
PVT重磅升级:三点改进,性能大幅提升

极市导读
本文是南京大学&港大&南理工&商汤团队针对PVT的升级,针对PVT存在的不足提出了三点改进,所得PVTv2取得了显著优于PVTv1的性能,同时具有比Swin更佳的性能。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

本文是南京大学&港大&南理工&商汤团队针对PVT的升级,针对PVT存在的不足提出了三点改进(1)采用卷积提取局部连续特征;(2)带
zero-padding的重叠块嵌入提取位置信息编码;(3)带均值池化、线性复杂度的注意力层。受益于上述三点改进措施,所得PVTv2取得了显著优于PVTv1的性能,同时具有比Swin更佳的性能。
Abstract
Transformer在CV领域取得了喜人的进展。在本文工作中,我们在PVT(后称PVTv1)的基础上引入了如下三个改进得到了PVTv2:
采用卷积提取局部连续特征; 带 zero-padding的位置编码;带均值池化的线性复杂度的注意力层。
基于上述改进,所提PVTv2在分类、检测以及分割方面取得了显著优于PVTv1的性能,比如,PVTv2-B5在ImageNet上取得了83.8%的top1精度,优于Swin-B于Twins-SVT-L同时具有更少参数量与计算量;GFL+PVT-B2的组合在COCO-val2017数据集取得了50.2AP指标,显著优于Swin-T(高2.6AP)与ResNet50(高5.7AP)。更进一步,基于ImageNet-1K预训练,相比近期的工作(包含Swin Transformer)所提PVTv2取得了更佳的性能。
前情回顾
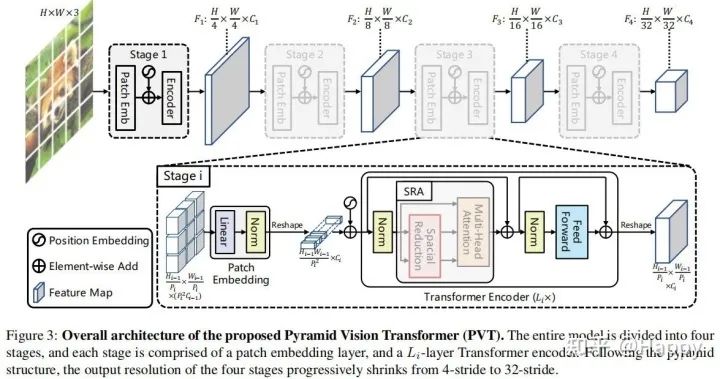
上图给出了PVT的架构示意图,PVT旨在将金字塔结构嵌入到Transformer结构用于生成多尺度特征,并最终用于稠密预测任务。类似与CNN骨干结构,PVT同样包含四个阶段用于生成不同尺度的特征,所有阶段具有相类似的结构:Patch Embedding+Transformer Encoder。
在第一个阶段,给定尺寸为的输入图像,我们按照如下流程进行处理:
首先,将其划分为的块(这里是为了与ResNet对标,最大输出特征的尺寸为原始分辨率的1/4),每个块的大小为; 然后,将展开后的块送入到线性投影曾得到尺寸为的嵌入块; 其次,将前述嵌入块与位置嵌入信息送入到Transformer的Encoder,其输出将为reshap为.
采用类似的方式,我们以前一阶段的输出作为输入即可得到特征。基于特征金字塔,所提方案可以轻易与大部分下游任务(如图像分类、目标检测、语义分割)进行集成。
对PVT一文感兴趣的朋友,可移步笔者之前的解读:
论文速递:金字塔Transformer,更适合稠密预测任务的Transformer骨干架构
Improved Pyramid Vision Transformer
类似ViT,PVTv1同样将图像视作非重叠块序列,而这种处理方式会在一定程度上破坏图像的局部连续性。此外,PVTv1中采用了定长位置编码,这对于任意尺度图像处理不够灵活。这些问题均限制了PVTv1在视觉任务方面的性能。
为解决上述问题,我们提出了PVTv2,它主要针对PVTv1进行了以下三个方面的改进。
Overlapping Patch Embedding
下图对比了PVTv1与PVTv2在块嵌入方面的差异示意图。也就是说,在PVTv2中,我们采用重叠块嵌入对图像进行序列化。下上图a为例,我们扩大了块窗口,使得近邻窗口重叠一半面积。在这里,我们采用带zero-padding的卷积实现重叠块嵌入。具体来说,给定尺寸为的输入,我们采用stride=S,核尺寸为,padding为S-1的卷积进行处理,输出尺寸为。
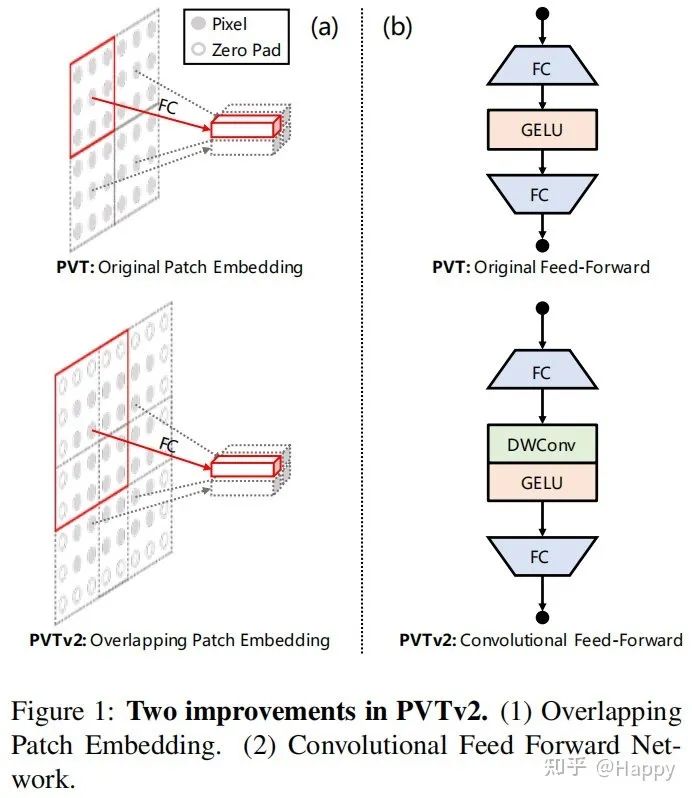
Convolutional Feed-Forward
受启发于LocalViT、CPVT,我们移除了定长位置编码,将zero-padding位置编码引入到PVT,见上图b。我们采用了深度卷积、全连接层以及GELU构建了前馈网络。
Linear Spatial Reduction Attention
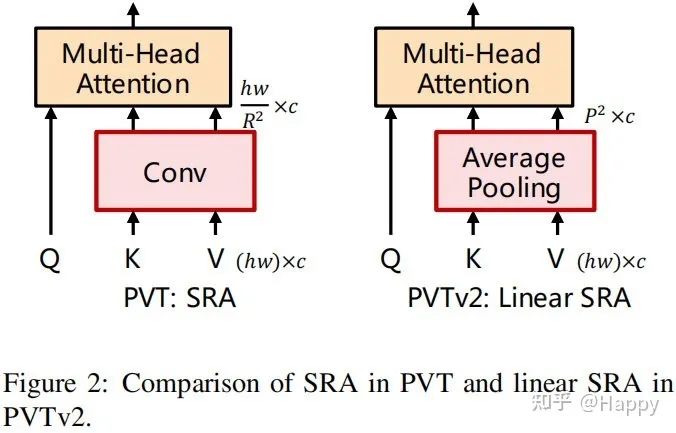
为进一步减少PVT的计算量,我们提出了LSRA(Linear Spatial Reduction Attention),见上图。与SRA不同之处,LSRA具有线性复杂度、内存占用与卷积类似。具体来说,给定的输如,SRA与LSRA的复杂度分别如下:
其中,R表示SRA的空间分辨率下降比例,P为LSRA的池化尺寸,默认为7。
Details of PVTv2 Seris
组合上述三点改进即得到了本文的PVTv2,它具有以下三个特性:
包含图像/特征更多的局部连续性; 更灵活的处理可变分辨率图像; 具有类似CNN的线性复杂度。
通过改变如下超参数,我们构建了不同版本的PVTv2(B0-B5)。
:表示阶段i的重叠块嵌入的stride; :表示阶段i的输出通道数; :表示阶段i的编码器层数; :表示阶段i的SRA的下降比例; :表示阶段i的LSRA的自适应均值池化尺寸; :表示阶段i的Efficient Self-Attention的头数; :表示阶段i的前馈层的扩张比例。
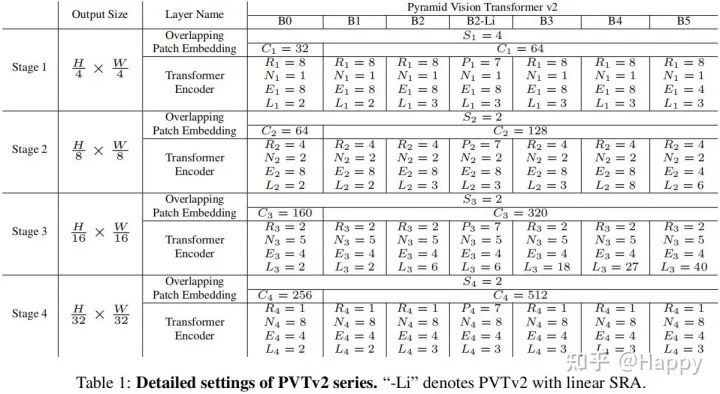
上表给出了PVTv2的结构信息,该设计参考ResNet的设计原则:
通道维度随空间分辨率收缩而提升; Stage-3被赋予更多的计算量。
Experiments
在实验方面,我们主要在ImageNet分类、COCO检测与实例分割方面进行了对比。
ImageNet

上表给出了ImageNet上的性能对比,从中可以看到:
相比PVT,PVTv2具有相似的FLOPs与参数量,但性能取得了显著提升。比如,相比PVTv1-tiny,PVTv2-B1指标高3.6%;相比PVT-large,PVTv2-B4指标高1.9%; 性比其他方案,PVTv2同样具有显著优势(精度、模型大小)。比如,相比Swin与Twins,所提PVTv2-B5取得了83.8%top1精度,指标更高、参数量与FLOPs更低。
COCO
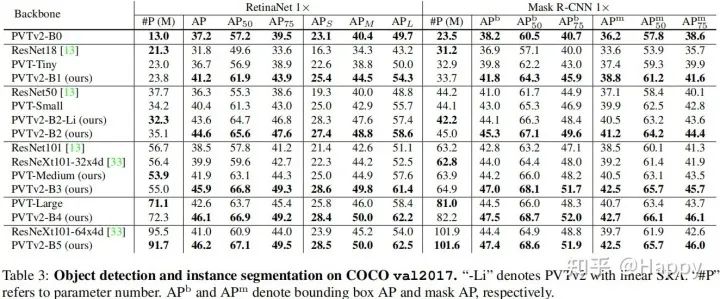
上表给出了COCO目标检测与实例分割方面的性能对比,从中可以看到:在单阶段与双阶段目标检测方面,PVTv2均比PVTv1具有更好的性能:相同模型大小,更高的指标。比如,基于RetinaNet,PVTv2-B4取得了46.4AP指标,以3.5AP超过了PVTv1;基于Mask R-CNN,PVTv2-B4取得了47.5AP指标,以3AP优于PVTv1。
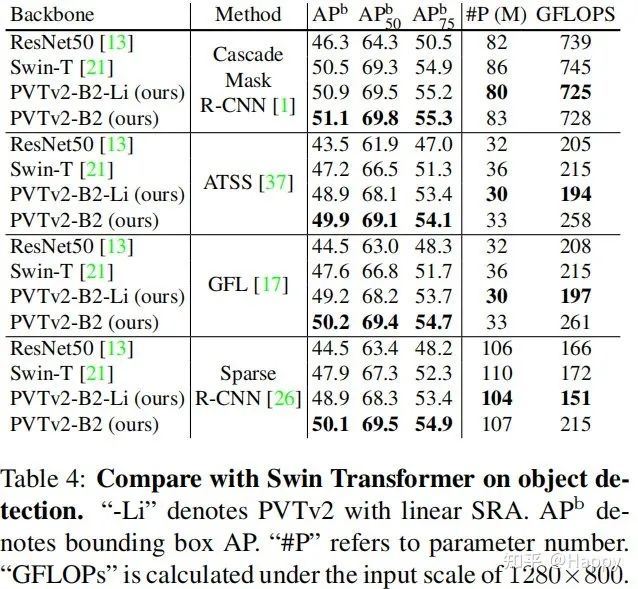
为了与Swin更公平的对比,我们确保所有配置相同(包含预训练与微调)并在四种不同的检测器框架下进行了对比,结果见上表。从中可以看到:PVTv2在四种检测器框架下均取得了比Swin更佳的 AP指标,证实了其优异的特征表达能力。比如,基于ATSS框架,相比Swin-T,所提PVTv2取得了2.7指标提升且具有相似参数量与计算量;所提PVTv2-Li可以将计算量从258G减少到194G,而精度仅轻微下降(约1AP)。
本文亮点总结
采用卷积提取局部连续特征; 带 zero-padding的位置编码;带均值池化的线性复杂度的注意力层。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“目标检测综述”获取综述:目标检测二十年(2001-2021)~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
