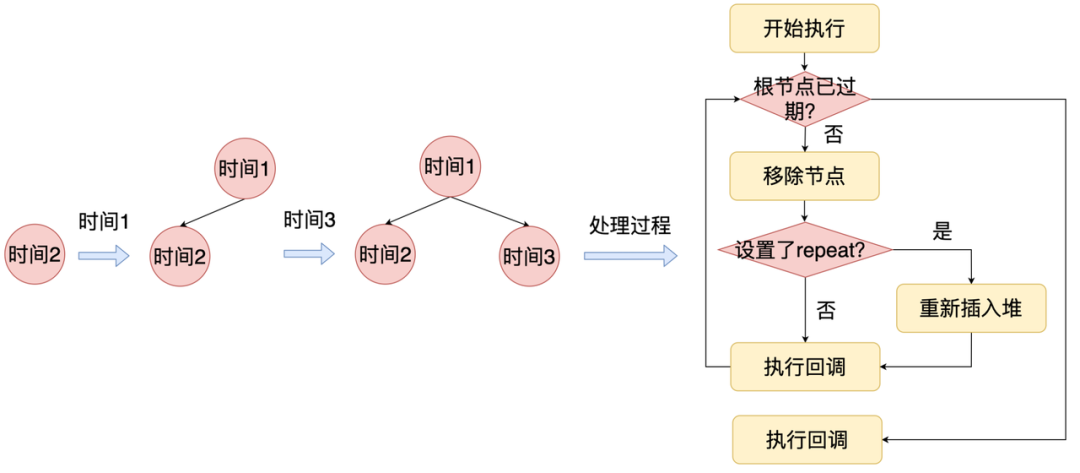
我们看到底层的实现稍微简单,但是 Node.js 的定时器模块实现就稍微复杂。
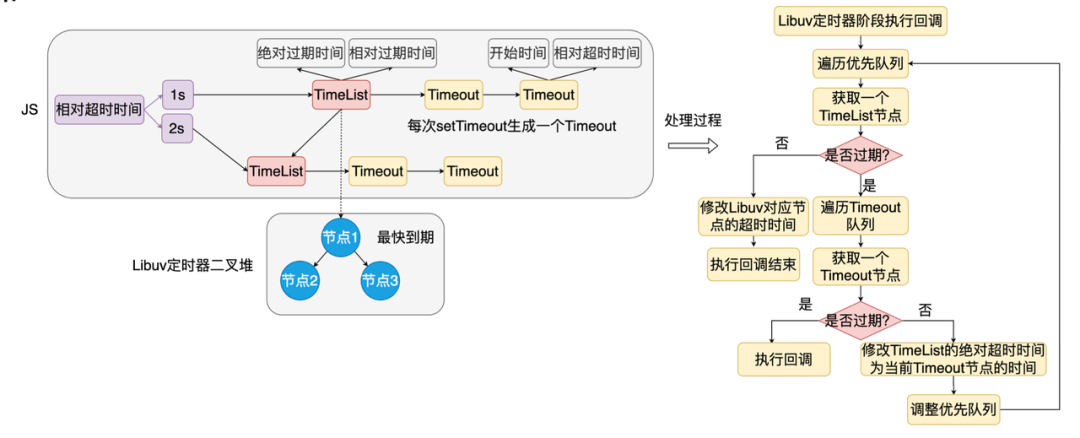
Node.js 在 JS 层维护了一个二叉堆。 堆的每个节点维护了一个链表,这个链表中,最久超时的排到后面。 另外 Node.js 还维护了一个 map,map 的 key 是相对超时时间,值就是对应的二叉堆节点。 堆的所有节点对应底层的一个超时节点。
当我们调用 setTimeout 的时候,首先根据 setTimeout 的入参,从 map 中找到二叉堆节点,然后插入链表的尾部,必要的时候,Node.js 会根据 js 二叉堆的最快超时时间来更新底层节点的超时时间。当事件循环处理定时器阶段的时候,Node.js 会遍历 JS 二叉堆,然后拿到过期的节点,再遍历过期节点中的链表,逐个判断是否需要执行回调,必要的时候调整 JS 二叉堆和底层的超时时间。
4.2 check、idle、prepare 阶段
check、idle、prepare 阶段相对比较简单,每个阶段维护一个队列,然后在处理对应阶段的时候,执行队列中每个节点的回调,不过这三个阶段比较特殊的是,队列中的节点被执行后不会被删除,而是一直在队列里,除非显式删除。
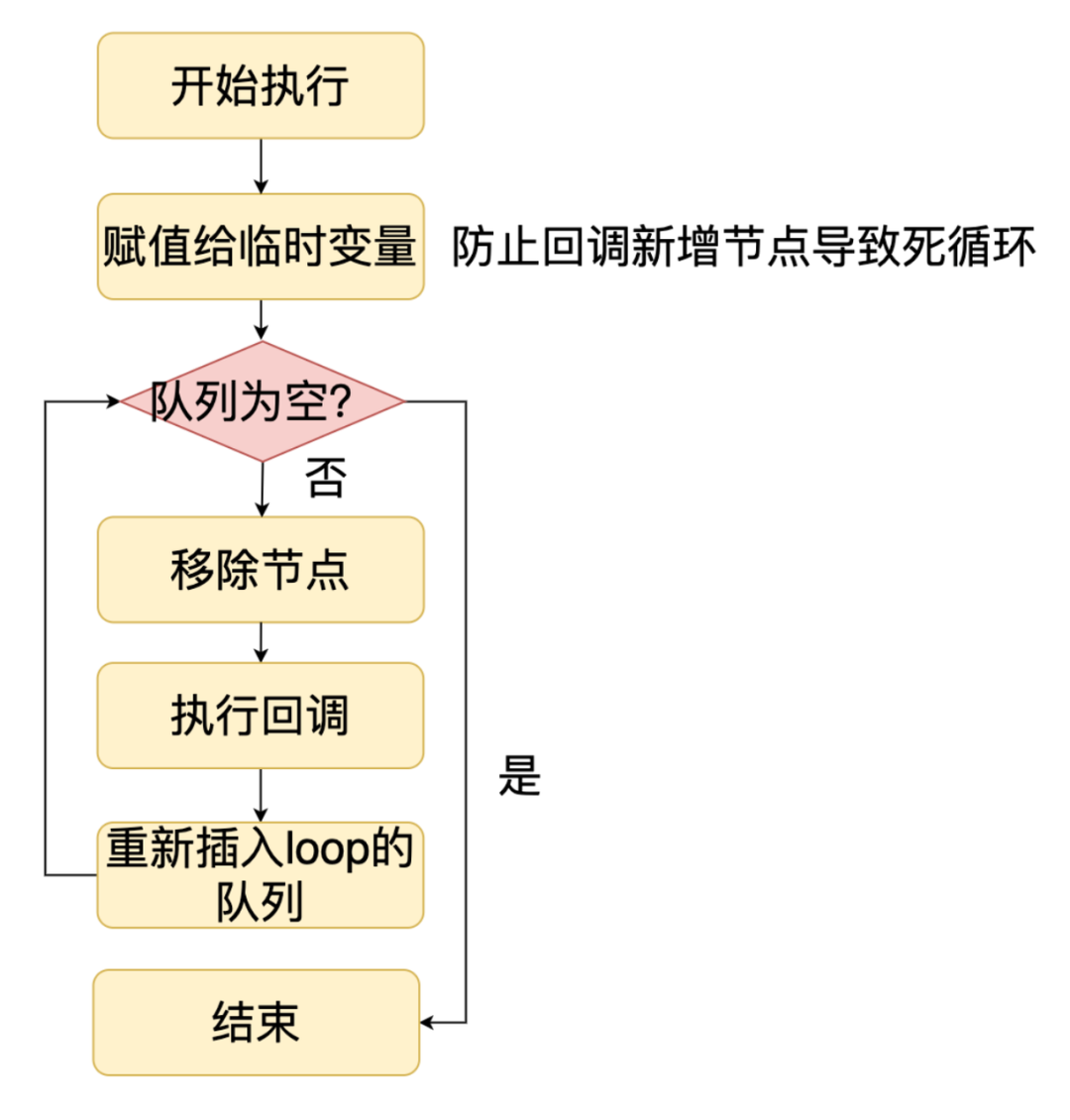
4.3 pending、closing 阶段
pending 阶段:在 Poll IO 回调里产生的回调。closing 阶段:执行关闭 handle 的回调。pending 和closing 阶段也是维护了一个队列,然后在对应阶段的时候执行每个节点的回调,最后删除对应的节点。
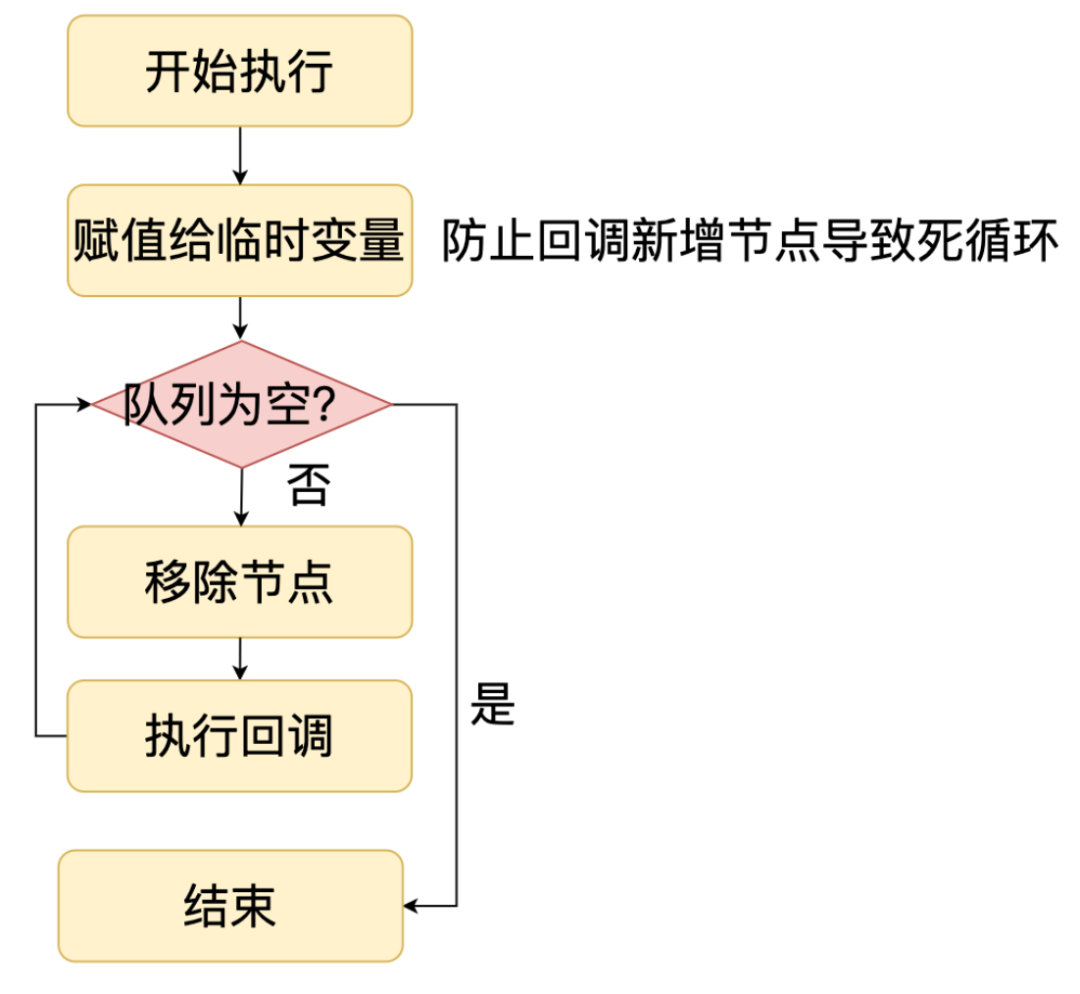
4.4 Poll IO 阶段
Poll IO 阶段是最重要和复杂的一个阶段,下面我们看一下实现。首先我们看一下 Poll IO 阶段核心的数据结构:IO 观察者,IO 观察者是对文件描述符,感兴趣事件和回调的封装,主要是用在 epoll 中。
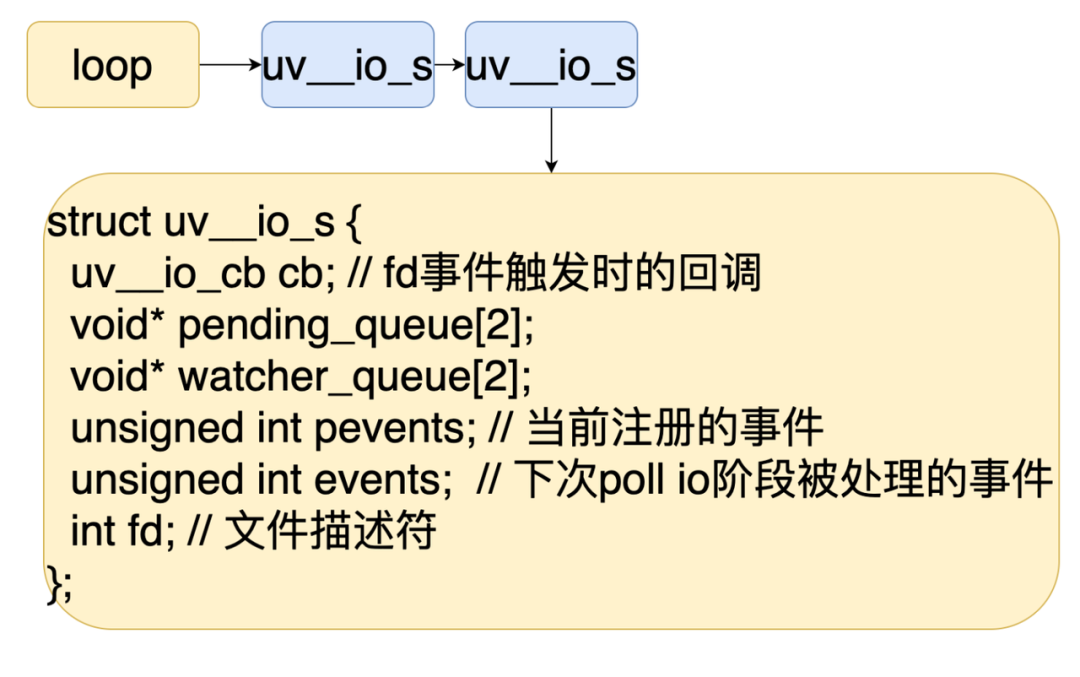
当我们有一个文件描述符需要被 epoll 监听的时候
我们可以创建一个 IO 观察者。 调用 uv__io_start 往事件循环中插入一个 IO 观察者队列。 Libuv 会记录文件描述符和 IO 观察者的映射关系。 在 Poll IO 阶段的时候就会遍历 IO 观察者队列,然后操作 epoll 去做相应的处理。 等从 epoll 返回的时候,我们就可以拿到哪些文件描述符的事件触发了,最后根据文件描述符找到对应的 IO 观察者并执行他的回调就行。
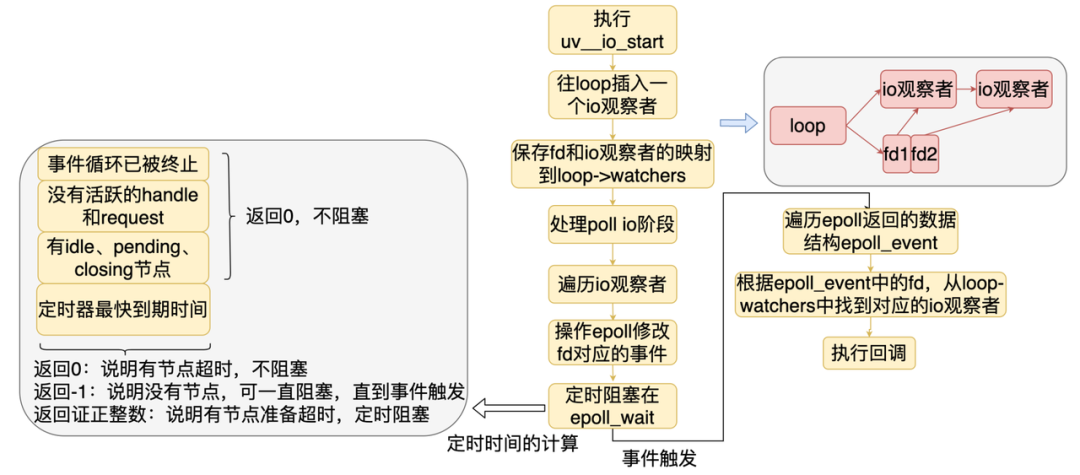
另外我们看到,Poll IO 阶段会可能会阻塞,是否阻塞和阻塞多久取决于事件循环系统当前的状态。当发生阻塞的时候,为了保证定时器阶段按时执行,epoll 阻塞的时间需要设置为等于最快到期定时器节点的时间。
5. 进程和进程间通信
5.1 创建进程
Node.js 中的进程是使用 fork+exec 模式创建的,fork 就是复制主进程的数据,exec 是加载新的程序执行。Node.js 提供了异步和同步创建进程两种模式。
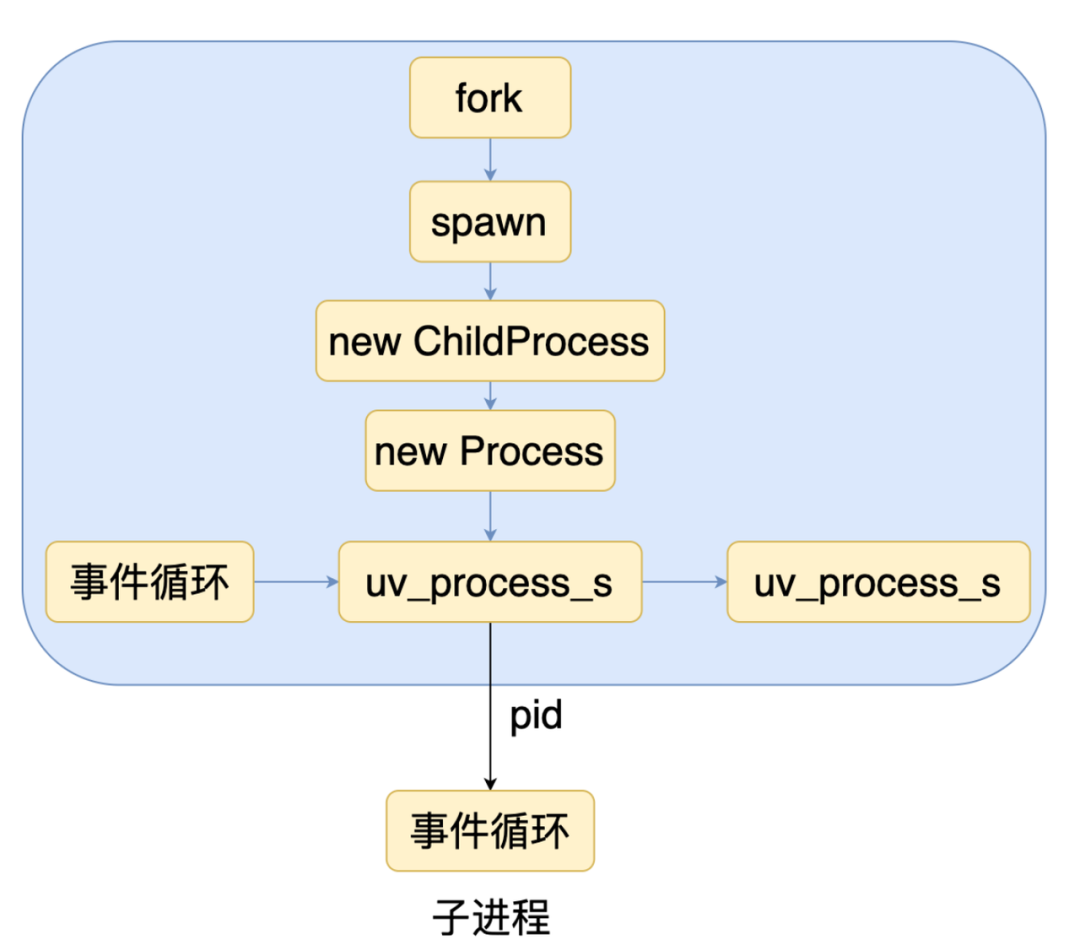
异步方式
异步方式就是创建一个人子进程后,主进程和子进程独立执行,互不干扰。在主进程的数据结构中如图所示,主进程会记录子进程的信息,子进程退出的时候会用到
同步方式
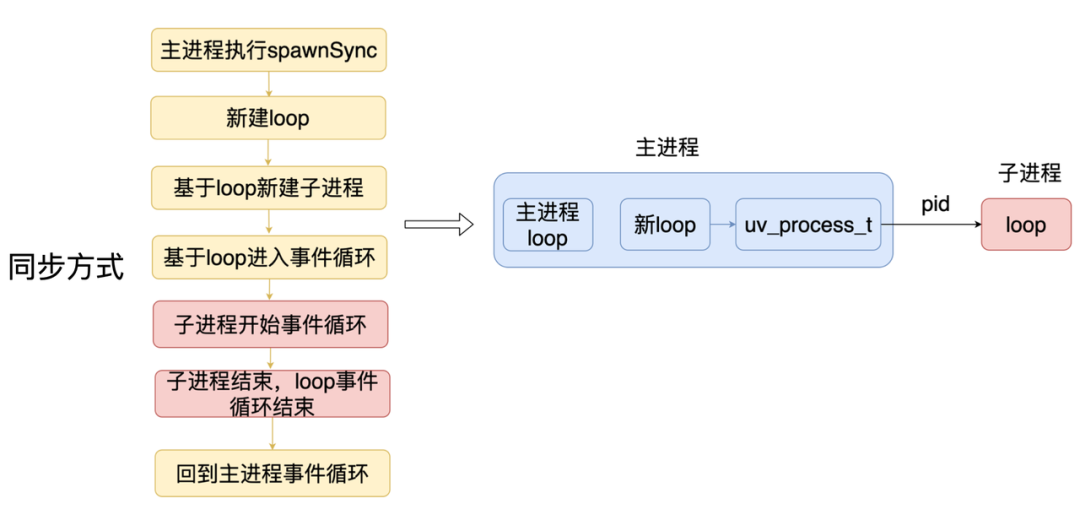
同步创建子进程会导致主进程阻塞,具体的实现是
主进程中会新建一个新的事件循环结构体,然后基于这个新的事件循环创建一个子进程。 然后主进程就在新的事件循环中执行,旧的事件循环就被阻塞了。 子进程结束的时候,新的事件循环也就结束了,从而回到旧的事件循环。
5.2 进程间通信
接下来我们看一下父子进程间怎么通信呢?在操作系统中,进程间的虚拟地址是独立的,所以没有办法基于进程内存直接通信,这时候需要借助内核提供的内存。进程间通信的方式有很多种,管道、信号、共享内存等等。
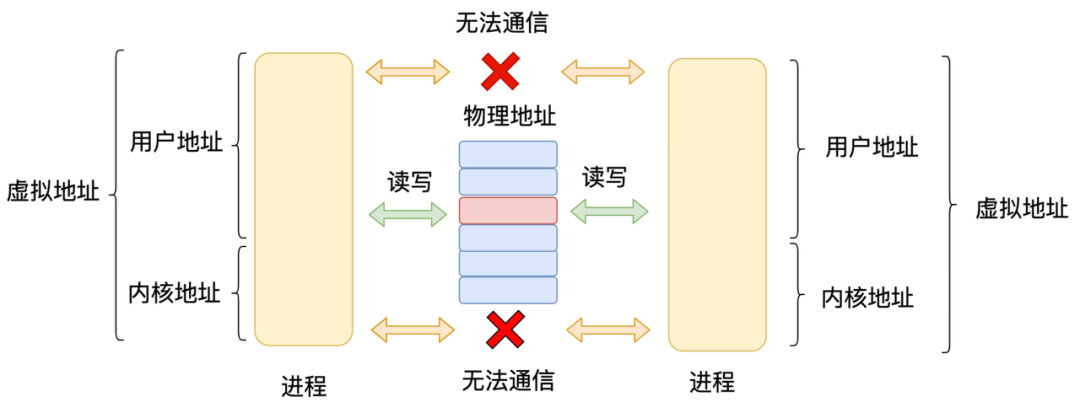
Node.js 选取的进程间通信方式是 Unix 域,Node.js 为什么会选取 Unix 域呢?因为只有 Unix 域支持文件描述符传递,文件描述符传递是一个非常重要的能力。
首先我们看一下文件系统和进程的关系,在操作系统中,当进程打开一个文件的时候,他就是形成一个fd->file->inode 这样的关系,这种关系在 fork 子进程的时候会被继承。
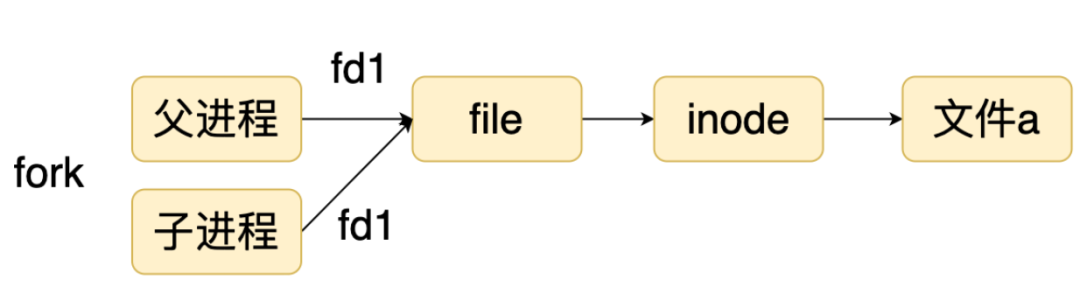
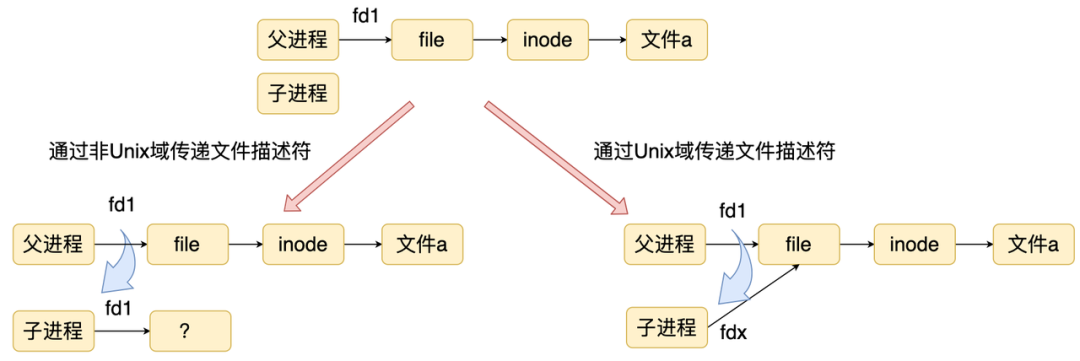
但是如果主进程在 fork 子进程之后,打开了一个文件,他想告诉子进程,那怎么办呢?如果仅仅是把文件描述符对应的数字传给子进程,子进程是没有办法知道这个数字对应的文件的。如果通过 Unix 域发送的话,系统会把文件描述符和文件的关系也复制到子进程中。
具体实现
Node.js 底层通过 socketpair 创建两个文件描述符,主进程拿到其中一个文件描述符,并且封装 send和 on meesage 方法进行进程间通信。 接着主进程通过环境变量把另一个文件描述符传给子进程。 子进程同样基于文件描述符封装发送和接收数据的接口。这样两个进程就可以进行通信了。
6. 线程和线程间通信
6.1 线程架构
Node.js 是单线程的,为了方便用户处理耗时的操作,Node.js 在支持多进程之后,又支持了多线程。Node.js 中多线程的架构如下图所示,每个子线程本质上是一个独立的事件循环,但是所有的线程会共享底层的 Libuv 线程池。
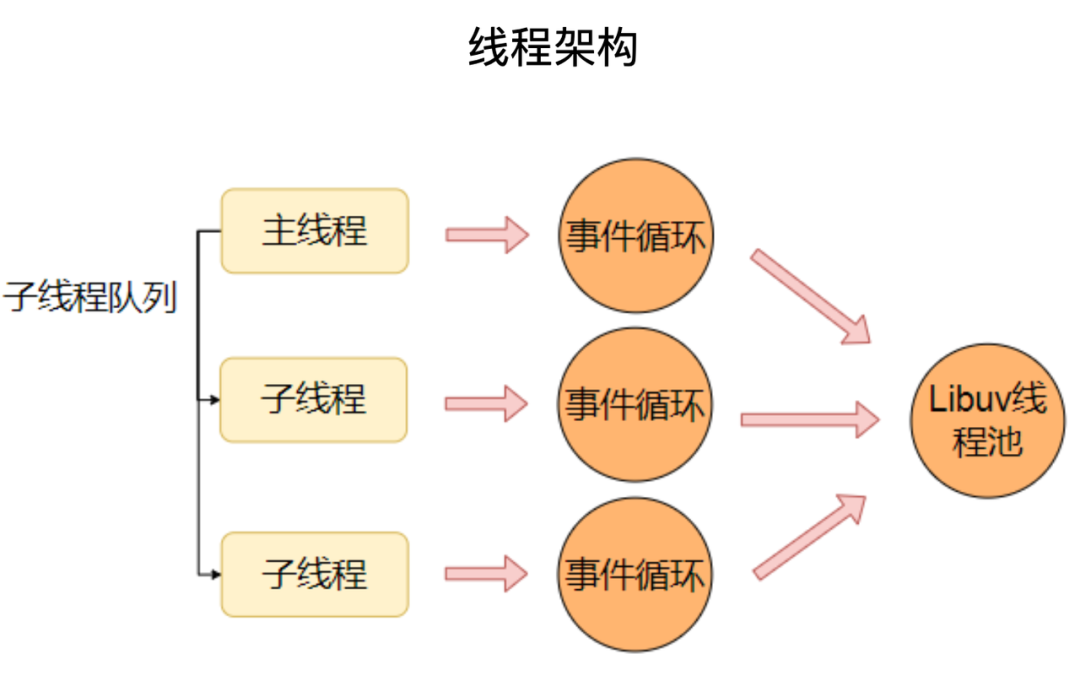
6.2 创建线程
接下来我们看看创建线程的过程。
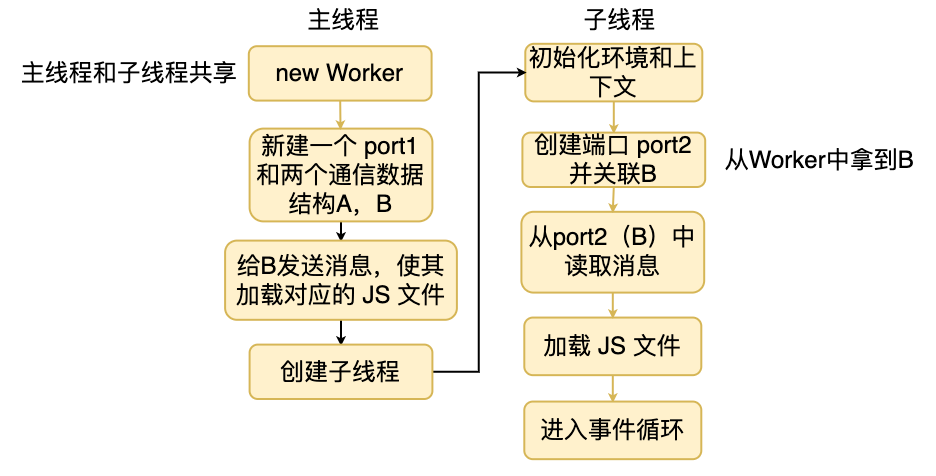
当我们调用 new Worker 创建线程的时候
主线程会首先创建创建两个通信的数据结构,接着往对端发送一个加载 JS 文件的消息。 然后调用底层接口创建一个线程。 这时候子线程就被创建出来了,子线程被创建后首先初始化自己的执行环境和上下文。 接着从通信的数据结构中读取消息,然后加载对应的js文件执行,最后进入事件循环。
6.3 线程间通信
那么 Node.js 中的线程是如何通信的呢?线程和进程不一样,进程的地址空间是独立的,不能直接通信,但是线程的地址是共享的,所以可以基于进程的内存直接进行通信。
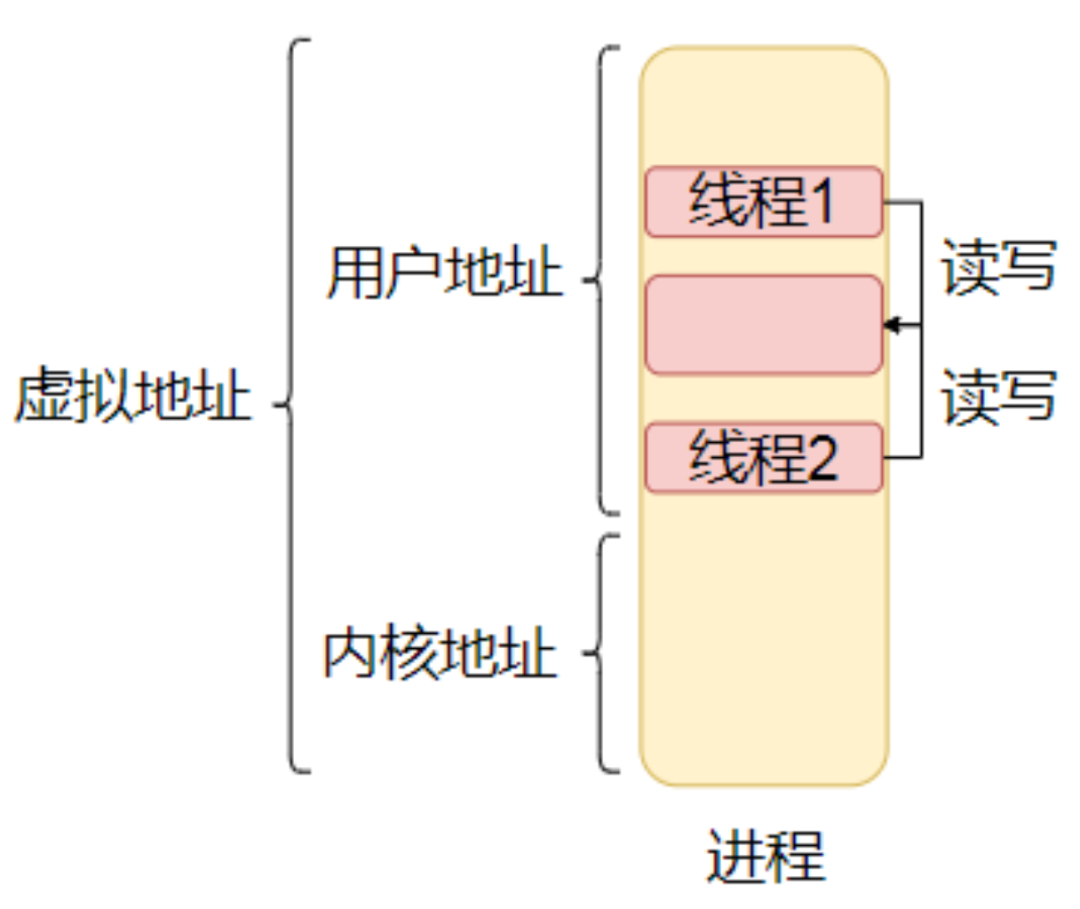
下面我们看看 Node.js 是如何实现线程间通信的。了解 Node.js 线程间通信之前,我们先看一下一些核心数据结构。
Message 代表一个消息。 MessagePortData 是对操作 Message 的封装和对消息的承载。 MessagePort 是代表通信的端点,是对 MessagePortData 的封装。 MessageChannel 是代表通信的两端,即两个 MessagePort。
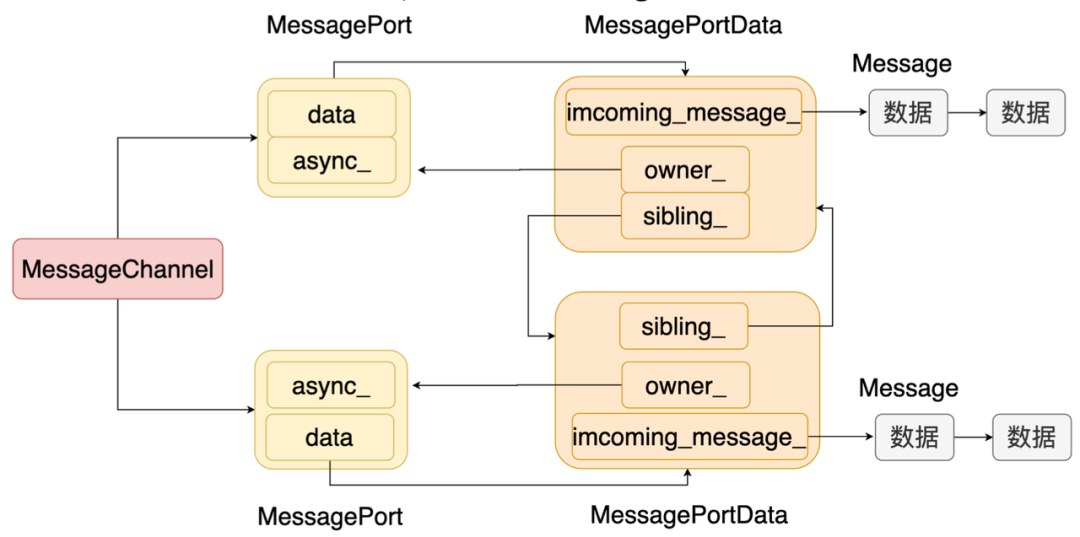
我们看到两个 port 是互相关联的,当需要给对端发送消息的时候,只需要往对端的消息队列插入一个节点就行。我们来看看通信的具体过程
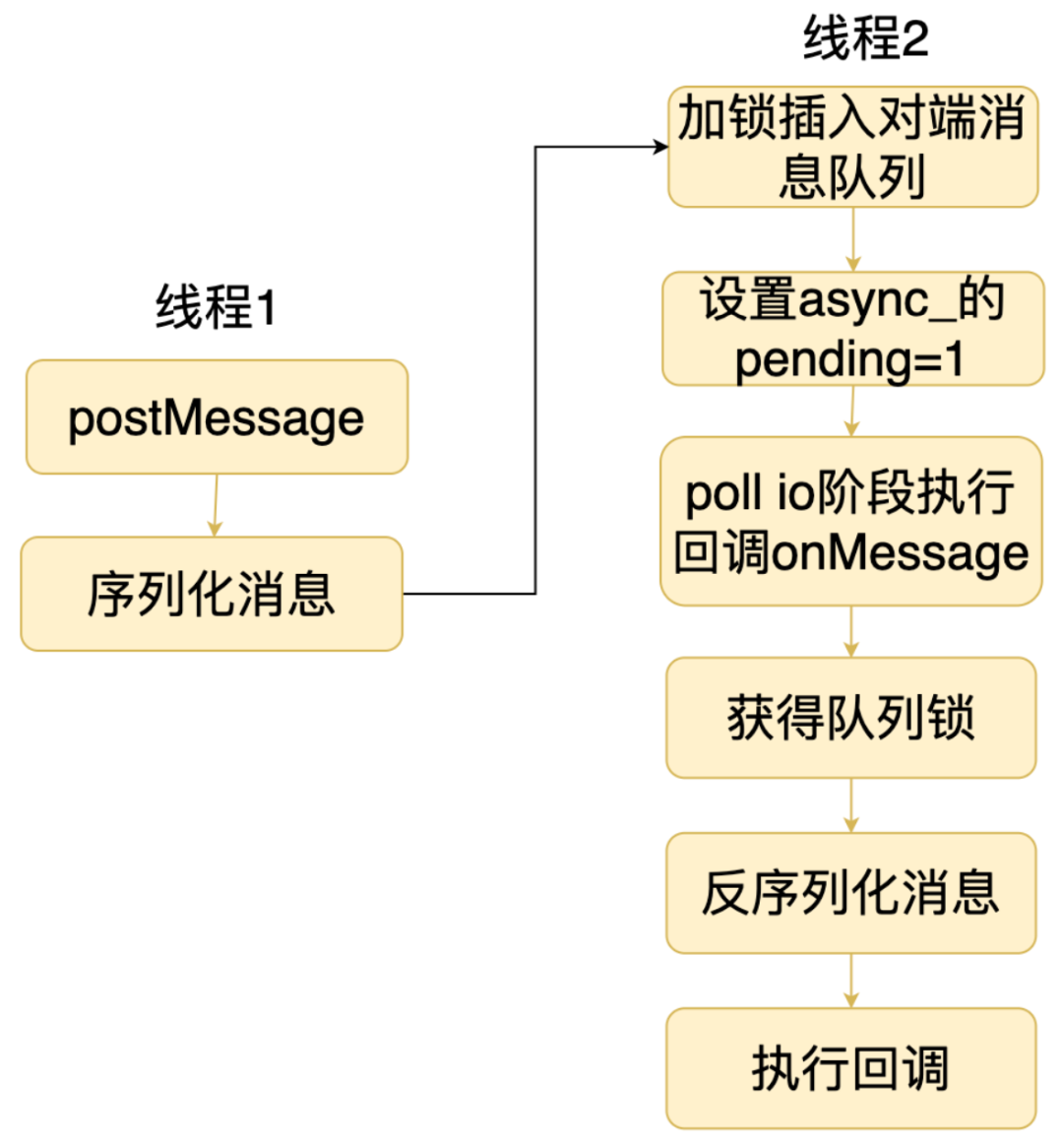
线程 1 调用 postMessage 发送消息。 postMessage 会先对消息进行序列化。 然后拿到对端消息队列的锁,并把消息插入队列中。 成功发送消息后,还需要通知消息接收者所在的线程。 消息接收者会在事件循环的 Poll IO 阶段处理这个消息。
7. Cluster
我们知道 Node.js 是单进程架构的,不能很好地利用多核,Cluster 模块使得 Node.js 支持多进程的服务器架构。Node.s 支持轮询(主进程 accept )和共享(子进程 accept )两种模式,可以通过环境变量进行设置。多进程的服务器架构通常有两种模式,第一种是主进程处理连接,然后分发给子进程处理,第二种是子进程共享 socket,通过竞争的方式获取连接进行处理。
我们看一下 Cluster 模块是如何使用的。
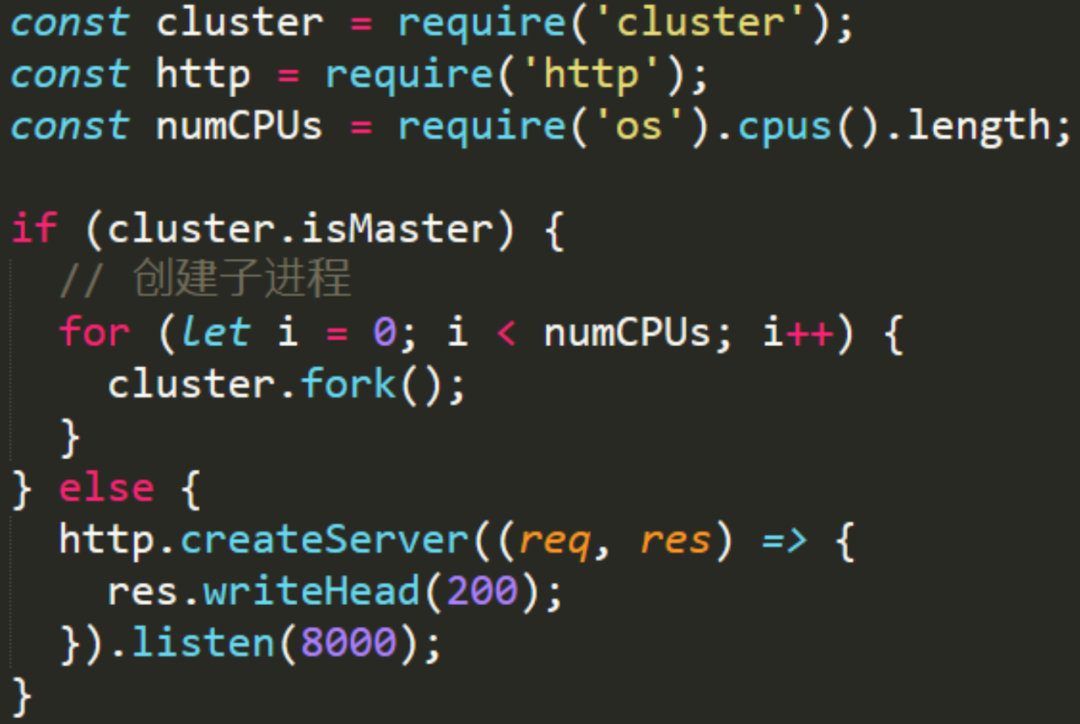
这个是 Cluster 模块的使用例子
主进程调用 fork 创建子进程。 子进程启动一个服务器。通常来说,多个进程监听同一个端口会报错,我们看看 Node.js 里是怎么处理这个问题的。
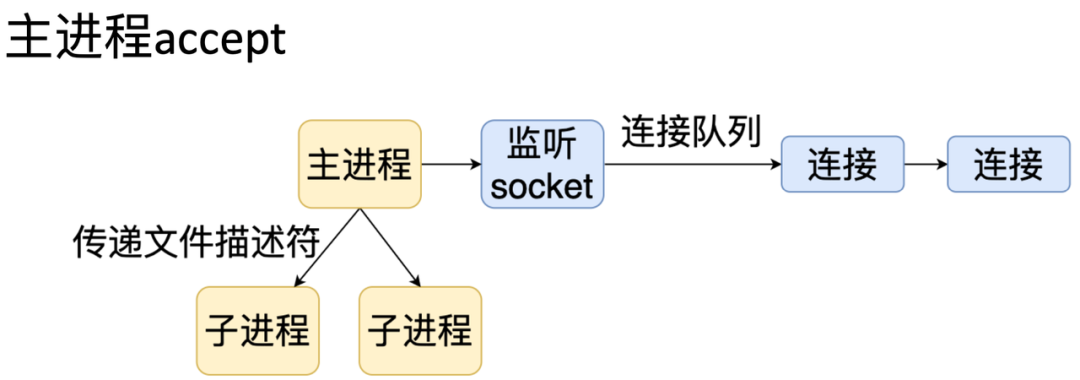
7.1 主进程accept
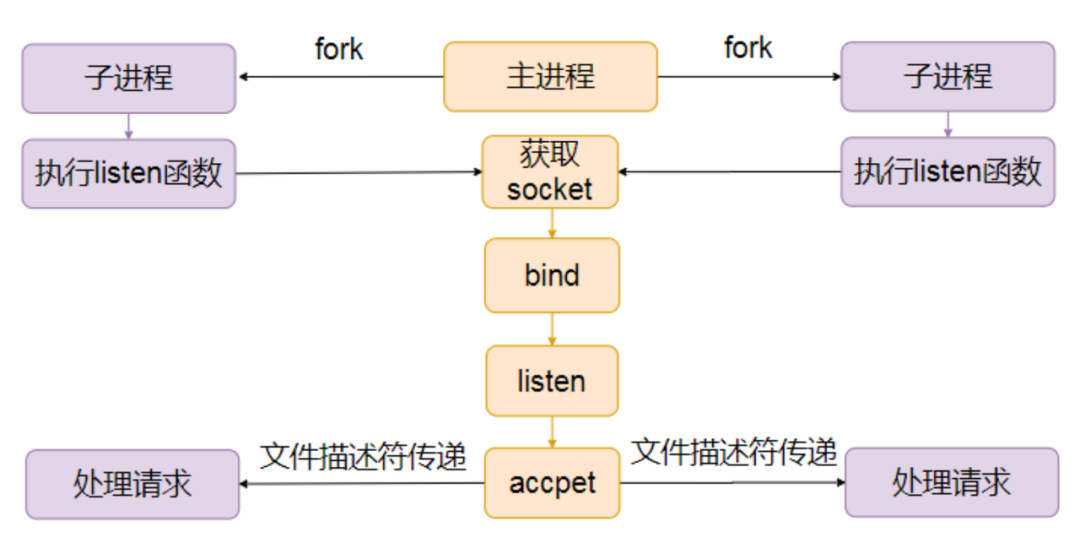
我们先看一下主进程 accept 这种模式。
首先主进程 fork 多个子进程处理。 然后在每个子进程里调用 listen。 调用 listen 函数的时候,子进程会给主进程发送一个消息。 这时候主进程就会创建一个 socket,绑定地址,并置为监听状态。 当连接到来的时候,主进程负责接收连接,然后然后通过文件描述符传递的方式分发给子进程处理。
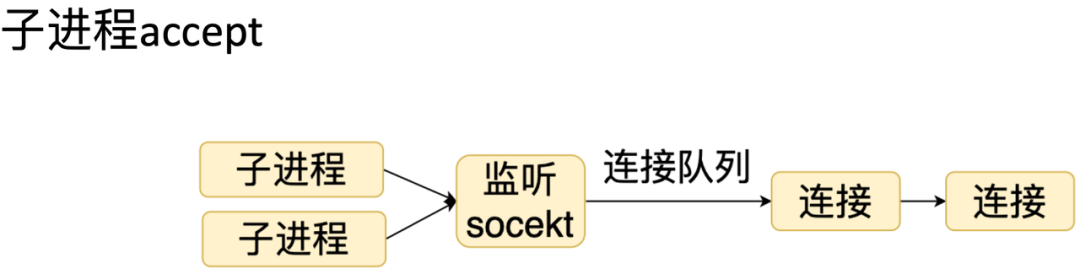
7.2 子进程 accept
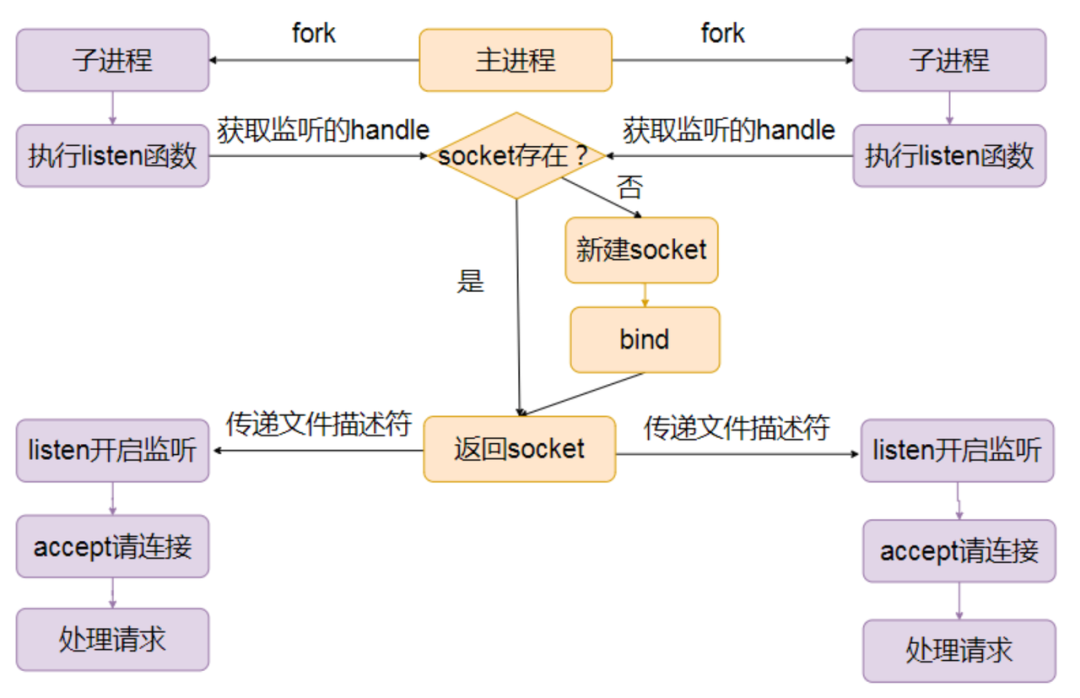
我们再看一下子进程 accept 这种模式。
首先主进程 fork 多个子进程处理。 然后在每个子进程里调用 listen。 调用listen函数的时候,子进程会给主进程发送一个消息。 这时候主进程就会创建一个 socket,并绑定地址。但不会把它置为监听状态,而是把这个 socket 通过文件描述符的方式返回给子进程。 当连接到来的时候,这个连接会被某一个子进程处理。
8. Libuv线程池
为什么需要使用线程池?文件 IO、DNS、CPU 密集型不适合在 Node.js 主线程处理,需要把这些任务放到子线程处理。
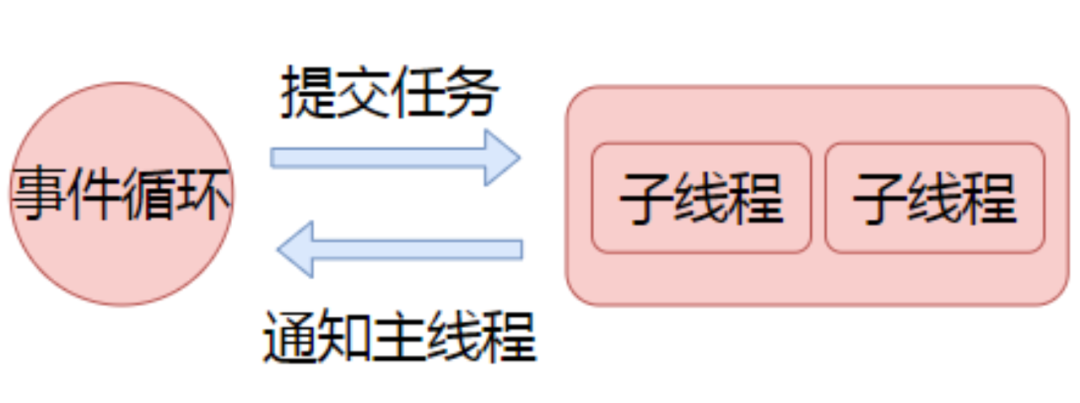
了解线程池实现之前我们先看看 Libuv 的异步通信机制,异步通信指的是 Libuv 主线程和其他子线程之间的通信机制。比如 Libuv 主线程正在执行回调,子线程同时完成了一个任务,那么如何通知主线程,这就需要用到异步通信机制。
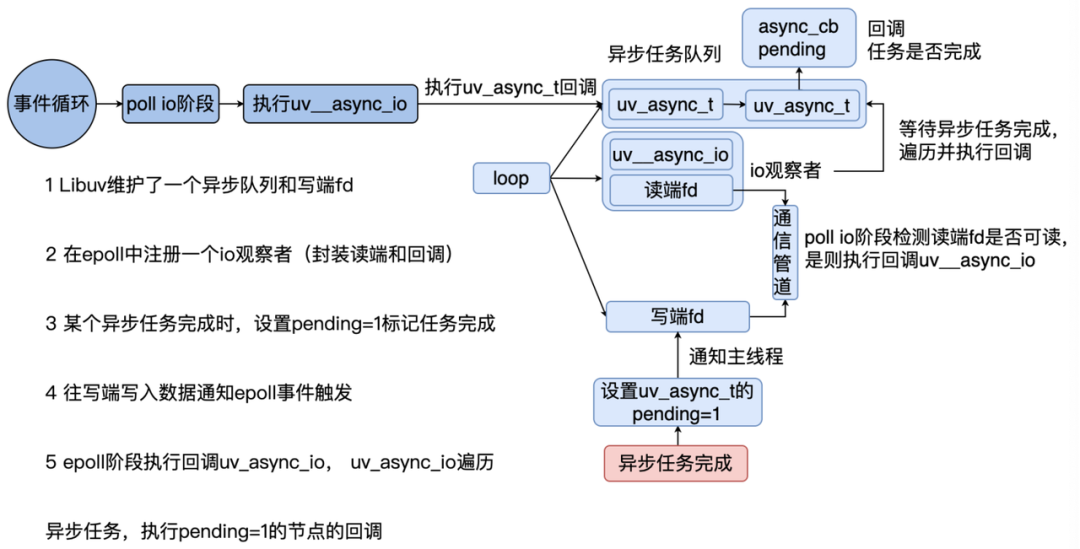
Libuv 内部维护了一个异步通信的队列,需要异步通信的时候,就往里面插入一个 async 节点 同时 Libuv 还维护了一个异步通信相关的 IO 观察者 当有异步任务完成的时候,就会设置对应 async 节点的 pending 字段为 1,说明任务完成了。并且通知主线程。 主线程在 Poll IO 阶段就会执行处理异步通信的回调,在回调里会执行 pending 为 1 的节点的回调。
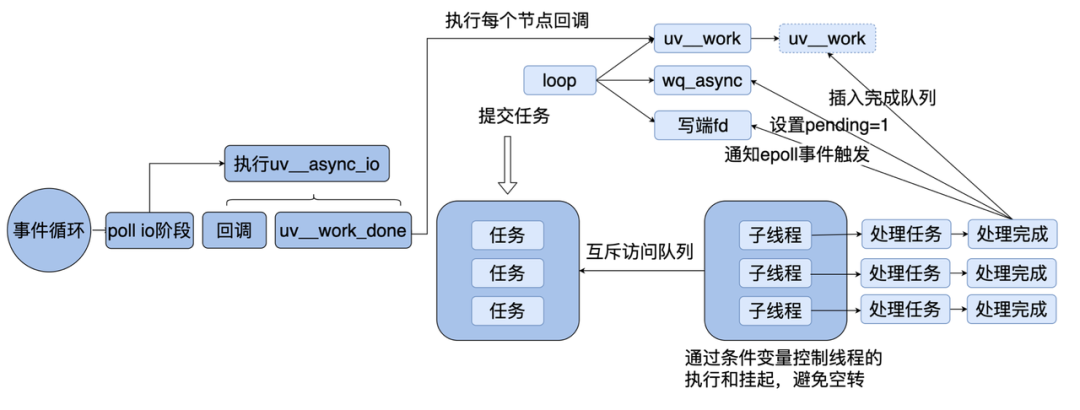
下面我们来看一下线程池的实现。
线程池维护了一个待处理任务队列,多个线程互斥地从队列中摘下任务进行处理。 当给线程池提交一个任务的时候,就是往这个队列里插入一个节点。 当子线程处理完任务后,就会把这个任务插入到事件循环本身维护到一个已完成任务队列中,并且通过异步通信的机制通知主线程。 主线程在 Poll IO 阶段就会执行任务对应的回调。
9. 信号

上图是操作系统中信号的表示,操作系统使用一个 long 类型表示进程收到的信息,并且用一个数组来标记对应的处理函数。我们看一下信号模块在 Libuv 中是如何实现的。
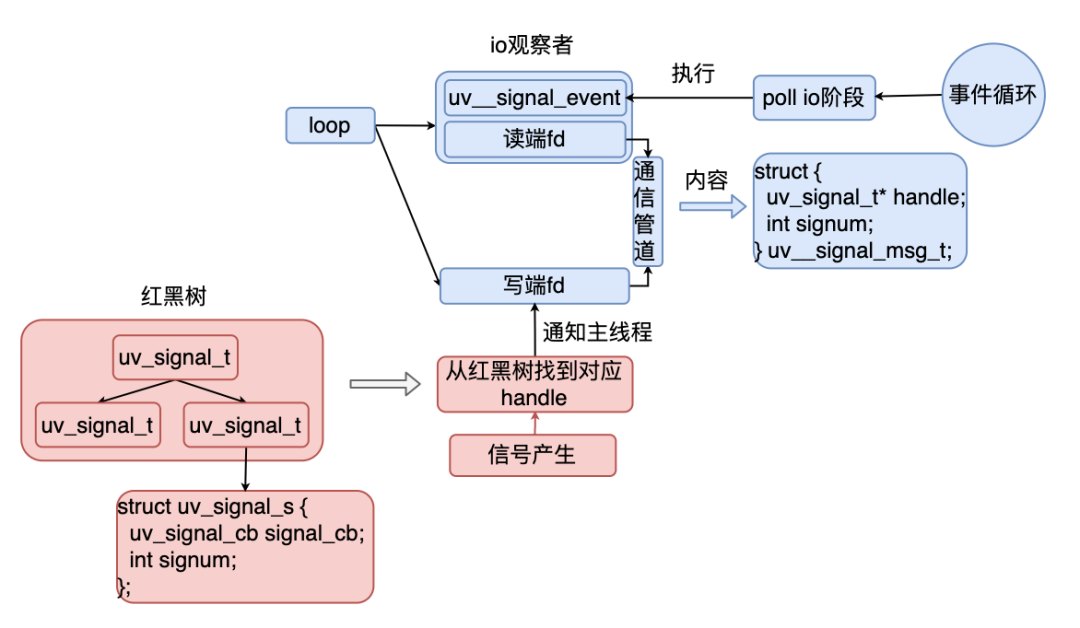
Libuv 中维护了一个红黑树,当我们监听一个新的信号时就会新插入一个节点 在插入第一个节点时,Libuv 会封装一个 IO 观察者注册到 epoll 中,用来监听是否有信号需要处理 当信号发生的时候,就会根据信号类型从红黑树中找到对应的 handle,然后通知主线程 主线程在 Poll IO 阶段就会逐个执行回调。
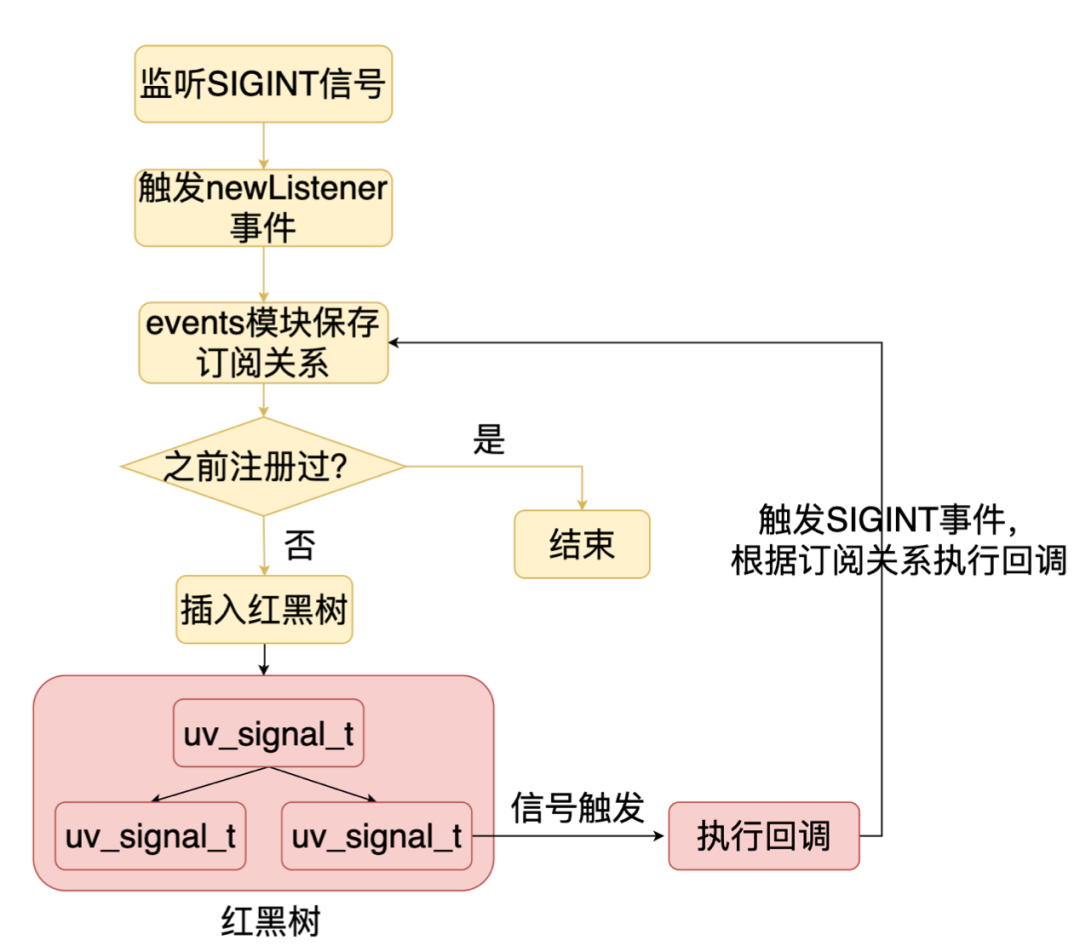
Node.js 中,是通过监听 newListener 事件来实现信号的监听的,newListener 是一种 hooks 的机制。每次监听事件的时候,如果监听了 newListener 事件,那就会触发 newListener 事件。所以当执行 process.on(’SIGINT’) 时,就会调用 startListeningIfSignal (newListener事件的处理器)注册一个红黑树节点。并在 events 模块保存了订阅关系,信号触发时,执行 process.emit(‘SIGINT’) 通知订阅者。
10. 文件
10.1 文件操作
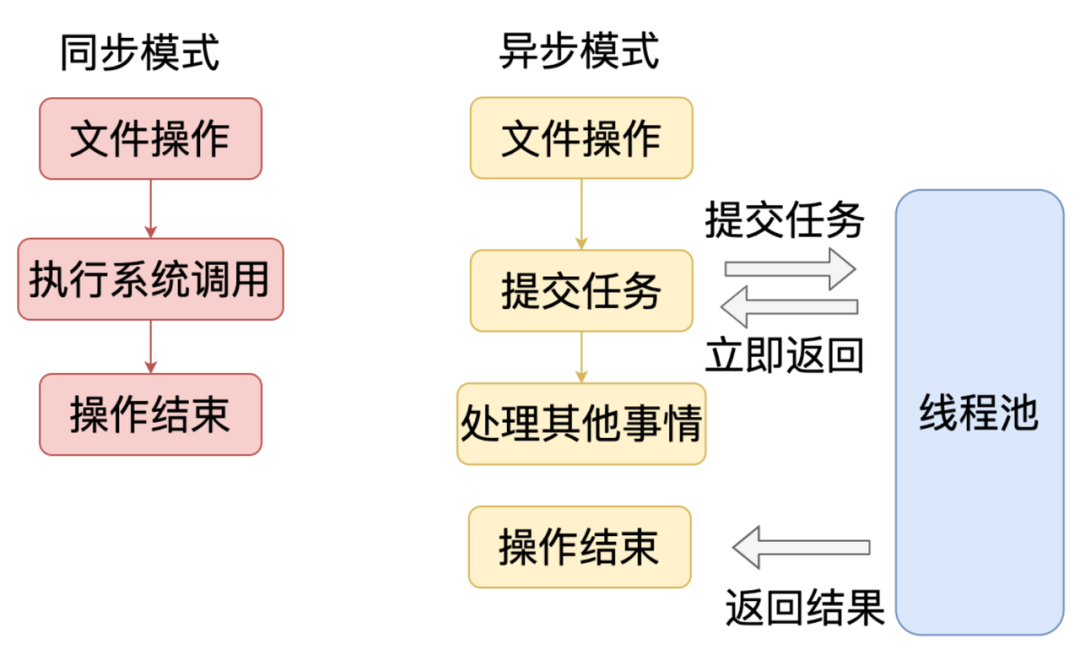
Node.js 中文件操作分为同步和异步模式,同步模式就是在主进程中直接调用文件系统的 API,这种方式可能会引起进程的阻塞,异步方式是借助了 Libuv 线程池,把阻塞操作放到子线程中去处理,主线程可以继续处理其他操作。
10.2 文件监听
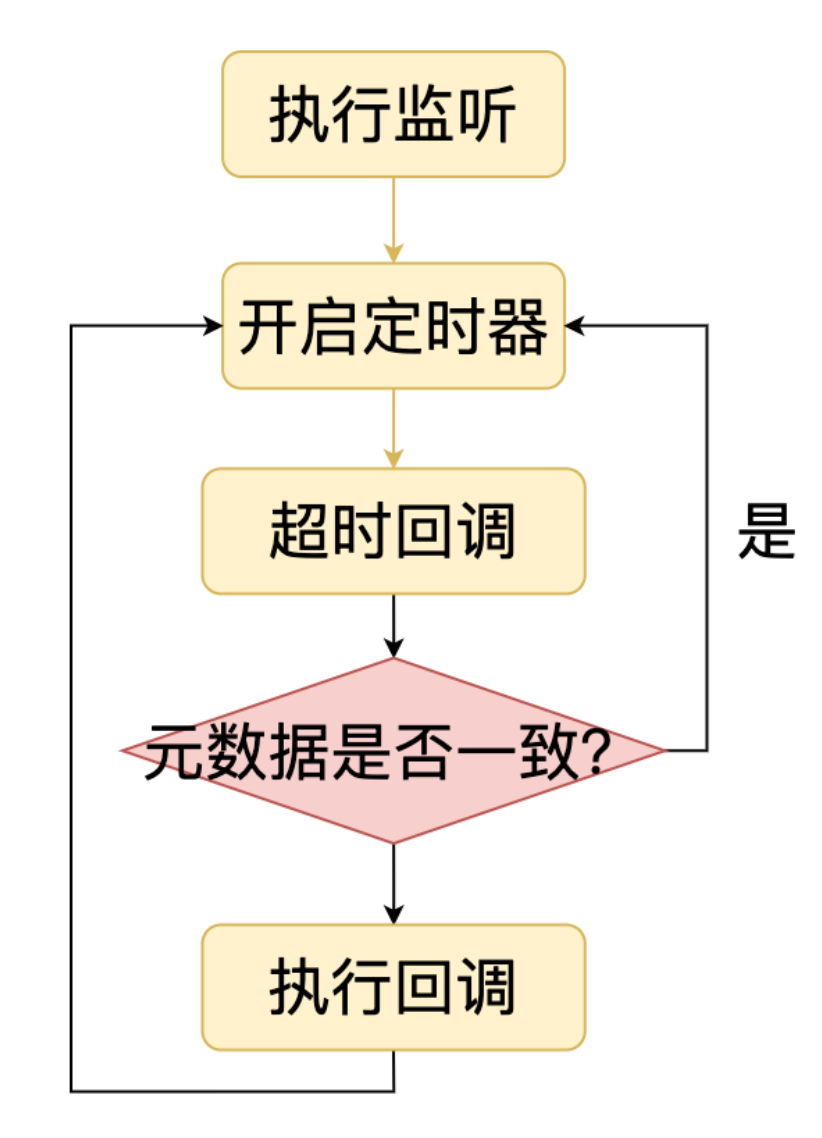
Node.js 中文件监听提供了基于轮询和订阅发布两种模式。我们先看一下轮询模式的实现,轮询模式比较简单,他是使用定时器实现的,Node.js 会定时执行回调,在回调中比较当前文件的元数据和上一次获取的是否不一样,如果是则说明文件改变了。
第二种监听模式是更高效的 inotify 机制,inotify 是基于订阅发布模式的,避免了无效的轮询。我们首先看一下操作系统的 inotify 机制,inotify 和 epoll 的使用是类似的:
首先通过接口获取一个 inotify 实例对应的文件描述符。 然后通过增删改查接口操作 inotify 实例,比如需要监听一个文件的时候,就调用接口往 inotify 实例中新增一个订阅关系。 当文件发生改变的时候,我们可以调用 read 接口获取哪些文件发生了改变,inotify 通常结合 epoll 来使用。
接下来我们看看 Node.js 中是如何基于 inotify 机制 实现文件监听的。
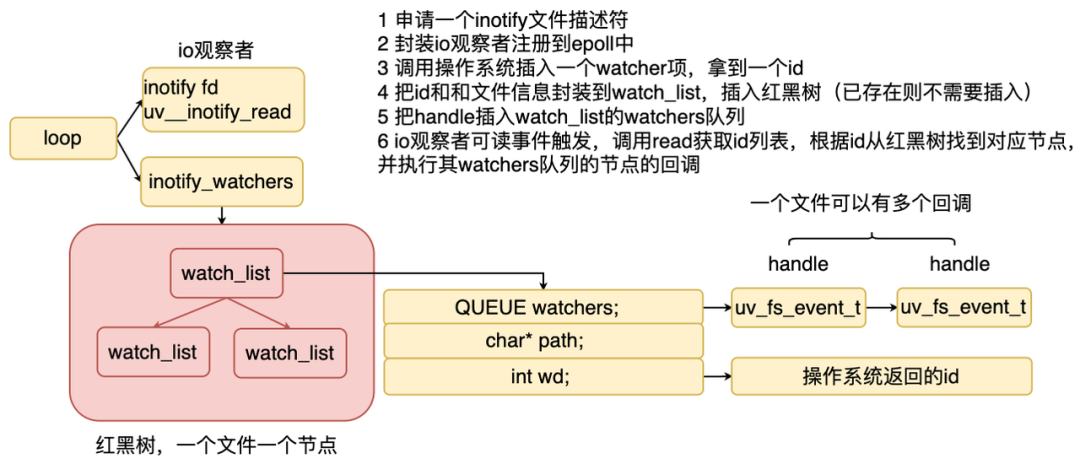
首先 Node.js 把 inotify 实例的文件描述符和回调封装成 io 观察者注册到 epoll 中 当需要监听一个文件的时候,Node.js 会调用系统函数往 inotify 实例中插入一个项,并且拿到一个 id,接着 Node.js 把这个 id 和文件信息封装到一个结构体中,然后插入红黑树。 Node.js 维护了一棵红黑树,红黑树的每个节点记录了被监听的文件或目录和事件触发时的回调列表。 如果有事件触发时,在 Poll IO 阶段就会执行对应的回调,回调里会判断哪些文件发生了变化,然后根据id从红黑树中找到对应的接口,从而执行对应的回调。
11. TCP
我们通常会调用 http.createServer(cb).listen(port) 启动一个服务器,那么这个过程到底做了什么呢?listen 函数其实是对网络 API 的封装:
首先获取一个 socket。 然后绑定地址到该 socket 中。 接着调用 listen 函数把该 socket 改成监听状态。 最后把该 socket 注册到 epoll 中,等待连接的到来。
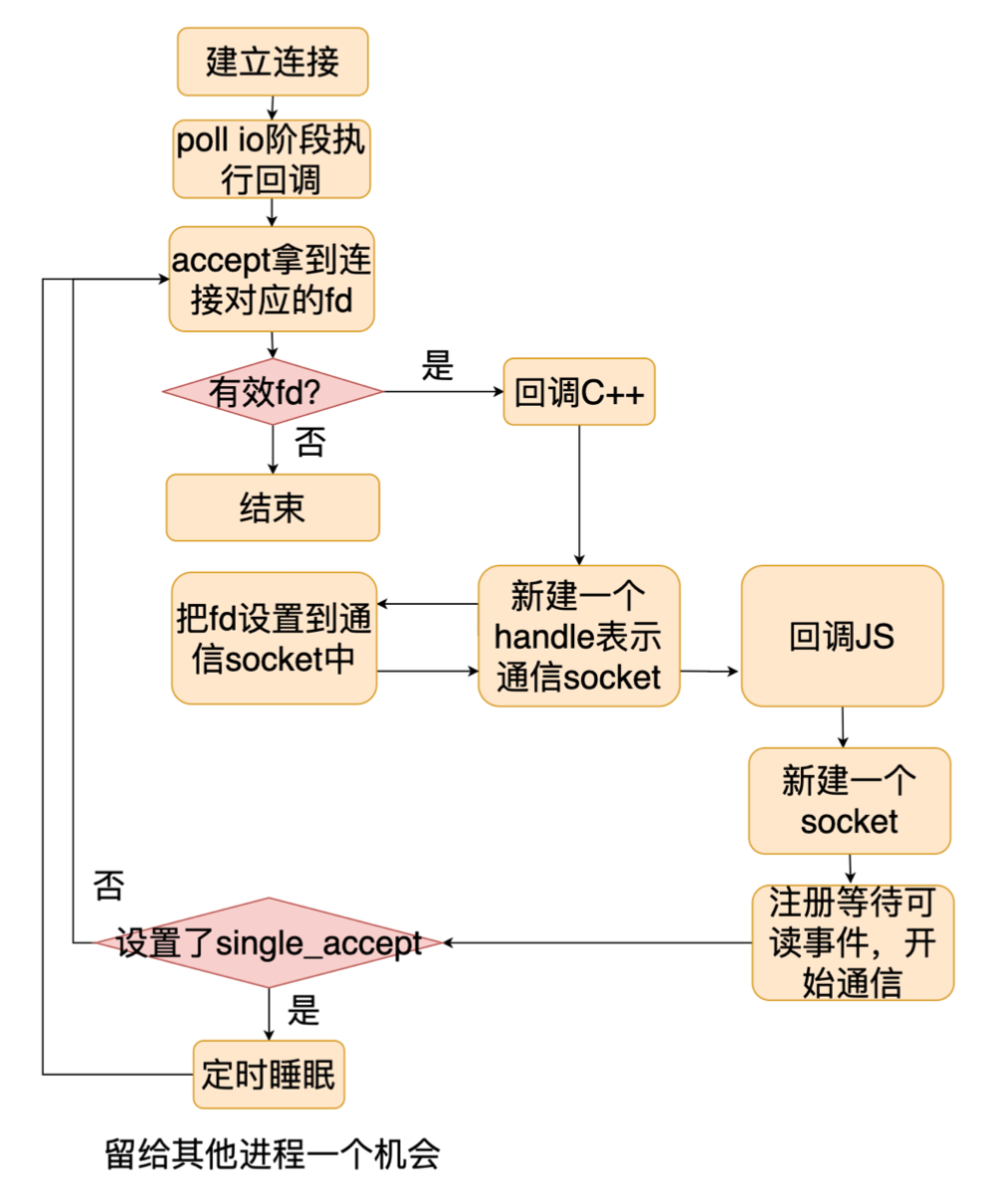
那么 Node.js 是如何处理连接的呢?当建立了一个 TCP 连接后,Node.js 会在 Poll IO 阶段执行对应的回调:
Node.js 会调用 accept 摘下一个 TCP 连接。 接着会调 C++ 层,C++ 层会新建一个对象表示和客户端通信的实例。 接着回调 JS 层,JS 也会新建一个对象表示通信的实例,主要是给用户使用。 最后注册等待可读事件,等待客户端发送数据过来。
这就是 Node.js 处理一个连接的过程,处理完一个连接后,Node.js 会判断是否设置了 single_accept 标记,如果有则睡眠一段时间,给其他进程处理剩下的连接,一定程度上避免负责不均衡,如果没有设置该标记,Node.js 会继续尝试处理下一个连接。这就是 Node.js 处理连接的整个过程。
12. UDP
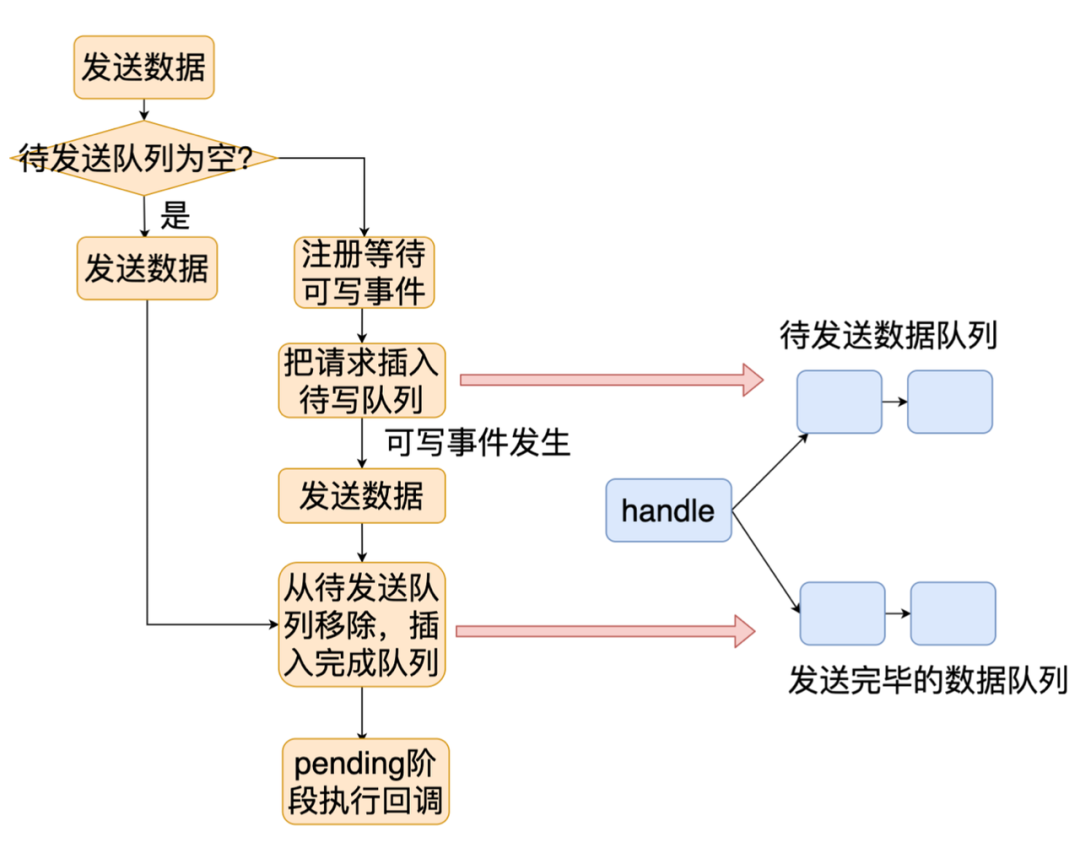
因为 UDP 是非连接、不可靠的协议,在实现和使用上相对比较简单,这里讲一下发送 UDP 数据的过程,当我们发送一个 UDP 数据包的时候,Libuv 会把数据先插入等待发送队列,接着在 epoll 中注册等待可写事件,当可写事件触发的时候,Libuv 会遍历等待发送队列,逐个节点发送,成功发送后,Libuv 会把节点移到发送成功队列,并往 pending 阶段插入一个节点,在 pending 阶段,Libuv 就会执行发送完成队列里每个节点的会调通知调用方发送结束。
13. DNS
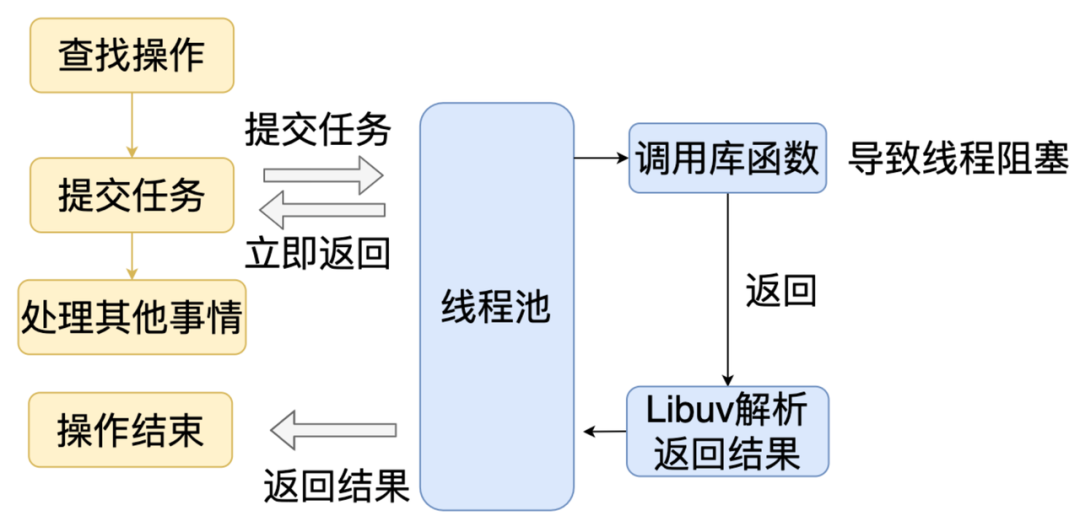
因为通过域名查找 IP 或通过 IP 查找域名的 API 是阻塞式的,所以这两个功能是借助了 Libuv 的线程池实现的。发起一个查找操作的时候,Node.js 会往线程池提及一个任务,然后就继续处理其他事情,同时,线程池的子线程会调用底层函数做 DNS 查询,查询结束后,子线程会把结果交给主线程。这就是整个查找过程。
其他的 DNS 操作是通过 cares 实现的,cares 是一个异步 DNS 库,我们知道 DNS 是一个应用层协议,cares 就是实现了这个协议。我们看一下 Node.js 是怎么使用 cares 实现 DNS 操作的。
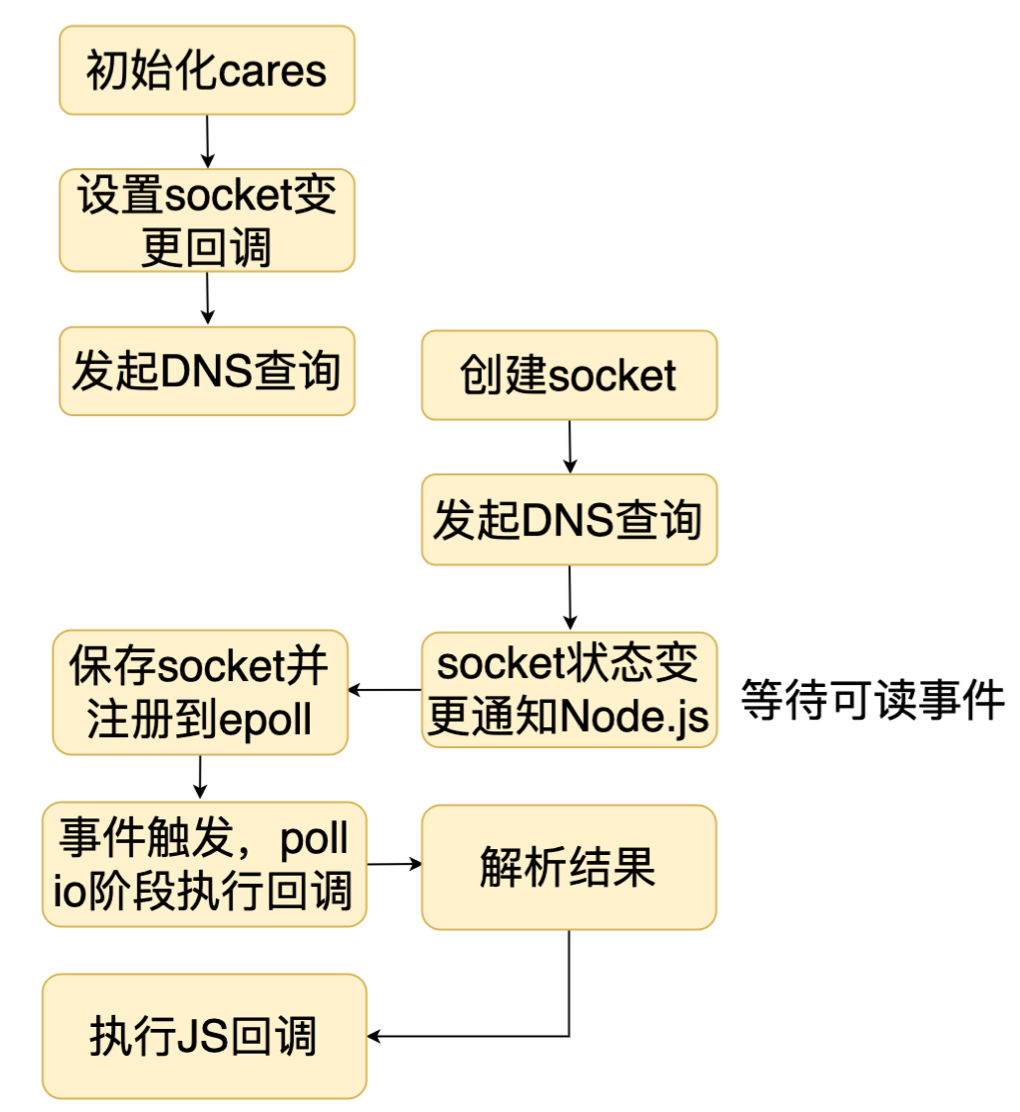
首先 Node.js 初始化的时候,会初始化 cares 库,其中最重要的是设置 socket 变更的回调。我们一会可以看到这个回调的作用。 当我们发起一个 DNS 操作的时候,Node.js 会调用 cares 的接口,cares 接口会创建一个 socket 并发起一个 DNS 查询,接着通过状态变更回调把 socket 传给 Node.js。 Node.js 把这个 socket 注册到 epoll 中,等待查询结果,当查询结果返回的时候,Node.js 会调用 cares 的函数进行解析,最后调用 JS 回调通知用户。
14. 总结
本文从整体的角度介绍了一下 Node.js 的实现,同时也介绍了一些核心模块的实现。从本文中,我们也看到了很多底层的内容,Node.js 正是结合了 V8 和 操作系统的能力创建出来的 JS 运行时。深入去理解 Node.js的原理和实现,可以更好地使用 Node.js。
更多内容可以参考:https://github.com/theanarkh/understand-nodejs
- END -