
【127期】面试官:你说使用过ZooKeeper,那来说说他的基本原理吧

阅读本文大概需要 10 分钟。
ZooKeeper简介
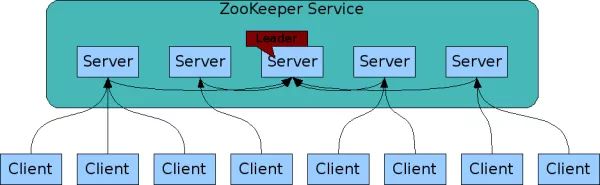
ZooKeeper设计目的
最终一致性:client不论连接到哪个Server,展示给它都是同一个视图,这是zookeeper最重要的性能。
可靠性:具有简单、健壮、良好的性能,如果消息m被到一台服务器接受,那么它将被所有的服务器接受。
实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用sync()接口。
等待无关(wait-free):慢的或者失效的client不得干预快速的client的请求,使得每个client都能有效的等待。
原子性:更新只能成功或者失败,没有中间状态。
顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
ZooKeeper数据模型
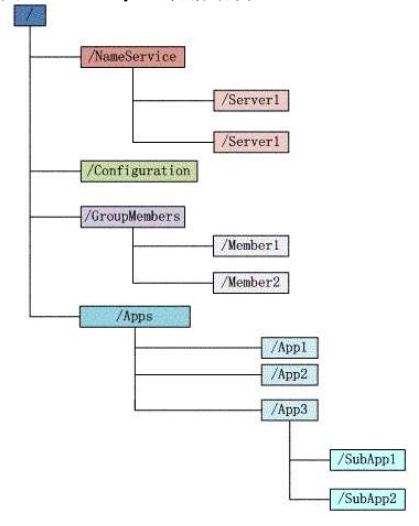
Persistent 节点,一旦被创建,便不会意外丢失,即使服务器全部重启也依然存在。每个 Persist 节点即可包含数据,也可包含子节点。
Ephemeral 节点,在创建它的客户端与服务器间的 Session 结束时自动被删除。服务器重启会导致 Session 结束,因此 Ephemeral 类型的 znode 此时也会自动删除。
Non-sequence 节点,多个客户端同时创建同一 Non-sequence 节点时,只有一个可创建成功,其它匀失败。并且创建出的节点名称与创建时指定的节点名完全一样。
Sequence 节点,创建出的节点名在指定的名称之后带有10位10进制数的序号。多个客户端创建同一名称的节点时,都能创建成功,只是序号不同。
ZooKeeper Session
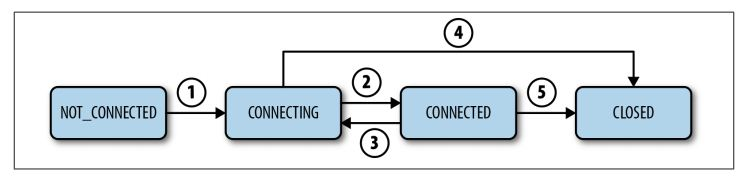
注意:如果因为网络状态不好,client和Server失去联系,client会停留在当前状态,会尝试主动再次连接Zookeeper Server。client不能宣称自己的session expired,session expired是由Zookeeper Server来决定的,client可以选择自己主动关闭session。
ZooKeeper Watch
a watch event is one-time trigger, sent to the client that set the watch, whichoccurs when the data for which the watch was set changes。
Consistency Guarantees
顺序一致性(Sequential Consistency):从一个客户端来的更新请求会被顺序执行。
原子性(Atomicity):更新要么成功要么失败,没有部分成功的情况。
唯一的系统镜像(Single System Image):无论客户端连接到哪个Server,看到系统镜像是一致的。
可靠性(Reliability):更新一旦有效,持续有效,直到被覆盖。
时间线(Timeliness):保证在一定的时间内各个客户端看到的系统信息是一致的。
ZooKeeper的工作原理
角色:leader,follower,observer
状态:leading,following,observing,looking
LOOKING:当前Server不知道leader是谁,正在搜寻。
LEADING:当前Server即为选举出来的leader。
FOLLOWING:leader已经选举出来,当前Server与之同步。
OBSERVING:observer的行为在大多数情况下与follower完全一致,但是他们不参加选举和投票,而仅仅接受(observing)选举和投票的结果。
Leader Election
选举线程由当前Server发起选举的线程担任,其主要功能是对投票结果进行统计,并选出推荐的Server;
选举线程首先向所有Server发起一次询问(包括自己);
选举线程收到回复后,验证是否是自己发起的询问(验证zxid是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议的leader相关信息(id,zxid),并将这些信息存储到当次选举的投票记录表中;
收到所有Server回复以后,就计算出zxid最大的那个Server,并将这个Server相关信息设置成下一次要投票的Server;
线程将当前zxid最大的Server设置为当前Server要推荐的Leader,如果此时获胜的Server获得n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server,将根据获胜的Server相关信息设置自己的状态,否则,继续这个过程,直到leader被选举出来。
Leader工作流程
恢复数据;
维持与follower的心跳,接收follower请求并判断follower的请求消息类型;
follower的消息类型主要有PING消息、REQUEST消息、ACK消息、REVALIDATE消息,根据不同的消息类型,进行不同的处理。
PING消息是指follower的心跳信息;REQUEST消息是follower发送的提议信息,包括写请求及同步请求;
ACK消息是follower的对提议的回复,超过半数的follower通过,则commit该提议;
REVALIDATE消息是用来延长SESSION有效时间。
Follower工作流程
向Leader发送请求(PING消息、REQUEST消息、ACK消息、REVALIDATE消息);
接收Leader消息并进行处理;
接收Client的请求,如果为写请求,发送给Leader进行投票;
返回Client结果。
PING消息:心跳消息
PROPOSAL消息:Leader发起的提案,要求Follower投票
COMMIT消息:服务器端最新一次提案的信息
UPTODATE消息:表明同步完成
REVALIDATE消息:根据Leader的REVALIDATE结果,关闭待revalidate的session还是允许其接受消息
SYNC消息:返回SYNC结果到客户端,这个消息最初由客户端发起,用来强制得到最新的更新。
Zab: Broadcasting State Updates
Leader给所有的follower发送一个PROPOSAL消息。
一个follower接收到这次PROPOSAL消息,写到磁盘,发送给leader一个ACK消息,告知已经收到。
当Leader收到法定人数(quorum)的follower的ACK时候,发送commit消息执行。
如果leader以T1和T2的顺序广播,那么所有的Server必须先执行T1,再执行T2。
如果任意一个Server以T1、T2的顺序commit执行,其他所有的Server也必须以T1、T2的顺序执行。
在新的leader广播Transaction之前,先前Leader commit的Transaction都会先执行。
在任意时刻,都不会有2个Server同时有法定人数(quorum)的支持者。
这里的quorum是一半以上的Server数目,确切的说是有投票权力的Server(不包括Observer)。
总结
推荐阅读:
【125期】举例说明消息队列应用场景及ActiveMQ、RocketMQ、Kafka等的对比
微信扫描二维码,关注我的公众号
朕已阅 