
大佬在线复盘:我在训练DALL·E时犯过的错

大数据文摘授权转载自夕小瑶的卖萌屋
作者:jxyxiangyu
在写了一周的业务代码后,沏一杯绿茶,总算可以有时间看看鸽了一个月的素材了。

好的,小伙伴们,废话不多说,今天我们将跟随 Boris Dayma 大佬,看看他在训练 DALLE-Mega 时遇到的一系列问题。
据这位老哥说,为了训练这个 3B 大小的模型,使用了一个 TPU v3 pod-256(=256 块 TPU v3)。
在写惯了业务代码,用多了 0.1B 的 bert-base 的我们,今天也来瞧瞧这些神仙大模型的训练方式。
DALL·E
DALL·E 是 OpenAi 去年推出的图像生成模型,它可以根据一句文本(caption)生成现实世界中不存在的图像。
比如牛油果形状的扶手椅、穿着芭蕾舞短裙遛狗的萝卜等。
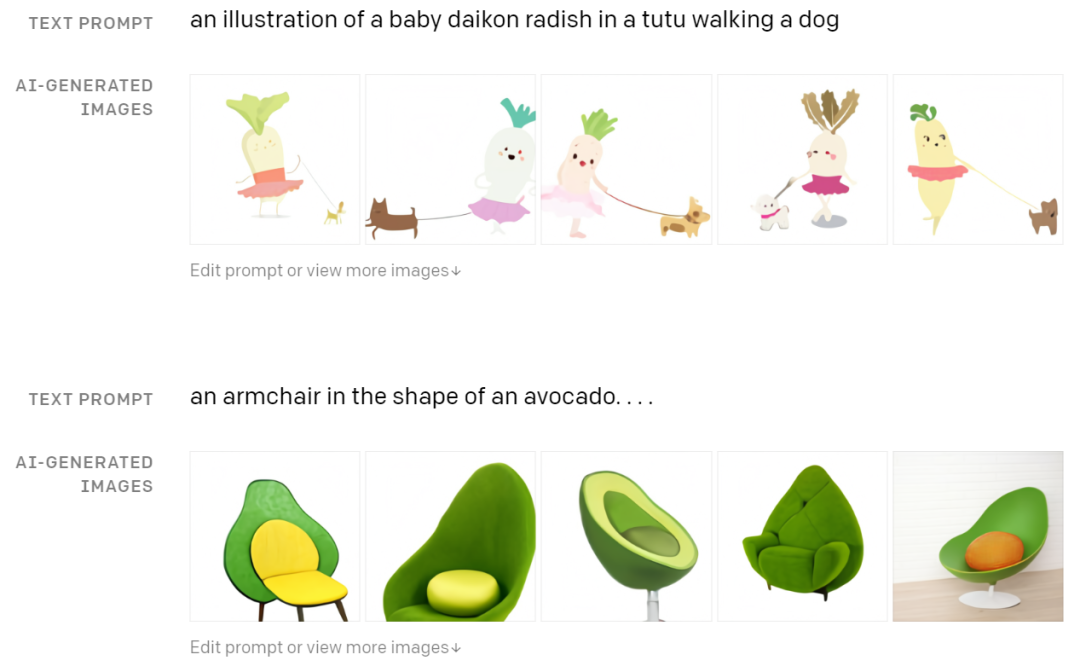
▲DALLE结果展示
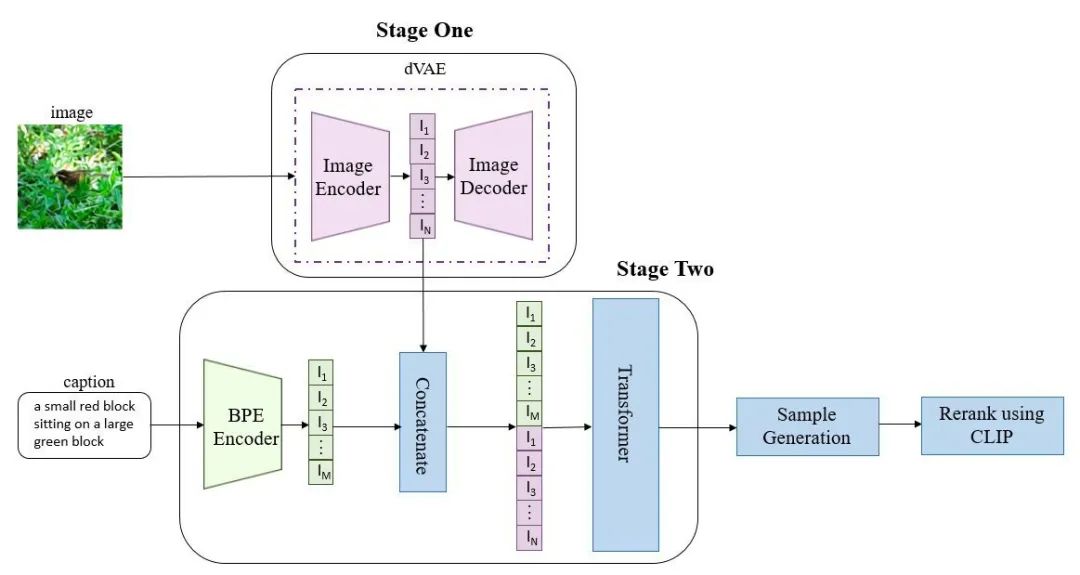
▲DALLE模型结构图
如上图所示,DALL·E 的训练过程可以分为两步:
为减小高分辨率图片(256X256)的计算量,将图片经过一个自编码模型 dVAE ,压缩得到(32X32)的图片,我们取 dVAE 的 encoder 的输出隐向量(32X32X8192)作为压缩的图片 token; 将文本经过编码器编码后的文本 token 和图片 token 拼接,送入 transformer 进行自回归训练。
DALL·E Mega 的训练之路
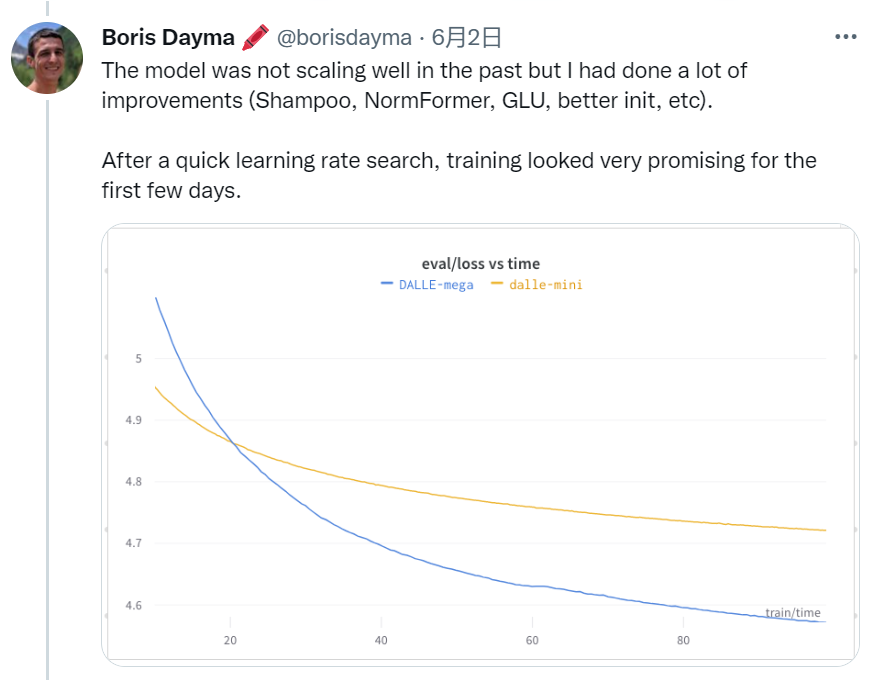
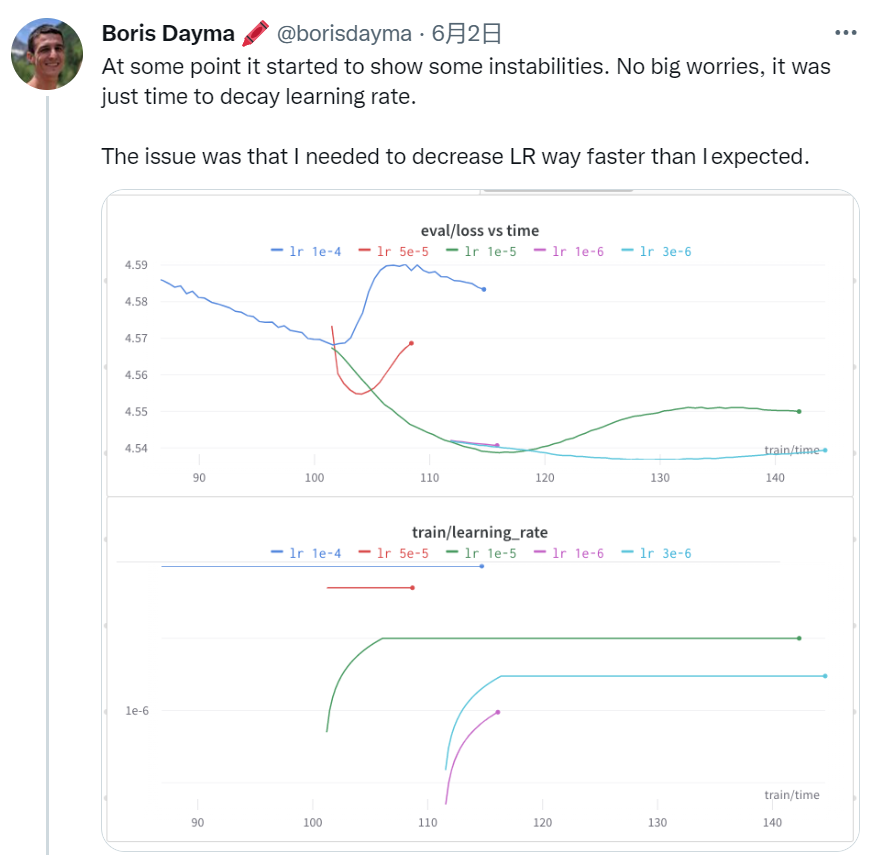

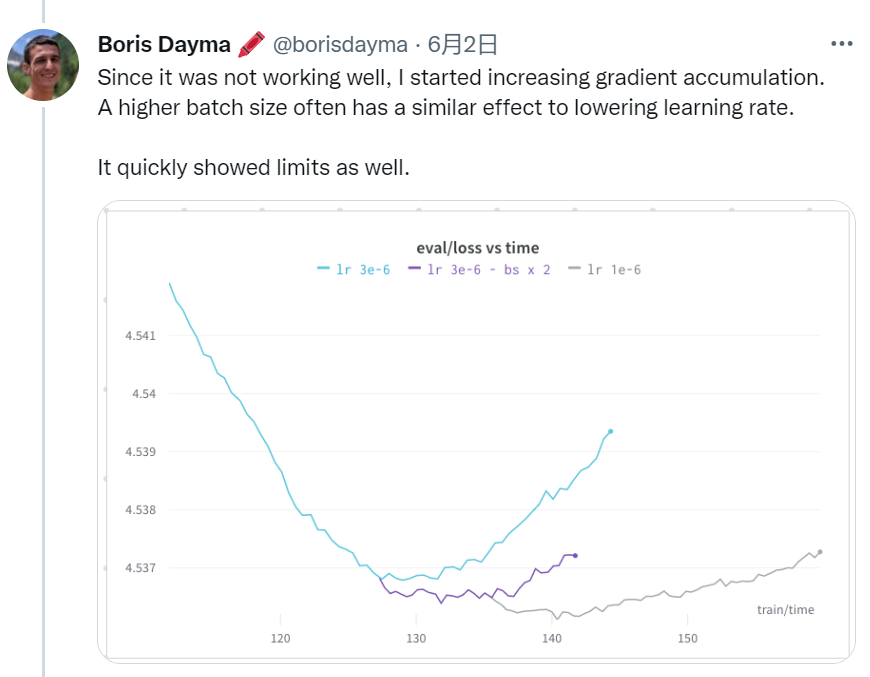






https://wandb.ai/dalle-mini/dalle-mini/reports/DALL-E-Mega-Training-Journal--VmlldzoxODMxMDI2
总结

评论