
Dubbo 3.0.0正式发布:应用级服务注册,跨语言的RPC协议、更好支持Kubernetes!

背景
ALIWARE
自从 Apache Dubbo 在 2011 年开源以来,在一众大规模互联网、IT公司的实践中积累了大量经验后,Dubbo 凭借对 Java 用户友好、功能丰富、治理能力强等优点在过去取得了很大的成功,成为国内外热门主流的 RPC 框架之一。
但随着云原生时代的到来,以 Apache Dubbo、Spring Cloud 等为代表的 Java 微服务治理体系面临了许多新的需求,包括期望应用可以更快的启动、应用通信的协议穿透性可以更高、能够对多语言的支持更加友好等。例如Spring 也在今年推出了其基于 GraalVM 的 Spring Native Beta 解决方案,拥有毫秒级启动的能力、更高的处理性能等优化提升。
这样的背景对下一代 Apache Dubbo 提出了两大要求:一是要保留已有的开箱即用和落地实践背景下积累的优点,这也是众多开发者所期望的;二是尽可能地遵循云原生思想,能更好的复用底层云原生基础设施并且更贴合云原生的微服务架构。
拥抱云原生
ALIWARE
在如今的大背景下,Apache Dubbo 3 选择全面拥抱云原生,将 Dubbo 的架构升级,提出了全新的服务发现模型、下一代 RPC 协议和云原生基础设施适配等优化方案。
1、全新服务发现模型(应用级服务发现)
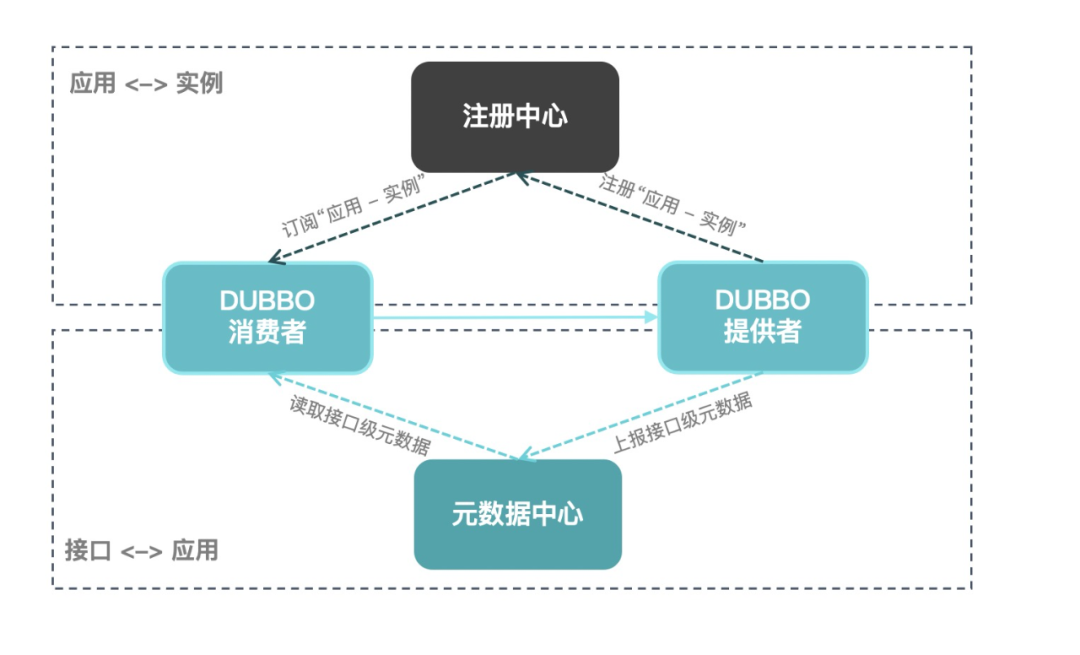
以 Dubbo 原有的设计,存储在注册中心中的数据会在很大程度上存在重复的内容,这其实浪费了一部分的存储。而当整个集群的规模足够大的时候,由于服务注册发现是服务维度的,注册中心的数据量就会爆发式地增长。
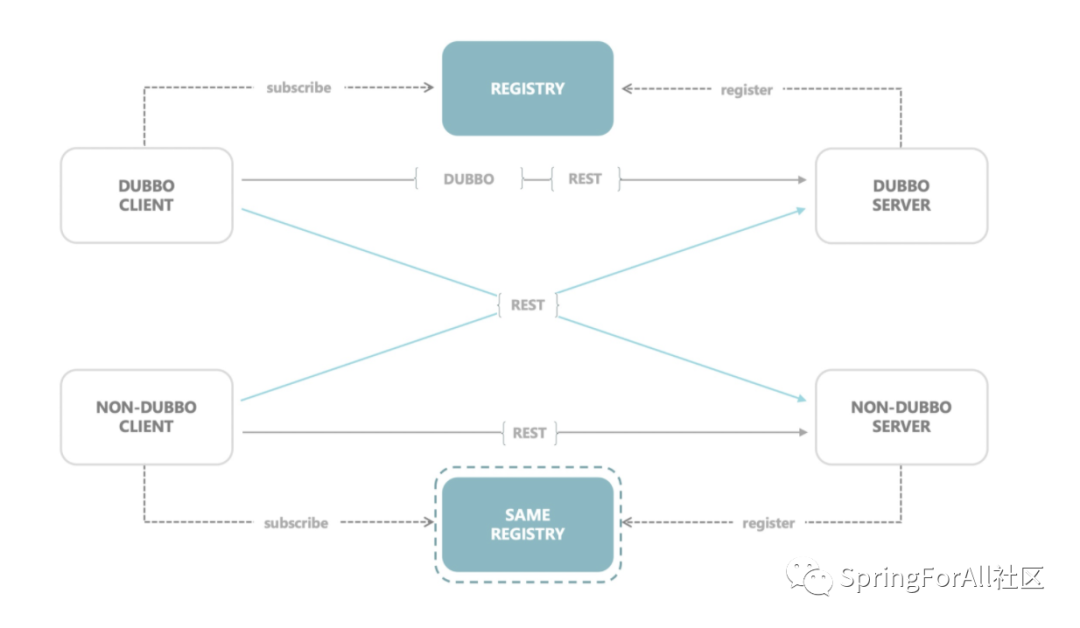
当前同样是微服务治理工具的 Spring Cloud 和 gRPC 都是基于应用级的服务发现,如果仍使用接口级别的注册方式,Dubbo 就很难和他们进行互通。但假如 Dubbo 也可以像 Spring Cloud 一样以服务级注册,那么在异构体系下将可以很轻松地工作起来。
应用级服务发现机制是 Apache Dubbo 面向云原生走出的重要一步,它帮 Apache Dubbo 打通了与其他微服务体系之间在地址发现层面的鸿沟,也成为 Apache Dubbo 适配 Kubernetes Native Service 等基础设施的基础。
基于应用级服务发现,注册中心的数据将被重新组织,注册中心的压力大大减轻。同时,由于地址量减少了,应用自身的内存消耗也可以大幅降低。

在一般情况下,应用中存储的地址量可以降低约一半,针对上游应用大规模部署的场景(比如部署了 1000 个节点、提供了 50 个服务)甚至可以达到 95% 以上,这对于核心应用的内存压力环境带来的优化是巨大的。
2、下一代 RPC 协议 —— Triple
在云原生时代,Dubbo RPC 协议主要面临两个挑战:
1、生态不互通,Dubbo 协议基于二进制流定制了与 RPC 强绑定的核心语义,包括协议头、标志位、请求 ID 以及请求/响应数据等。而对于越来越多的云原生治理设施,要让他们都 “读” 懂 Dubbo 的二进制 “语义” 并不容易。
2、由于协议设计的问题,Dubbo 协议的协议头已无法再承载更多的元数据信息。而对于 Mesh 等网关型组件,如果想要对数据进行治理就需要对完整的数据包进行解析才能获取到必要的元数据信息(如 RPC 上下文),从性能到易用性方面都会面临挑战。
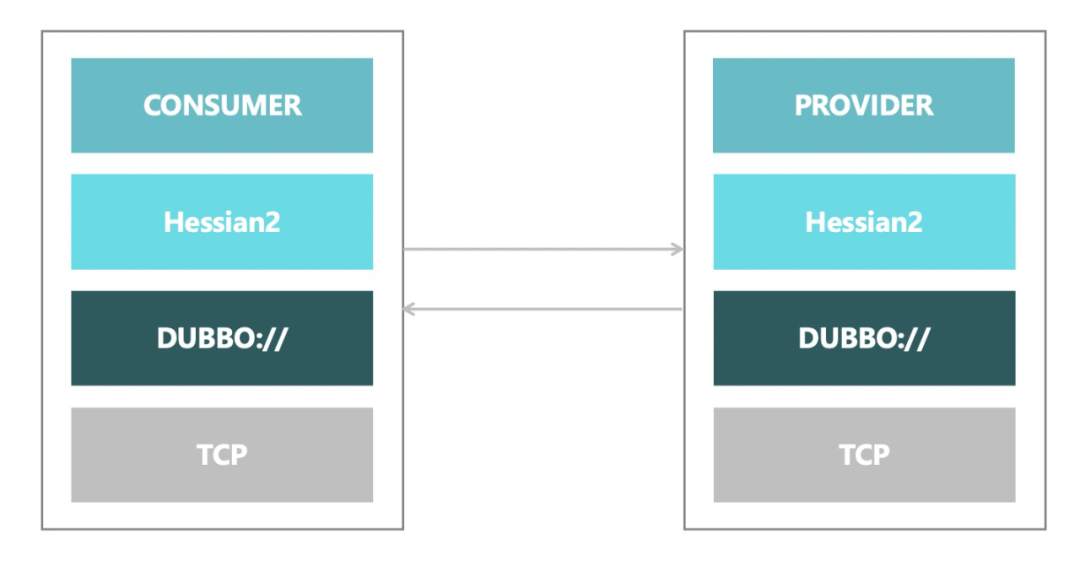
在支持已有的功能和解决存在的问题的前提下,Apache Dubbo 3 提出了下一代 RPC 协议——Triple。
基于 Tripe 协议,我们期望可以解决这些问题:
1、跨语言互通的问题。传统的多语言多 SDK 模式和 Mesh 化跨语言模式都需要一种更通用易扩展的数据传输格式;
2、提供更完善的请求模型。除了 Request/Response 模型,还应该支持 Streaming 和 Bidirectional;
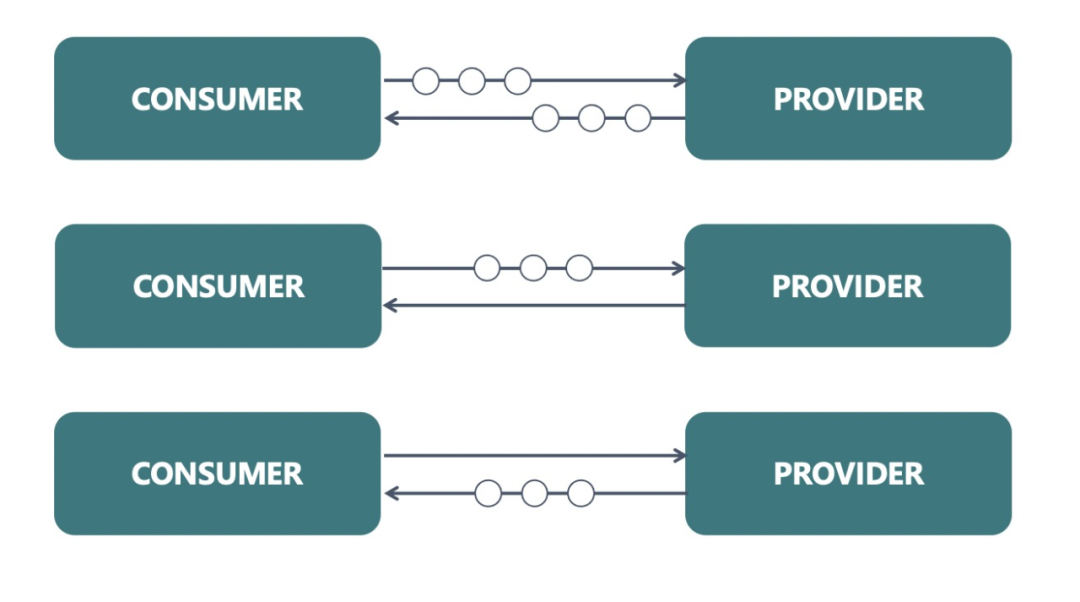
3、易扩展、穿透性高。包括但不限于 Tracing / Monitoring 等支持,也应该能被各层设备识别,网关设施等可以识别数据报文,对 Service Mesh 部署友好,降低用户理解难度;
4、支持 Java 用户无感知升级。不需要定义繁琐的 IDL 文件,仅需要简单的修改协议名便可以轻松升级到 Triple 协议。
基于这些期望,我们觉得 HTTP/2 作为底层通信协议,使用 protobuf 作为序列化协议的组合是最合理的,这套组合方案也是 gRPC 协议使用的方案。所以对于 Triple 协议来说,我们可以基于 gRPC 协议进行演变,以满足 Apache Dubbo 已有的优秀特性,这同时也保证了在生态系统上新协议和 gRPC 是能够互通和共享的。
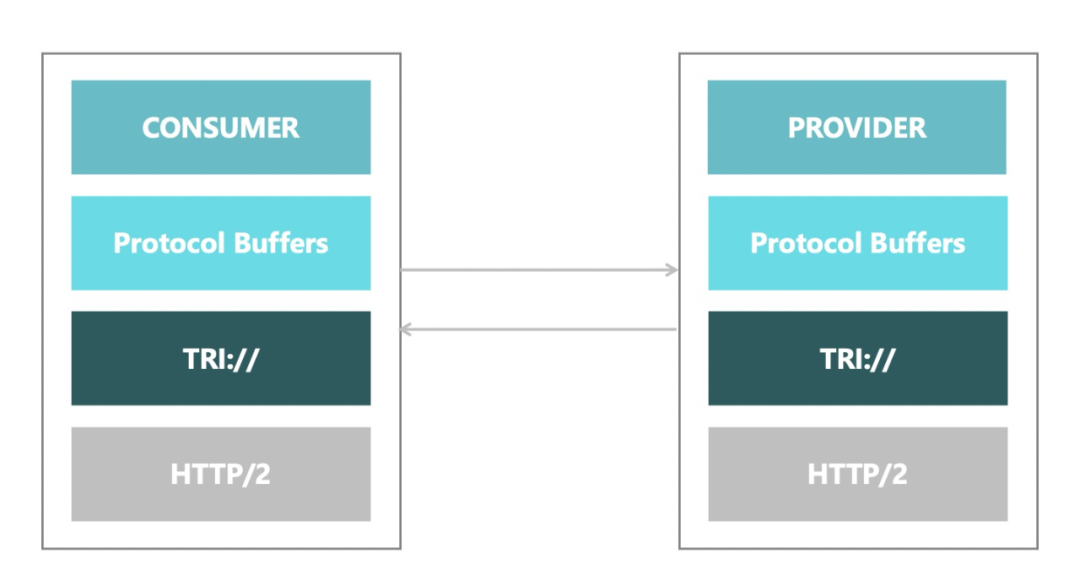
3、云原生设施接入
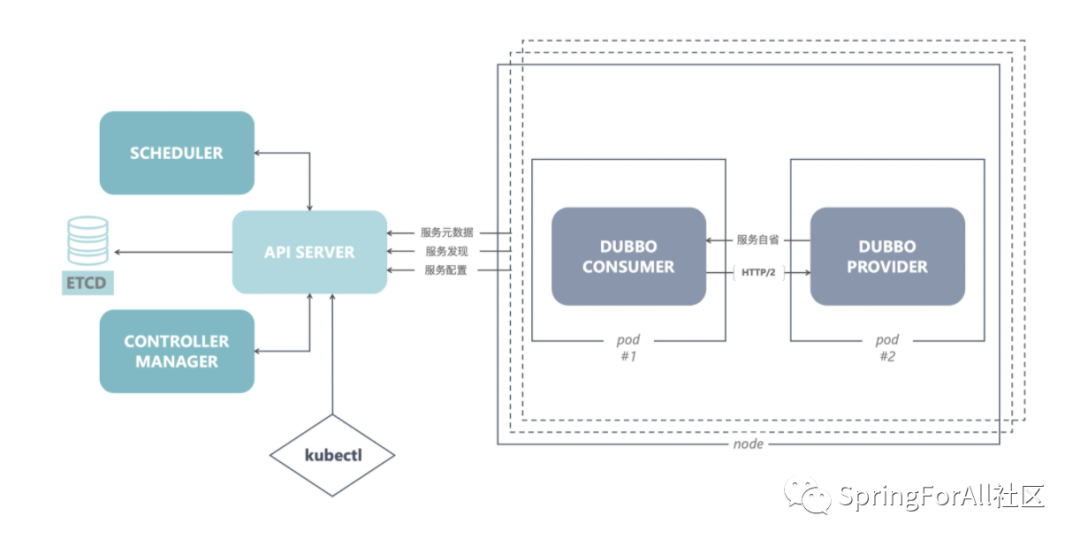
针对于 Kubernetes 的场景, Apache Dubbo 3 为此做了两方面的接入:
一是原生支持与 Kubernetes Pod 生命周期对齐,基于 Dubbo QoS 机制,Kubernetes 能够感知到运行在 Pod 容器中的 Dubbo 应用当前是什么状态,而且得益于 Dubbo SPI 机制用户可以自定义探针检测的维度,实现框架和业务的生命周期都达到统一。
第二是 Dubbo 也将支持接入 Kubernetes Native Service 体系,原生支持基于 Kubernetes API Server 和 DNS 的服务发现体系,实现部署架构下的服务概念与 Dubbo 中的服务概念进行对齐。
而对于 Service Mesh 体系,如果应用使用 Apache Dubbo 2 想要部署以 Mesh 方式部署,需要使用 Sidecar 对 Dubbo 流量进行拦截,而同时由于 Dubbo 本身是具有一定的治理能力的,从应用来说会多做了很多无用的事情,从集群的角度来说会造成调用的紊乱。
基于此,Apache Dubbo 3 提出了两种部署模式,一种是配合 Sidecar 部署的 Thin SDK 模式、另一种是直接接入控制面的 Proxyless Mesh 模式。
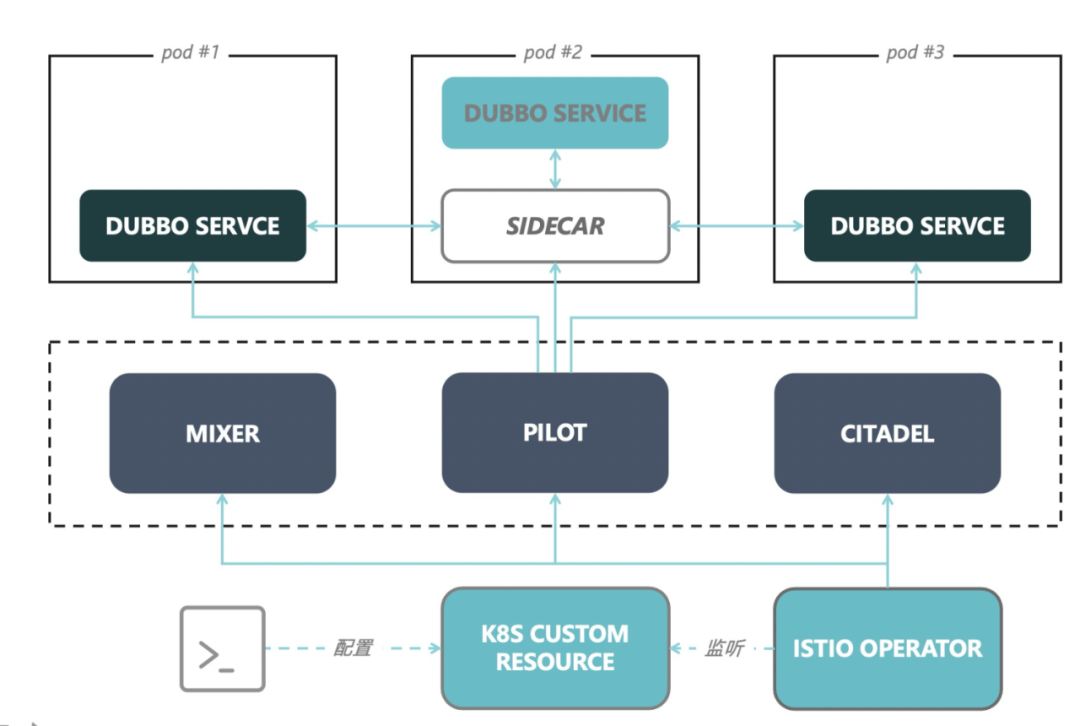
除了部署架构的接入,在 Apache Dubbo 3 中还定义了一套面向云原生流量治理,支持传统 SDK、Mesh 场景的统一治理规则。
Apache Dubbo 3 期望使用这一套规则,便可以实现如金丝雀发布、A/B测试等丰富的路由语义,只需要配置一套规则,写入统一的控制面,就可以统一地控制所有集群。这样无论使用 Kubernetes 直接部署、亦或者是 Mesh 场景下使用 Thin SDK 或 Proxyless 混合部署甚至是用户直接手动部署集群均可以被同一套规则所控制,实现定义一次,到处使用的目标。
未来展望
ALIWARE
Apache Dubbo 3.0.0 是捐给 Apache 后的一个里程碑版本,代表着 Apache Dubbo 全面拥抱云原生的一个重要节点。
在 2021 年 11 月我们会发布 Apache Dubbo 3.1 版本,届时我们会带来 Apache Dubbo 在 Mesh 场景下部署的实现与实践。
在 2022 年 3 月我们会发布 Apache Dubbo 3.2 版本,在这个版本中我们将带来全新的大规模应用部署下智能流量调度机制,提高系统稳定性与资源利用率。
Apache Dubbo 3 目前已经和阿里巴巴集团内部的 RPC 框架实现了融合,期望用它来解决内部落地问题,做到技术栈统一。未来,Apache Dubbo 3 将大规模落地阿里集团,承载 618、双十一等复杂业务场景。
社区衷心地希望欢迎大家向社区提交 issue 和 PR,社区的同学会尽快进行 review 和回复。另外,社区会尽可能保证一个较短的发版周期,及时对已有的问题进行修复。
同时在 Apache Dubbo 3 开始,社区也会采用更开放的态度对待生产环境下的定制需求,我们欢迎大家将自己的定制化实现贡献给开源社区,dubbo-spi-extensions 仓库未来会对这些定制化进行支持。


往期推荐
关注我回复「加群」,加入Spring技术交流群