
binlog真的是银弹吗?有些时候也让人头疼
点击上方蓝字“设为星标”
大家好,我是架构摆渡人。这是实践经验系列的第三篇文章,这个系列会给大家分享很多在实际工作中有用的经验,如果有收获,还请分享给更多的朋友。
binlog 用于记录用户对数据库操作的SQL语句信息,同时主从复制也是依靠binlog来实现的,由此可见binlog的重要性。

在业务中的使用场景
binlog除了数据库本身使用它实现一些功能,在业务中我们也会经常依靠binlog实现各种需求。
数据异构
基于binlog的数据异构是用的最多的一个场景,可以通过监听binlog将数据异构成其他维度,方便查询。
比如多表聚合成一张宽表,搜索相关的异构到ES中,订单可以异构成买家视角,卖家视角等等诸多场景。
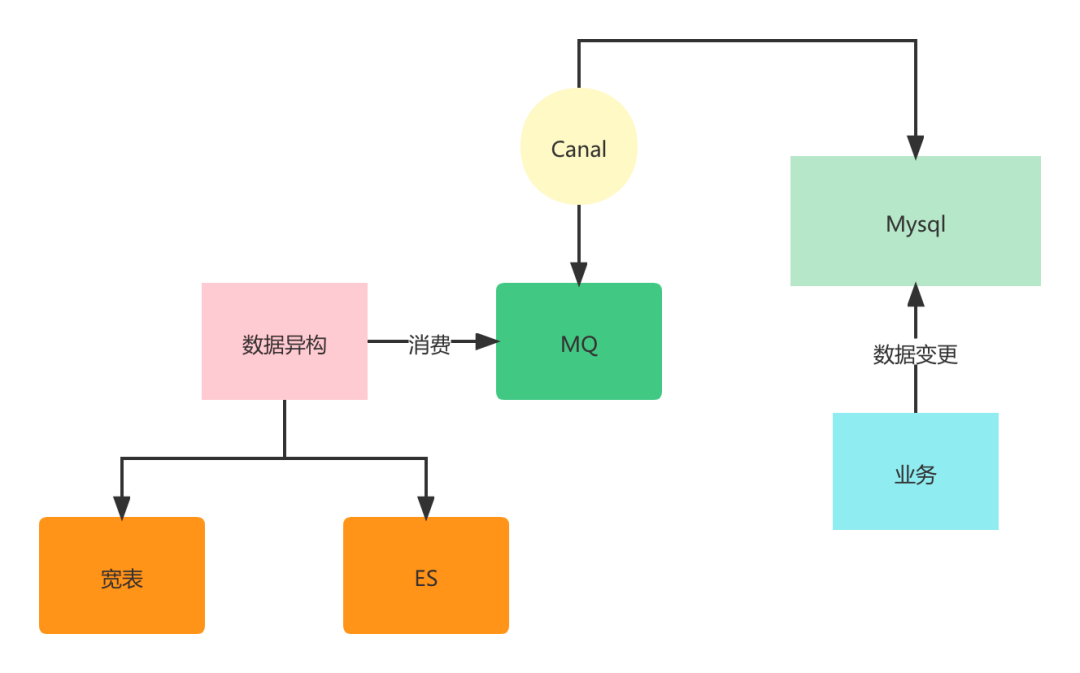
缓存失效
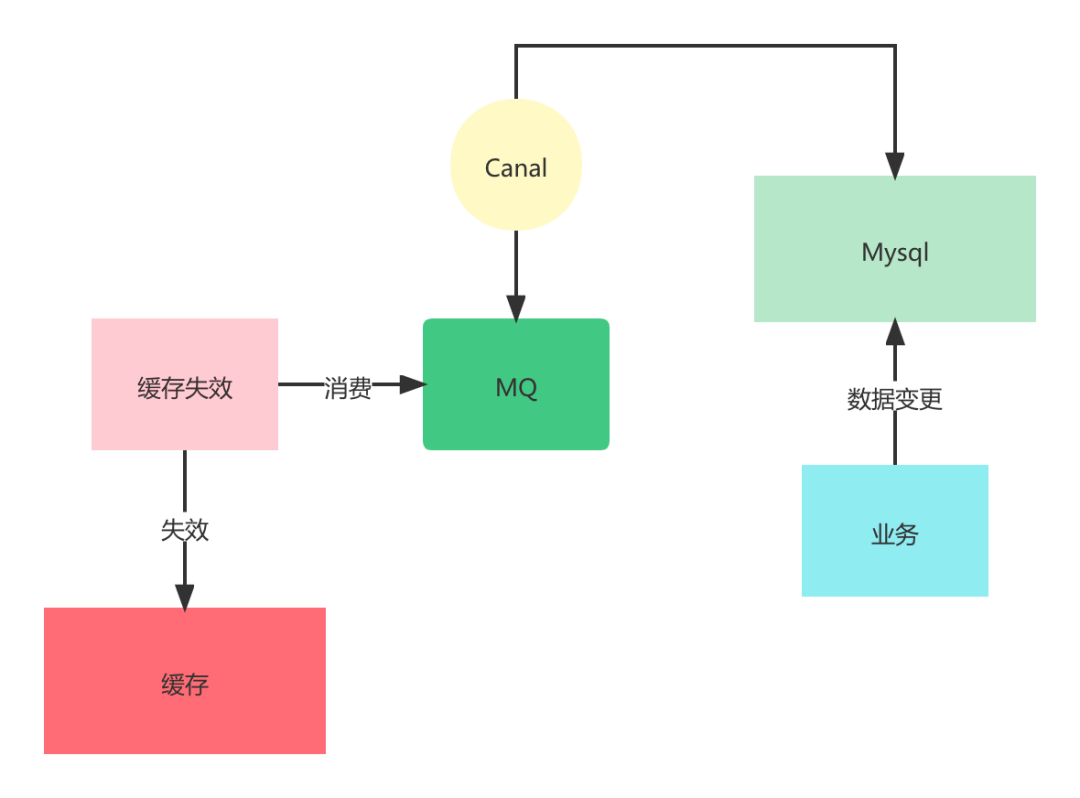
对于高并发的互联网业务,数据库往往是最后的瓶颈,用缓存来提高性能是最常见的一种优化手段。也就是在访问数据库之后会将数据放入一份在缓存中,下次请求的时候直接从缓存取来提高响应速度和减少对数据库的压力。
一提到缓存,大家立马能想到的问题就是缓存和数据的一致性要怎么保障?这种还是得结合业务场景来讲,本身能用缓存的业务基本上还是能够接受短暂的不一致问题,也就是并非强一致性。
最常见的方式就是在操作数据后,立马对缓存进行操作。这样的方式意味着业务代码中都是这种缓存失效的代码,当然也有封装成注解的形式,让使用更加便捷。
binlog在这个场景中也能产生重大作用,可以基于binlog的变更来淘汰对应的缓存,而且可以和业务代码解耦,为我们解决缓存数据一致性问题多提供了一种方案。
数据分发
数据分发也是一种比较常见的业务场景,当很多下游依赖上有的数据,常见的实现方式有下面几种:
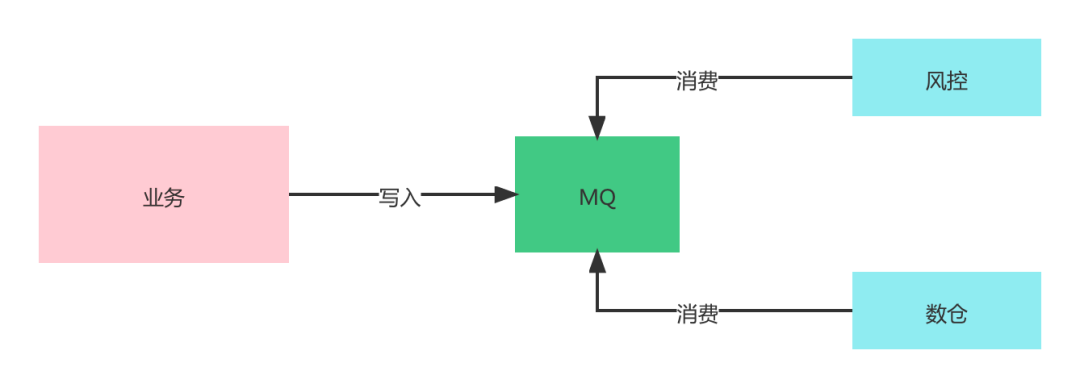
代码中通过消息进行数据分发
如果自己在代码中通过消息将数据分发出去,就会比较被动。因为一旦有字段变更,有下游想要其他的数据,你都得需要改动代码来满足下游的需求,基本上不可取。
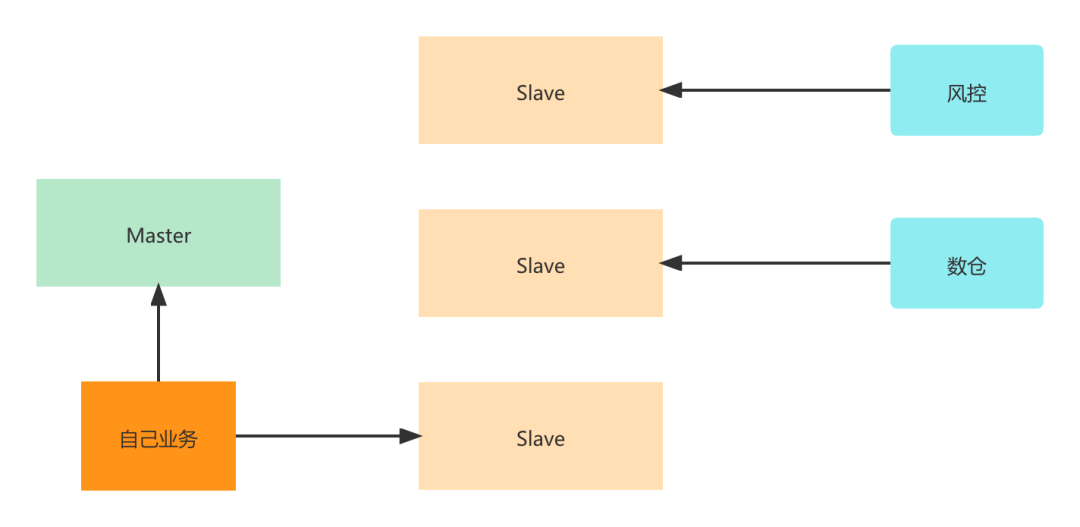
多搭建几个从节点,给下游直接使用从节点
这种方式如果是在一个部门内还好点,如果是跨部门的,本来权限就管的比较严,不可能让其他部门直接连接你们的数据库,而且增加从节点的成本也是你们自己的,所以这种方式基本上也不会用。
让下游消费binlog自己构建数据
下游需要使用数据,那么就用下游自己的数据库,用什么库都跟你没关系。我们只需要通过中间件将binlog发布出去,哪个业务方需要数据就自己消费,自己存储即可。
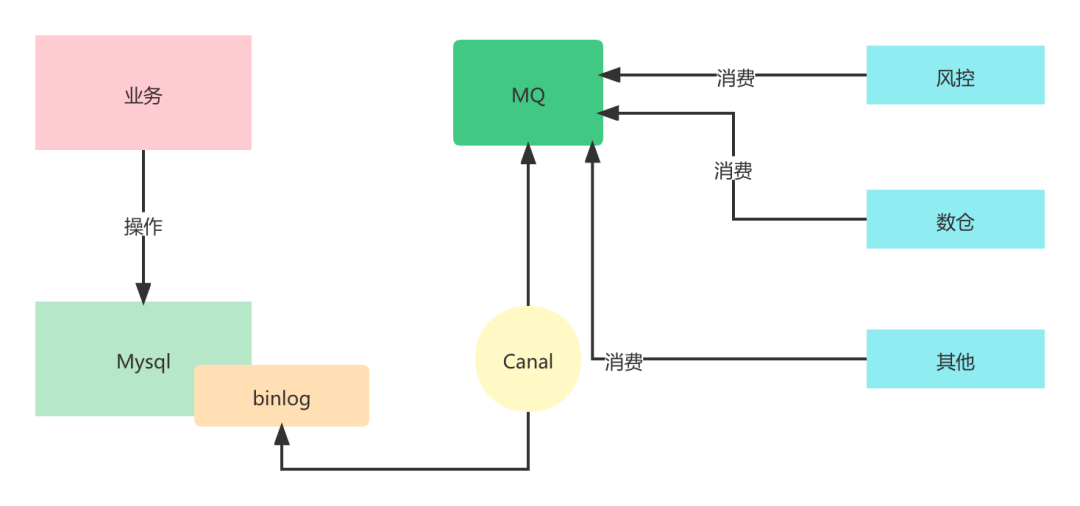
这种方式我们既不用改业务代码,也不用申请数据库增加我们的成本,是一种完全解耦的方式,但是这种方式也是有弊端的,请继续往下看。
给业务带来的风险点
字段变更
如果上游的字段发生了变更,比如把name换成了username,对消费binlog的下游来说,这个字段就有可能影响了现有的逻辑,导致取值错误。不过在实际工作中这种场景还是比较少的,一般都不会去随意变更字段名称,也不能说完全没有变更的情况。
数据变更
字段变更带来的影响相对来说较小,最让人头痛的就是数据的变更了。特别是数据量特别大的表进行数据变更的时候,比如你的表有10亿条数据,当然是分库分表的。然后有个字段需要重新清洗下数据,也就是update某个字段。看上去对业务没有任何影响,其实对下游是有影响的。
如果数据清洗过快,binlog就会很多,下游消费不过来就会出现消息堆积,影响正常的业务逻辑,因为下游都依赖了binlog做业务。
所以在这种场景下,大家有数据清洗的需求,一定要考虑到对下游的影响,本来你洗数据可能一天就洗完了,但是下游扛不住,可能需要10天才能慢慢洗完。但是感觉不合理啊,我自己的表变更还要问问别人,我能洗这么快么?
解决方案
对于字段名称尽量不做变更,非得变更的话得提前和下游沟通好,让下游消费2个字段,如果哪个有就消费哪个,这样你改名称之后就不会影响下游的逻辑。
对于数据清洗之类的导致大量binlog场景,最简单的就是控制清洗速度,始终保持下游能够接受的程序去清洗,缺点就是时间会比较长。
另一种方案就是按需订阅,比如有的场景你清洗的这个字段下游压根就不消费,这个时候可以在消息投递处进行处理,按需进行消息的投递,比如对消息打Tag, 下游根据Tag进行消息过滤。
或者下游消费时直接过滤,这样速度也是很快的。
如果你的改动下游真的要感知,并且速度还不能慢,要赶时间,那么只能让下游扩容了。
大家好,我是从古代穿越过来的美男子:架构摆渡人。我将把我的武功秘籍全部传授与你们,觉得有用请分享给身边的朋友。来个三连吧,感谢各位!另外我还在B站录制了《真实订单业务,亿级数据带你实战分库分表》的实战课程,记得去学习哦!
点击阅读原文直达主页