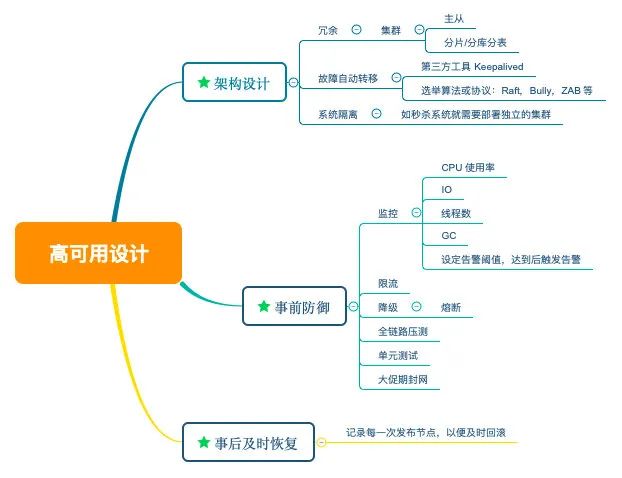
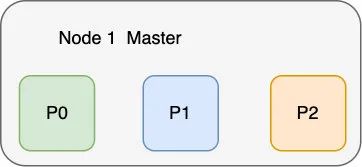
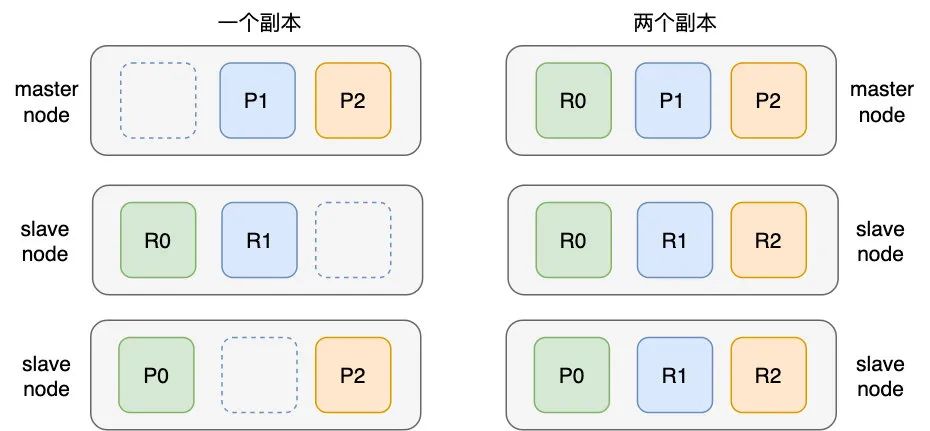
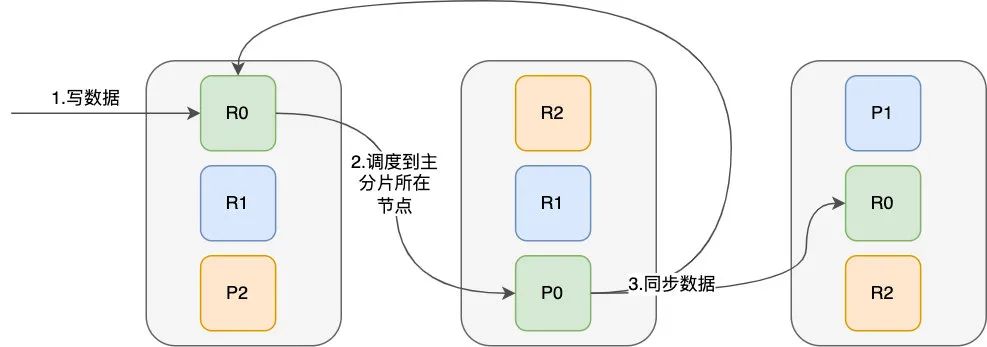
再来看一下 ES 是如何实现高可用的,在 ES 中,数据是以分片(Shard)的形式存在的,如下图所示,一个节点中索引数据共分为三个分片存储。但只有一个节点的话,显然存在和 Redis 的主从架构一样的单点问题,这个节点挂了,ES 也就挂了,所以显然需要创建多个节点一旦创建了多个节点,分片(图中 P 为主分片,R 为副本分片)的优势就体现出来了,可以将分片数据分布式存储到其它节点上,极大提升了数据的水平扩展能力,同时每个节点都能承担读写请求,采用负载均衡的形式避免了单点的读写压力。
ES 的写机制与 Redis 和 MySQL 的主从架构有些差别(后两者的写都是直接向 master 节点发起写请求,而 ES 则不是),所以这里稍微解释一下 ES 的工作原理 首先说下节点的工作机制,节点(Node)分为主节点(Master Node)和从结点(Slave Node),主节点的主要职责是负责集群层面的相关操作,管理集群变更,如创建或删除索引,跟踪哪些节点是集群的一部分,并决定哪些分片分配给相关的节点,主节点也只有一个,一般通过类 Bully 算法来选举出来,如果主节点不可用了,则其他从节点也可以通过此算法来选举以实现集群的高可用,任何节点都可以接收读写请求以达到负载均衡的目的 再说一下分片的工作原理,分片分为主分片(Primary Shard,即图中 P0,P1,P2)和副本分片(Replica Shard,即图中 R0,R1,R2),主分片负责数据的写操作,所以虽然任何节点可以接收读写请求,但如果此节点接收的是写请求并且没有写数据所在的主分片话,此节点会将写请求调度到主分片所在的节点上,写入主分片后,主分片再把数据复制到其他节点的副本分片上,以有两个副本的集群为例,写操作如下