
【Python Flask 实战】从开发到云服务部署,动手开发一个自己的电影网站
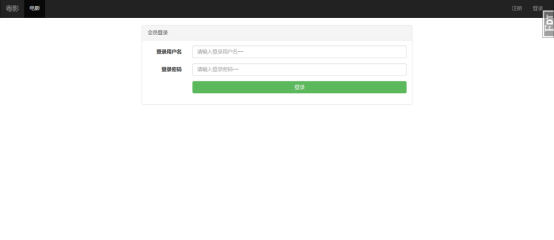
项目预览
学习完flask开发web程序的课程后,我就想自己动手做一个项目练练手
于是又经过了一番学习,终于做出来了一个小项目——个人电影网站
大概是这样的
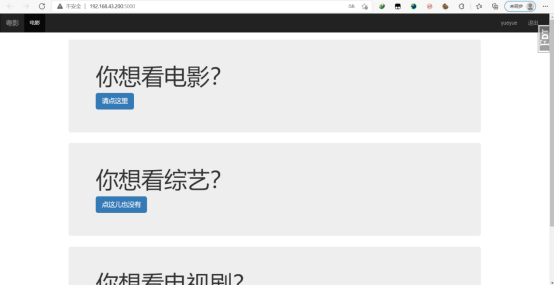
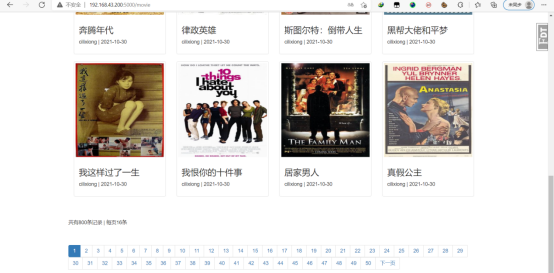
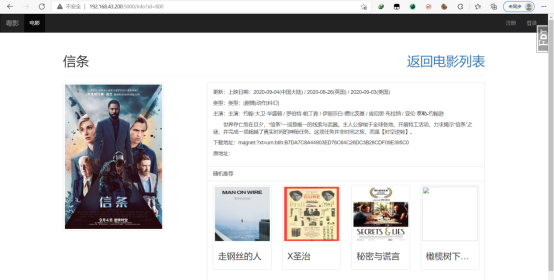
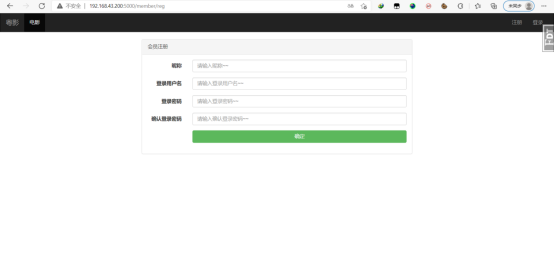
开发工具大致介绍
建议用anaconda+pycharm来开发,anaconda自带有conda工具可以进行虚拟环境的隔离
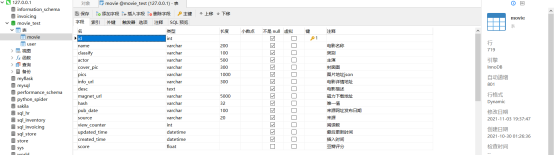
网站的数据库用的是mysql,核心就是两张表:用户表和电影表

这个网站的前端功能有主要有三块:展示电影信息、注册、登录
前端页面主要根据bootstrap的模板进行编写。包括导航条、分页、缩略图
后端由flask编写,数据库通讯用的是flask-sqlalchemy和mysqlclient,好处是可以通过ORM的方式与数据库交互。此外还用到了flask-sqlacodegen,它可以根据数据库的表结构自动生成我们的表对象
电影的具体信息则通过爬虫从“磁力熊“https://www.cilixiong.com/movie/网站爬取
为了使得web服务开启任务和爬虫任务的分离,还用到了flask-script,它可以通过自定义命令来操作我们的flask程序。
为了调试程序更加清晰一点,我还使用了flask_debugtoolbar 这个可装可不装。
Web服务器就用uwsgi
项目代码架构
下面介绍一下程序的架构
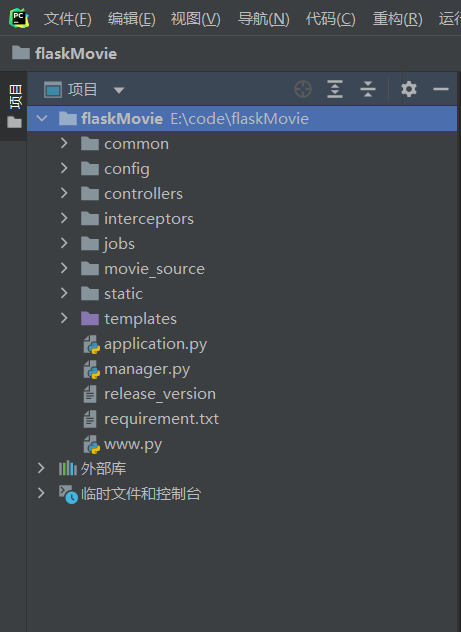
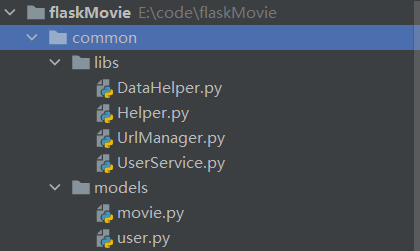
一:Common文件夹,存放公共的东西。
里面有两个文件夹,一个是libs,存放公共的函数,例如专门处理时间的、专门管理url链接的、专门处理用户注册登录相关的函数
还有一个是models,所谓MVC框架的M层,这是专门存放数据库表结构,一个.py代表一个数据库表
二:config文件夹,存放一些配置信息,例如数据库的信息,还有本地的ip地址之类的
里面有俩.py文件,一个是本地开发环境的配置信息,一个是生产环境的配置信息(将来部署到linux的机器上用得着)
三:controllers文件夹,也就是所谓MVC框架的C层,存放一些路由函数,也就是后端的核心功能,处理前端的请求,返回给前端相应的数据。
有两个py文件,index文件是页面相关的路由函数,处理展示电影信息、分页等请求;member文件是会员相关的函数,处理登录、注册等请求
四:interceptors文件夹,用于存放拦截器相关的文件,
每当请求一个url之前,我们都希望先判断用户是否处于登录态,这时候我们就需要一个拦截器来实现这个判断的逻辑,这部分代码存放在Auth.py文件
另一个文件是错误拦截器,比如发生404错误时,我们就可以自定义函数去返回一些特定内容。
五:jobs文件夹,存放爬虫相关的代码
其中有个子文件夹tasks,存放具体的任务代码,例如获取电影资源的movie.py
Launcher.py文件是启动任务的入口文件
六:movie_source文件夹,存放爬虫获取的电影信息资源
里面的每一个文件夹代表某一日的运行结果
七:static文件夹 放一些静态文件
Js文件夹放置一些处理网页请求的js文件,plugins文件夹则是bootstrap的依赖文件
八:templates文件夹 放置各个页面的html代码,也就是MVC框架中的V
结构如下,具体的细节后面讲
九:application.py文件:放置核心的flask对象,数据库对象等
十:manager.py文件:项目的入口文件
十一:www.py文件:负责蓝图、全局函数的注册
十二:requirements.txt文件 :整个项目需要的包依赖
好啦,这就是项目代码组织架构的介绍了,接下来就分模块来介绍代码的编写过程!
配置文件
首先我们先来看一下本地开发环境的配置文件
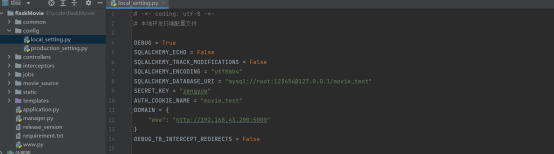
我是根据flask-sqlalchemy官网的提示配置的,具体的意思可以看下图
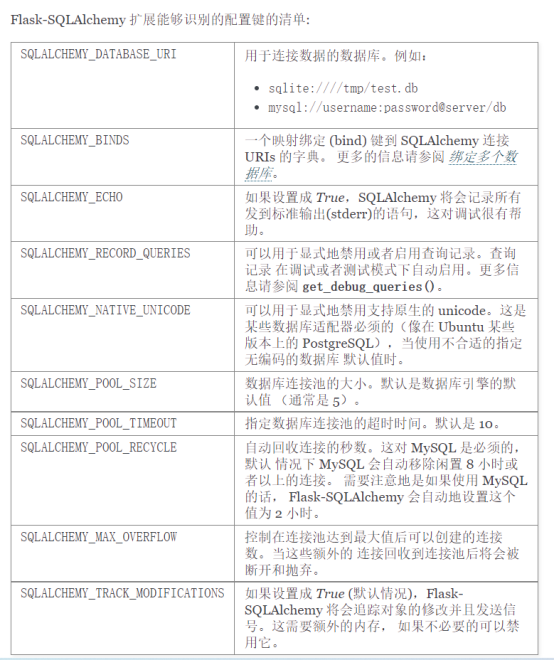
需要说明的是AUTH_COOKIE_NAME,它是cookies的名称,大家可以自定义
然后DOMAIN则是url的头部,它取决于你自己的本地ip地址,查出自己的本地ip后替换一下就行了。
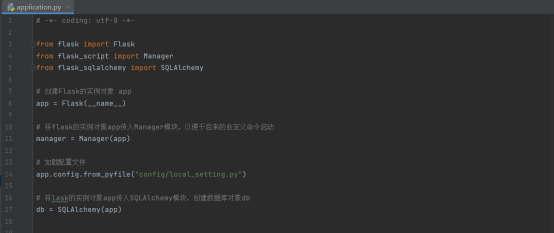
Application.py文件
这个文件里面放着一些项目的核心对象,例如flask的实例化对象,还有SQLAlchemy的数据库对象,并且引入了flask-script的Manager为自定义命令启动做准备
Common的libs文件夹
这个文件夹里面放有一些穿插在整个项目代码里的一些公用模块
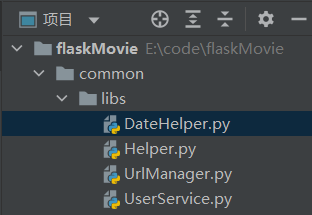
接下来一一介绍
首先是 DateHelper.py模块,里面就一个函数,功能就是返回一个格式化的时间字符串
格式是:年月日时分秒

之后是Helper.py模块,里面会引用flask的jsonify,也就是json序列化的函数,还有就是render_template, 我们对它进行封装,构造一个自己的渲染函数,还有我们的全局变量g
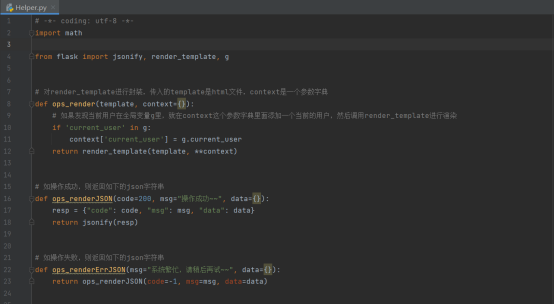
里面还有一个专门用于处理分页的函数,根据后端传来关于页面的参数,构造分页的信息,例如总共有多少分页?是否有前一页?这些信息以一个字典的形式返回给调用它的后端
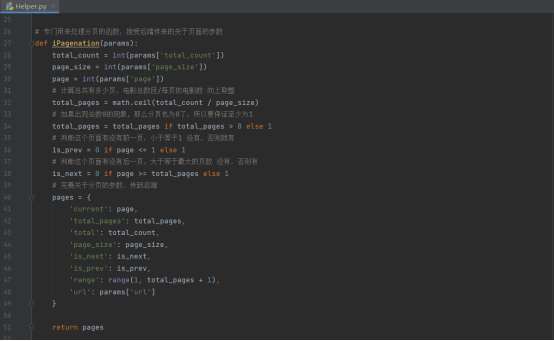
然后是UrlManager.py模块,功能就是根据配置文件的信息来构建这个项目会用到的一些url,包括静态文件引用的url,这样可以实现对项目url的统一管理,避免使用一些相对路径造成url链接的混乱。
此外还有一个功能,负责项目的版本信息管理,在开发模式中默认用年月日时分秒来作为版本信息,这样我们在调试过程中我们就可以将版本信息与cookies结合,不断更新。负责浏览器会将旧的cookies信息保存起来,不利于我们的调试。
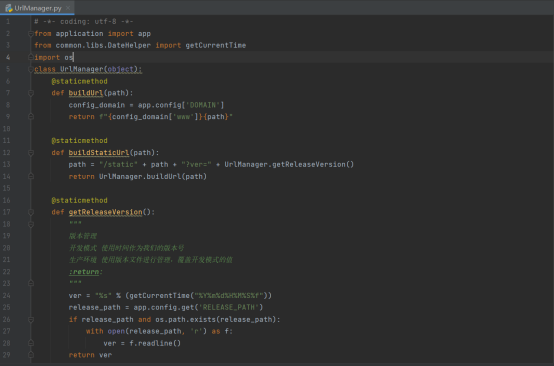
最后就是我们的UserService.py模块,顾名思义就是有关于用户的一些功能函数
geneAuthcode函数,根据数据库里面的用户信息字段,做一个加密字符串,主要用于构造cookies信息。
genePwd函数,根据传递进来的pwd密码以及salt值再进行加密,生成一个最终的密码
geneSalt函数,负责生成salt值
本文介绍项目用到的数据库相关内容,我自己用的是navicat for mysql这个数据库可视化这个软件,其它软件的操作过程也大同小异
创建数据库以及表结构
首先我们来创建数据库
CREATE DATABASE `movie_test` DEFAULT CHARACTER SET = `utf8mb4`;
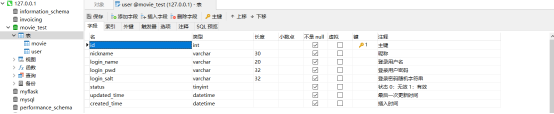
然后我们创建两个表,movie表和user表
CREATE TABLE `user` (
`id` int UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键',
`nickname` varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '昵称',
`login_name` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '登录用户名',
`login_pwd` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '登录用户密码',
`login_salt` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '登录密码随机字符串',
`status` tinyint NOT NULL DEFAULT 1 COMMENT '状态 0:无效 1:有效',
`updated_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后一次更新时间',
`created_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '插入时间',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `uk_login_name`(`login_name`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '用户表' ROW_FORMAT = Dynamic;
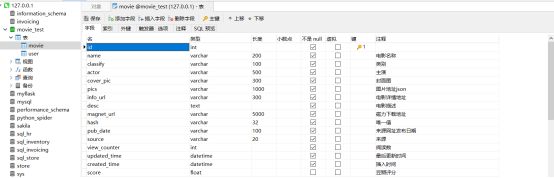
CREATE TABLE `movie` (
`id` int UNSIGNED NOT NULL AUTO_INCREMENT,
`name` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '电影名称',
`classify` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '类别',
`actor` varchar(500) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '主演',
`cover_pic` varchar(300) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '封面图',
`pics` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '图片地址json',
`info_url` varchar(300) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '电影详情地址',
`desc` text CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '电影描述',
`magnet_url` varchar(5000) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '磁力下载地址',
`hash` varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '唯一值',
`pub_date` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '来源网址发布日期',
`source` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '来源',
`view_counter` int NOT NULL DEFAULT 0 COMMENT '阅读数',
`updated_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
`created_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '插入时间',
`score` float NULL DEFAULT NULL COMMENT '豆瓣评分',
PRIMARY KEY (`id`) USING BTREE,
UNIQUE INDEX `idx_hash`(`hash`) USING BTREE,
INDEX `idx_pu_date`(`pub_date`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 801 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci COMMENT = '影视数据表' ROW_FORMAT = Dynamic;
在navicat执行这些语句后,表结构就建立完毕
使用flask-sqlacodegen生成表对象
在pycharm的终端命令窗口输入一下命令并执行
flask-sqlacodegen "mysql://root:123456@127.0.0.1/movie_test" --tables movie --outfile "common/models/movie.py" --flask
flask-sqlacodegen "mysql://root:123456@127.0.0.1/movie_test" --tables user --outfile "common/models/user.py" --flask
就会发现在common的models下多了两个.py文件,这就是数据库两张表生成的对象
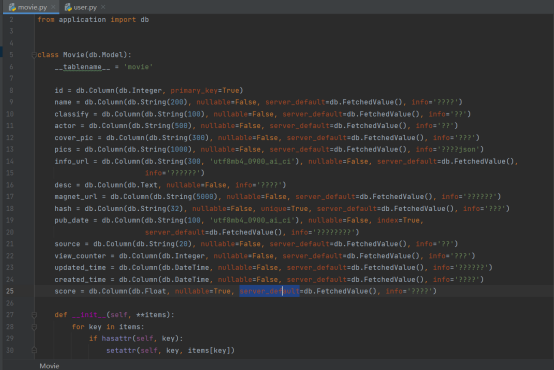
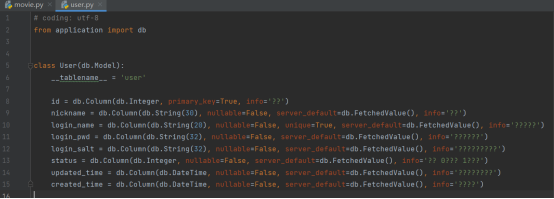
需要说明的是,文件内容只需要保留,class部分的内容,删除原来的引用,手动加入db变量,此外,在movie.py中加入了一个初始化的方法,它可以帮助我们在后面爬取数据的过程中直接将数据存入库内。
通过数据库对象反向生成表结构
上面的过程是通过数据库表结构生成对象,那么反过来操作也是可以的
在manager.py模块中,我们就可以编写相关的命令
从flask-script引入command
之后以装饰器的形式装饰这个create_all函数,这样一来我们就可以把这个被装饰的函数添加到manager的执行命令中
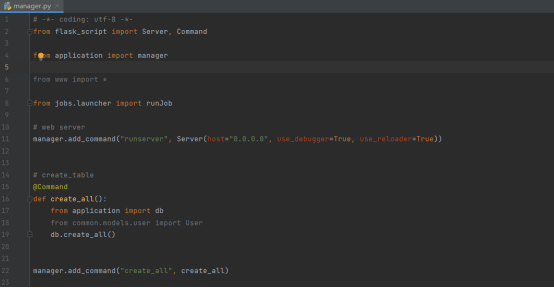
在终端命令行里面执行:python manager.py 就会发现有create_all的提示信息,如下图所示
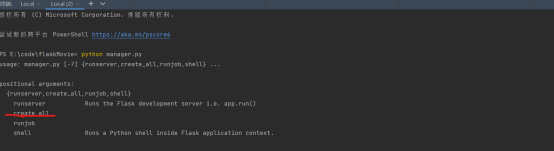
如果我们把数据库的表结构删除,我们只需要再次执行python manager.py create_all
那么程序就会自动找到我们的models文件夹,把里面存放的表对象映射成为数据库内的表
(因为在上面的数据库对象的类里面继承了(db.Model))
将爬虫任务与web服务启动分离
在一般的flask项目开发的过程中,往往就是通过app.run()这种方式启动整个项目,但是爬虫任务与web项目的启动,逻辑上是独立的,因为web服务是一直启动的,爬虫任务可不用一直爬
所以我们就用前面讲到的flask-script中的manager来自定义爬虫任务的启动方式
爬虫任务的核心代码
(前言:对目标网站的结构分析,可以参考这篇文章,限于篇幅,本文将不会介绍如何对爬虫的具体内容进行讲解)
这部分代码安排在jobs的task目录下的movie.py中
我们可以定义一个JobTask的类,然后对爬取的网站和爬取的分页数目等信息放入初始化函数内
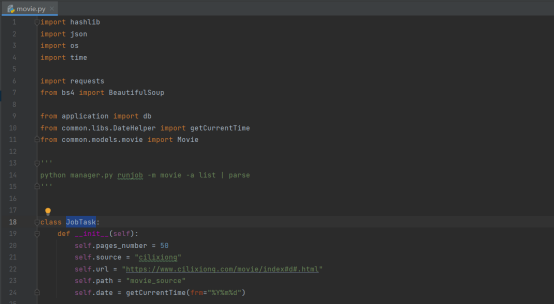
然后定义一个启动方法,该启动方法从终端获得参数,如果是“list“就执行爬取-解析两项任务,如果是”parse“就执行单纯执行解析任务

由于网络爬虫的不稳定性,我们会将爬取的网页内容加载到本地文件夹中,而后进行解析,实现爬取和解析的解耦,所以在类中设置了一些确保目录存在的函数,另外还封装了获取html代码的函数以及保存到文件的函数以便后续调用,避免了代码的重复。
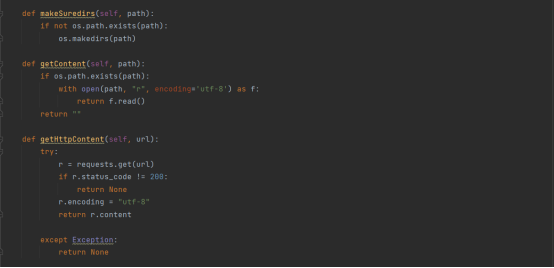
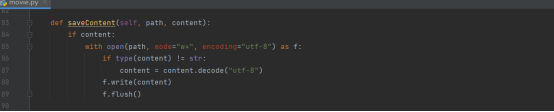
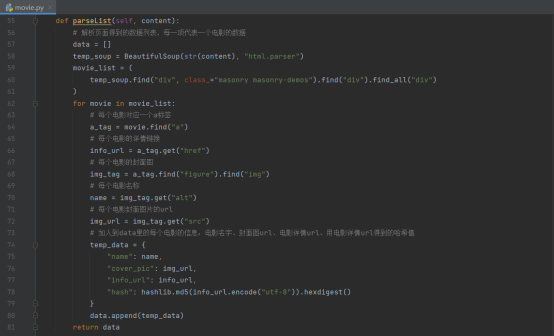
接下来介绍解析网站页面的函数,它通过传递进来的html代码,也就是content,解析相应内容,将解析后得到的有用信息以一个列表的形式传递出去,该列表的每一个元素都是一个字典,一个字典就代表一个电影的具体信息。
现在我们来介绍获取页面有效信息的函数,实现它定义了一些数据的存放路径,它把页面的每一页的html代码都放到list目录中,把每个电影的详情信息的html代码都放到info目录中,把每个电影的详情信息都放到json目录下。
第一个for循环代表得到每一个页面的html内容,并且将其存放到list文件夹下
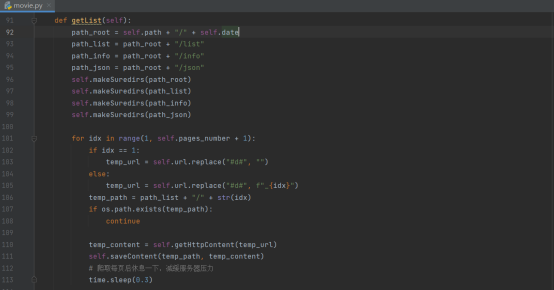
第二个for循环代表从list文件夹下读取每一页的html代码,并且解析页面的html代码,从每个页面中获取全部的电影信息,并且将这些电影信息都保存到相应的info和json文件夹中
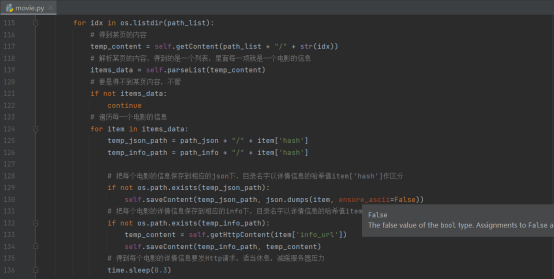
需要说明的是,代表电影信息的每个文件名,都用了hash加密。因为电影名字可能有重复,但是结合了电影名称和详情页面地址的字符串解析hash加密,就可以保证唯一性
如下图所示
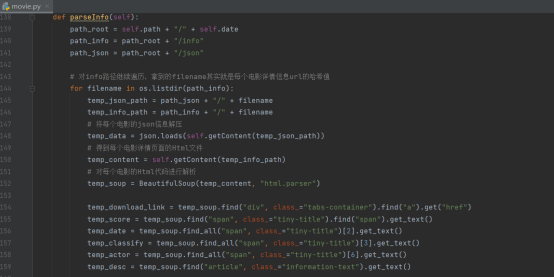
然后就是最核心的解析每个电影具体页面的函数
该部分的功能是读取遍历info目录和json目录下每一个文件,读取每个电影具体信息的html代码
读取后解析具体页面的有效信息,比如磁力链接、豆瓣评分、上映日期、主演等
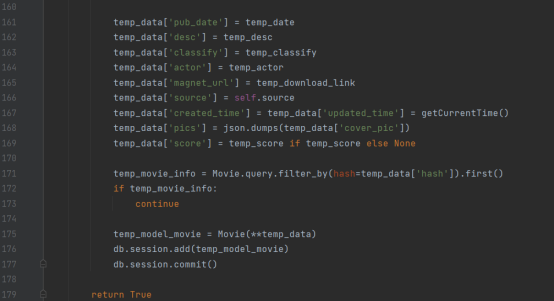
拿到这些信息后与已经获取到并且存在json目录下的文件内容,例如电影名称、封面图地址等结合起来,就能形成一个电影在数据库表结构中的完整信息。
之后就是进行一些判断,看看数据库中有没有存在这条电影的信息(利用前面提到的hash加密的唯一性),如果有就略过,如果没有就通过数据库ORM对象,向数据库添加信息
将JobTask添加到自定义的方法中进行启动
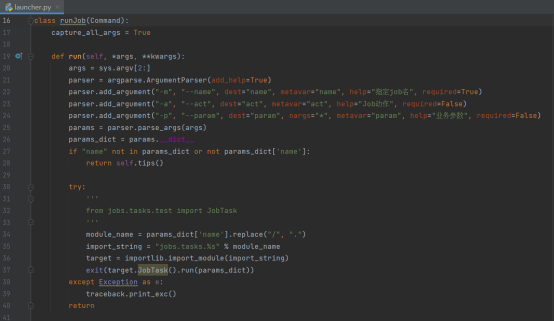
我们编写一个launch.py文件,作为统一的启动入口,调用刚才提到的movie文件中的JobTask类,如果想换个网站爬取的话,我们也可以再编写一个类,然后再这个统一的入口文件中引入。
定义一个runjob类,它继承了flask-script的command类,这样它就可以作为自定义的启动目标了
启动的时候会调用run函数,我们只需要在run函数里面引入刚才提到的JobTask类就可以了
此外,我们还可以加一个方法用于命令输入错误时发出提示信息
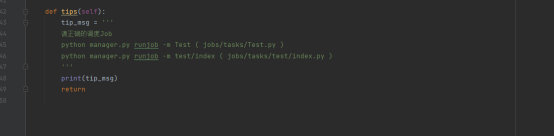
好了,现在我们就可以通过 python manager.py runjob -m movie 的方法来启动我们的爬虫程序了!
通用前端样式
在讲解登录和注册的前后端具体实现事前,我们先来介绍一下整个项目的前端页面都会继承的html模板,也就是导航条部分,导航条部分运用到了bootstrap的导航条模板,使用方法可以参照bootcss网站的文档
我们将整个通用的模板放在layout.html里面
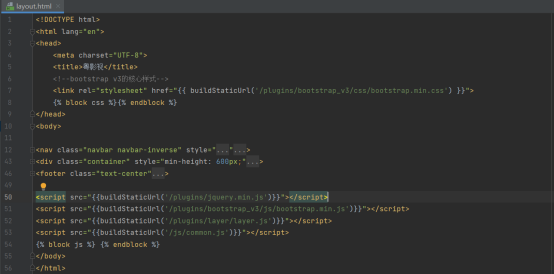
首先,我们在head区域内引入bootstrap的css样式,并且在body区域结束前,引入jquery依赖的js文件和bootstrap的js文件。我们还需要引入自定义的公用js,此外,还需要在最后面添加一个关于js的block的区域,这是为了给登录和注册功能留出属于它们自己的js空间。
公用的js如下。buildurl功能就是将传入的path路径和params参数重新组合一下
变成path?key1=value1&key2=value2的形式,alert功能就是接受一个回调函数,在一些操作(比如登录,注册)后,弹出一个窗格,并且执行回调函数
回调函数将会在登录和注册部分的js中传递过去。
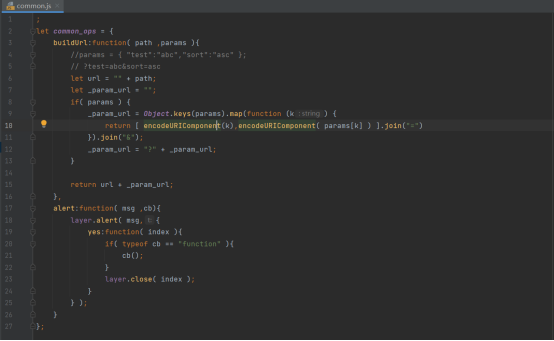
紧接着我们就在body区域内放置nav区域,它就我们的导航栏具体内容,其中最重要的就是设计好a标签的url链接。在我的项目中,我把“粤影“url链接设定为首页,把”电影“url链接设定为电影的缩略图页面,把”登录、“注册“也相应设置为对应的url。
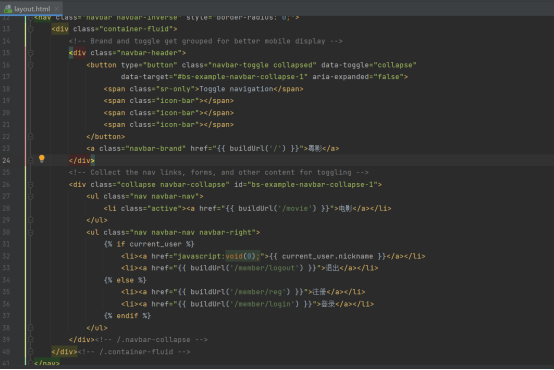
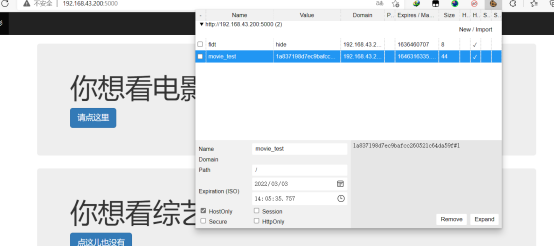
此外,我们需要判断一下是否已经登录。方法就是检查全局变量里的current_user是否存在,如果存在,显示的就不是“登录”、“注册“,而是对应的用户名和”退出“,如下图

最后就是footer区域

效果如下,它会在尾部显示

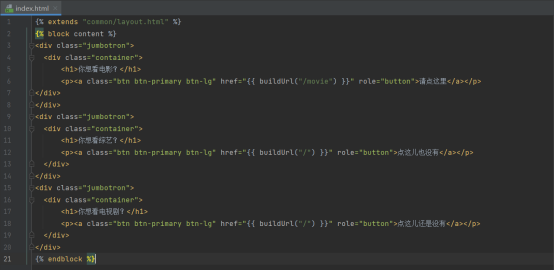
首页前端页面
这个页面主要用到了bootstrap的巨幕组件,用法参考bootcss网站
最重要的依然是a标签的链接设置,点击“电影“就可以跳转到电影分页的页面
由于我这个项目目前只爬取了电影,电视剧和综艺这两块还没有时间去弄,所以没有对应的内容
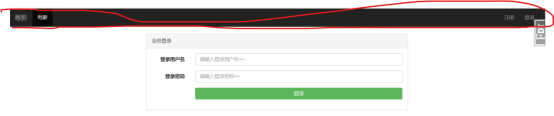
登录前端页面
这部分用到了bootstrap的“水平排列表单“组件
这个页面需要继承之前提到的layout.html,然后就是根据表单组件的格式,进行一些微调,bootstrap官网的示例来调整就ok了
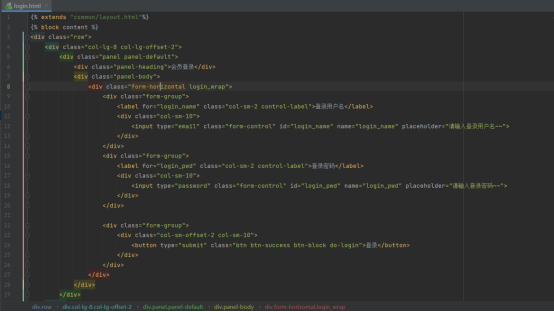
此外,我们还需要在底部引入登录模块的js
下面我们就来看看登录模块的js,它放在静态文件目录下
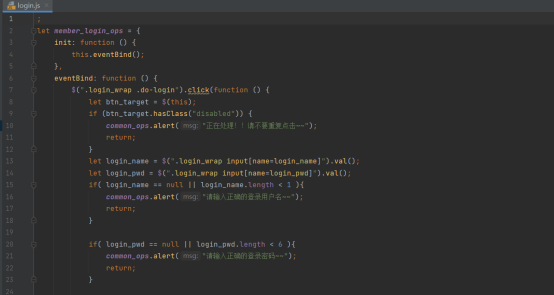
首先我们创建member_login_ops这个变量,在初始化方法内执行事件绑定方法
在事件绑定方法内,我们需要选取监听login.html的登录按钮
首先检查是否有“disabled“的类属性,如果有的话,就提示”不要重复点击“
然后取出对应表单数据,作一个初步的检查,例如检查是否为空、长度是否足够
检查完毕之后就添加一个“disabled“的类属性,防止重复操作
而后将数据以ajax请求的方式传到后端的相应函数中
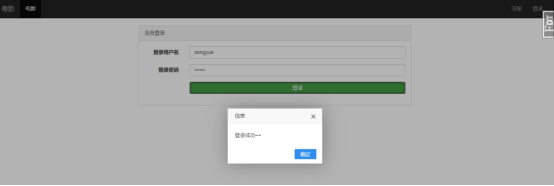
如果后端的校验也通过了,就返回一个200的状态码,并且执行回调函数并且在窗口中输出“登录成功“的字样
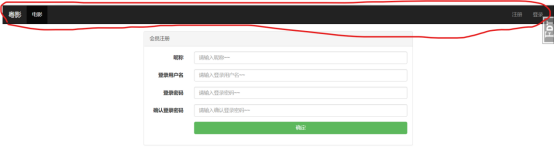
注册前端页面
在注册前端页面中,我们依然可以使用bootstrap的“水平排列表单“组件
在最后js的block中依然要引入相应的js文件
接着我们就来看对应的注册功能的js
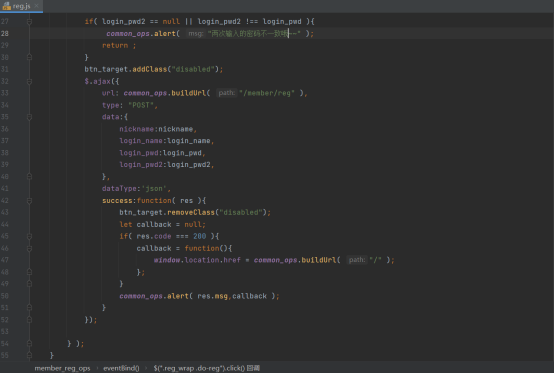
大致结构和登录部分的差不多,依然是执行绑定事件,监听注册按钮那一套
对从表单提交过来的信息进行初步的验证后,就将传过来的用户名、密码等信息以ajax请求的方式发送给后端的相应函数,如果后端验证成功了,会返回状态码200的信息,这时候执行提示方法就ok了
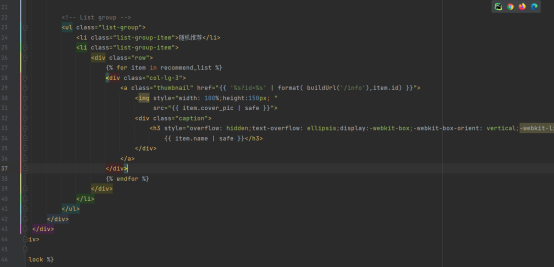
电影缩略图页面
这个页面首先还是得继承一下通用的模板
在这个页面中,设置了按热度和日期排序的两个a标签,点击相应按钮就会传递不同的参数到后端,进而返回不一样的页面
在缩略图区域内,我使用的依旧还是bootstrap的缩略图插件
在区域内,首先会判断是否有从后端传来的data,也就是电影信息,如果有,就挨个遍历添加到相应的缩略图区域内
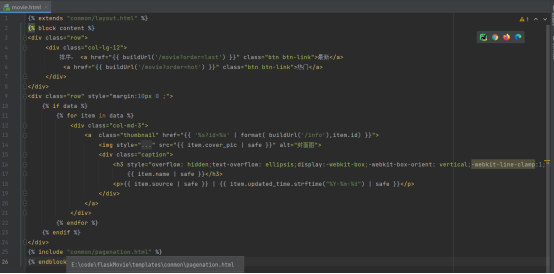
其中,我设置了col-md-3 代表一行显示4个,因为bootstrap默认将区域分成12列,col-md-3每3列为一个单位,共4个
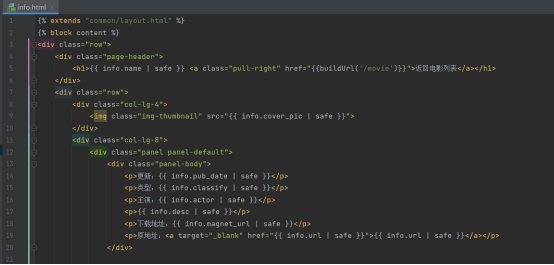
电影详情信息页面
电影详情页面中,也就是从后端拿数据,然后在相应区块展示相应的信息
需要特别说明的就是添加了随机推荐的模块,原理也很简单,直接在后端随机选一些电影传递到前端,进行展示
电影信息相关后端
在介绍后端模块之前,先简要介绍一下该模块所引入的东西
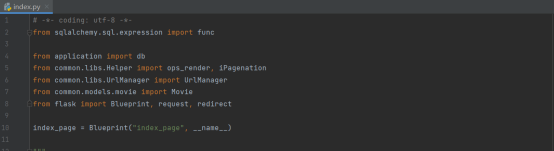
在这个模块中,将引入sqlalchemy中sql表达式中的func模块,引入之后,我们就可以不适用具体的sql表达式,而是用它封装好的函数对注册进db对象的数据表models进行操作。相应地,把models引入进来,进行后端函数与数据库的交互
紧接着还得引入这个urlmanager,方便链接的统一管理,引入我们自定义的渲染函数增强通用性,引入分页函数,实现分页的逻辑
还有就是引入request,以便拿到前端的请求参数;引入redirect,完成重定向操作,引入blueprint,完成本页面的蓝图注册
默认页的路由函数
平平无奇,直接返回默认页面

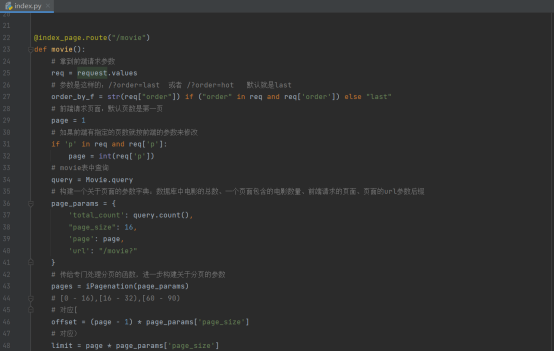
电影缩略图页面的路由函数
首先拿到前端页面传过来的request请求参数,判断是按热度排序还是按照日期排序,并且得知前端访问具体访问的是第几页(默认第一页)
之后用movie的数据表对象,通过sqlalchemy的函数对数据表中的信息进行查询(总电影数)。用总电影个数除以每个页面防止的电影缩略图个数就构造处理分页的相应参数,利用专门处理分页的函数进一步完善这些参数,而后就把这些参数传递给相应的前端页面,最后渲染返回。
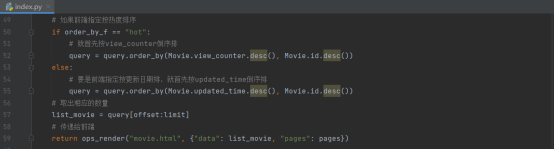
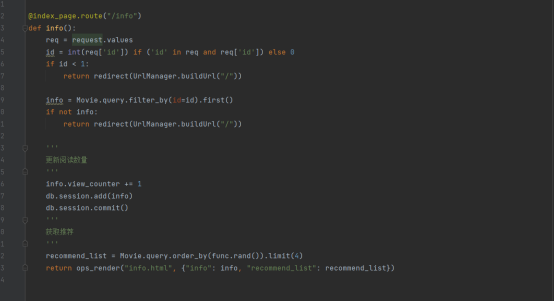
电影详情信息的路由函数
在这个模块中,依然是首先获取前端的参数(电影id),然后通过这个id号与数据库交互
在交互前,如果发现id号非法,例如小于1,就重定向到默认页中
用movie的数据表对象,通过sqlalchemy的函数对数据表中的movie表进行查询,查询到相应id的电影信息后,将该条信息返回到路由函数中,并且将点击量加1
此外还要获取推荐内容,随机从数据库中选取就可。
最后将要查询的电影和推荐列表一并返回给前端页面
成员信息相关后端
在介绍本模块前,也先对引入的包、变量等进行简单说明
引入app是为了加载配置文件的相关信息;引入db和数据表对象user,为了与数据库交互
引入make_response是为了返回自定义的信息;引入公共函数,方便使用
注册的路由函数
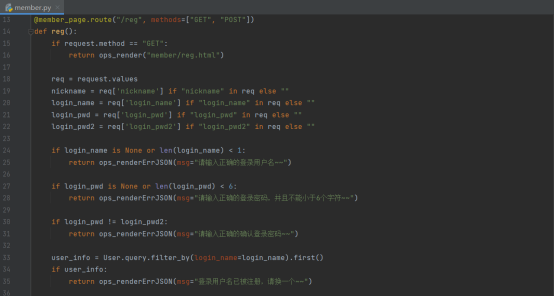
注册的前端页面会以post的方式提交注册数据,所以我们的路由函数不仅需要支持get的方式进行普通访问,还得需要支持post方式提交数据
首先判断访问方法,如果是get那直接返回渲染页面
如果是post,就用request取出相应的请求信息
而后对请求的信息进行一些非空的校验
通过后,对这些信息进行逻辑校验
通过后,对用户名进行数据库内的查询,判断是否已存在用户
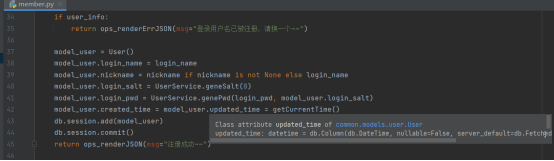
都没问题了,就新创建一个数据表对象,将相应的信息添加到数据库内
登录的路由函数
依然是首先判断访问方法,如果是get那直接返回渲染页面
如果是post,就用request取出相应的请求信息
之后对信息进行校验,如果不通过就返回相应的提示信息
如果成功了,就用make_response造一个返回的变量,这样才能用这个变量设置cookies,而后渲染返回并且在前端种下标志着已经登录的cookies
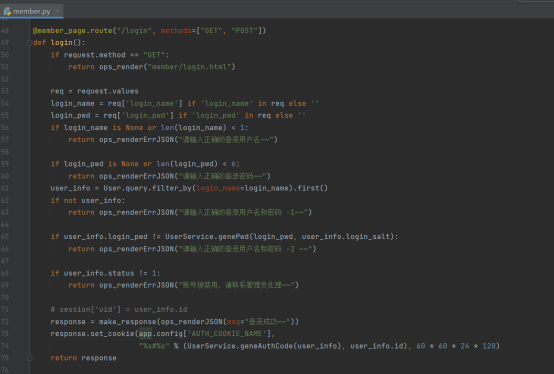
退出登录的路由函数
这个函数就简单了,如果在前端点了退出登录,那么首先重定向到首页,而后就把相应的cookies删除,这样登录态就消失啦

Linux环境用的是阿里云服务器的centos系统,使用uwsgi作为web服务器
在该系统内需要安装mysql和anaconda,最好就带上一些数据库的可视化管理工具
我推荐安装宝塔面板,可以一键安装mysql以及数据库可视化管理工具
Ps:千万别安装宝塔面板推荐的nginx,不然它到时候会拦截你的访问(这个原因我排查了一整天)
至于宝塔面板的安装操作,百度一下吧
第一步就是将我们的项目代码上传到我们的云服务器里,可以用ftp,也可以在宝塔面板中的图形化界面中直接上传
第二步就是给你的系统添加一个用户名
新增用户:
adduser xxxx
修改密码:
passwd xxxx
添加到sudo用户组:
gpasswd -a xxxx wheel
下载安装Anaconda:
sh Anaconda3-2021.02-Linux-x86_64.sh
路径选择的时候,不要改动,默认是:
/home/zengyue /anaconda3
激活anaconda:
source anaconda3/bin/activate
切换到xxxx用户:
sudo -iu xxxx
我建立的用户是zengyue
切换到用户后会有如下界面

第三步就是激活,并且创建一个虚拟环境
我直接用conda创建虚拟环境
conda create -n env_name python=x.x
我为这个项目所创建的虚拟环境叫mymovie,这是它的位置

紧接着我们进入虚拟环境
source activate env_name
就像这样

第四步就是安装需要的各种包
这些包推荐都统一用conda来安装,不要用pip,pip亲测安装uwsgi和flask-sqlalchemy失败,conda亲测成功,另外flask要安装1.x版本的,太高了好像不支持flask-script的命令
这些包的安装命令在百度搜“conda install 包名“就可以了
第五步修改代码
修改一下原来在window下的代码,把数据库配置文件的ip地址改为服务器上的公网ip就可以了。宝塔面板可以直接在线编辑,不用与讨厌的vim打交道!
第六步进入代码目录,用虚拟环境的解释器启动
我的代码文件就放在用户目录下

之后就是进入到相应的目录下

运行这行代码
uwsgi --http-socket :5000 --wsgi-file manager.py --callable app --processes 4 --threads 2
就可以利用uwsgi来启动web服务,它开启了4进程2线程

如果有类似的提示信息,就说明成功了
源码地址:
https://gitee.com/antpython/ant-python-fans-projects/tree/master/movie_webset
最后,推荐蚂蚁老师的Flask课程: