手写解析微信Matrix性能监控日志的工具
1. 前言
2018年12月25日,微信团队自研的APM利器,Matrix正式开源了。
❝Matrix 是一款微信研发并日常使用的 APM (Application Performance Manage) ,当前主要运行在 Android 平台上。Matrix 的目标是建立统一的应用性能接入框架,通过对各种性能监控方案快速集成,对性能监控项的异常数据进行采集和分析,输出相应问题的分析、定位与优化建议,从而帮助开发者开发出更高质量的应用。
❞
在精读了Matrix的源码之后,我发出了赞叹和吐槽两种声音。值得赞扬的是,「这个APM框架的设计思路确实鬼斧神工,有很多值得Android开发者学习的地方,深入了解它,能够扩宽我们的编程视野。」 令人吐槽的就是,「从文档的丰富性,代码的可读性,代码的注释量,开源的一条龙服务等方面讲,他们做的还不太好。」 作为国内的顶尖开发团队,这些方面与国外的顶尖开源开发团队还是有不小的差距。
目前Matrix的集成确实很方便,参考官方文档,大概10分钟左右就能集成到项目中。「但是它有一个硬伤,对开发者很不友好,它集成很方便,但是分析和定位问题比较困难,开发者需要搭建一套数据采集和分析系统,大大地增加了开发者的使用门槛。」 目前它在github上的star量是8.5k。如果微信团队能把采集系统和数据分析系统也开源出来,用户的使用门槛将会大大降低,相信star量也能更上一个台阶。
吐槽归吐槽。吐槽不是目的。希望国内的开发者可以更真心实意地做出更好用的开源产品。「吐槽完毕,接下来我将聊聊Matrix官方文档中没有讲到的一些设计细节。真的很惊艳。如果你对Matrix曾经有任何偏见,不妨跟随我打破偏见,突破微信团队给我们设置的使用门槛。」
2. Matrix功能简介
Matrix 当前监控范围包括:「应用安装包大小,SQLite 操作优化,帧率变化,卡顿,启动耗时,页面切换耗时,慢方法,文件读写性能,I/O 句柄泄漏, 内存泄漏等。」
更多详细介绍请移步Matrix简介
「本文将着重讲解检测慢方法的实现原理,以及数据格式分析,数据格式是Matrix的重中之重,无论是采集过程生成数据,还是分析过程解析数据,都需要熟练理解数据格式。其它系列的文章随着我对Matrix的理解程度加深,也会陆续在公众号发布,敬请关注。」
3. 慢方法演示
官方Demo,TestTraceMainActivity#testJankiess(View view)模拟在主线程调用方法超过700ms的场景。Matrix中慢方法的默认阈值是700ms。用户可配置。对应的字段是
❝//Constants.java
public static final int DEFAULT_EVIL_METHOD_THRESHOLD_MS = 700;
❞

点击EVIL_METHOD按钮,会调用testJankiess方法。打印Log如下
乍一看,有点丈二的和尚摸不着头脑。出现这样的日志,说明主线程调用时长超过了700ms。把日志中content对应的json格式化,得到如下结果:
{
"machine":"UN_KNOW",
"cpu_app":0,
"mem":1567367168,
"mem_free":851992,
"detail":"NORMAL",
"cost":2262,
"usage":"0.35%",
"scene":"sample.tencent.matrix.trace.TestTraceMainActivity",
"stack":"0,1048574,1,2262\n
1,117,1,2254\n
2,121,1,2254\n
3,124,1,384\n
4,125,1,165\n
5,126,1,21\n
5,127,1,21\n
5,128,1,19\n
4,129,1,24\n
3,130,1,65\n
4,131,1,21\n
4,132,1,6\n
4,133,1,8\n
3,134,1,1004\n",
"stackKey":"121|",
"tag":"Trace_EvilMethod",
"process":"sample.tencent.matrix",
"time":1620523013050
}
关于数据格式,官方也有一篇文章介绍,https://github.com/Tencent/matrix/wiki/Matrix-Android--data-format,感兴趣的同学可以去看看。
本文重点关注stack字段。它的功能是上报对应的堆栈。但是堆栈中为啥是一堆阿拉伯数字呢?先让我们从头说起了。
4.计算方法调用的时间花费
4.1 计算一个方法调用花费的时间
假设有方法A。我想计算它花费的时间。我们一般会这样做
public void A() {
long startTime = SystemClock.uptimeMillis()
SystemClock.sleep(1000);
long endTime = SystemClock.uptimeMillis()
System.out.println("cost time " + (endTime-startTime));
}
对于单个方法我们可以这样做。「但是如果我想给Android项目中所有的方法都计算调用花费时,我们需要用到字节码插桩技术。在所有的方法开始处和结束处,添加记录时间的代码。而Matrix也正是使用插桩技术来计算方法的时间调用的。」
项目工程中TestTraceMainActivity的A方法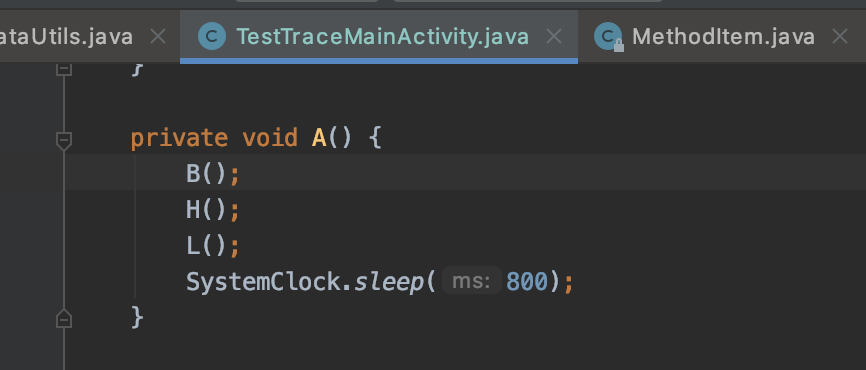
使用Jadx工具反编译apk中的TestTraceMainActivity。发现A方法前后增加了「AppMethoBeat.i(121)和AppMethoBeat.o(121)」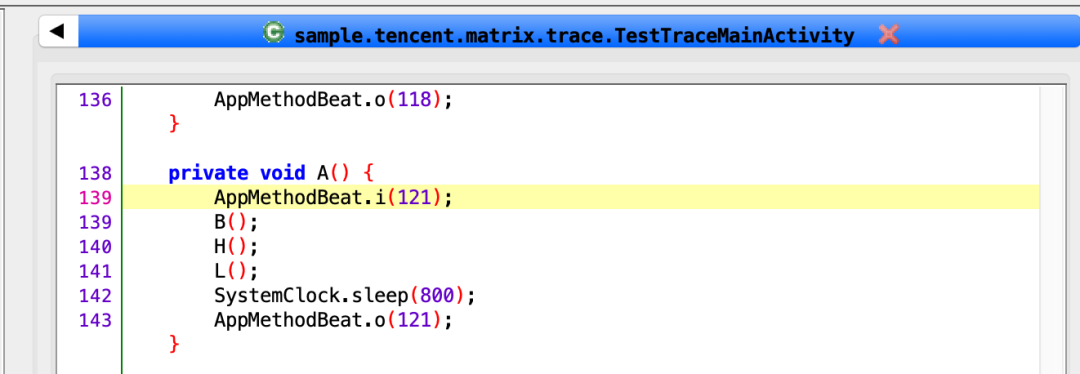
「i/o 方法参数121是什么意思呢?」
4.2 121含义讲解
gradle插件,在处理方法时,会将方法名与从1开始递增的数字对应起来。「我们打开app/build/outputs/mapping/debug/methodMapping.txt文件。从图片我们可以看到121对应的方法名是sample.tencent.matrix.trace.TestTraceMainActivity A ()V」
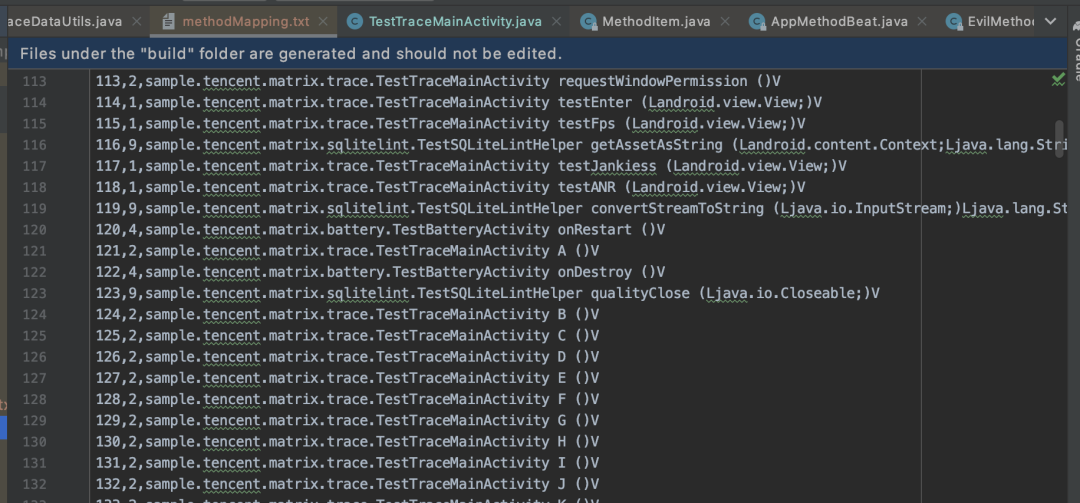
❝前文堆栈中的数字0,1048574,1,2262\n 第二列1048574对应的就是方法名对应的数字。「这么做的好处是,数据采集节省流量。」
❞
4.3 获取调用栈的耗时
有方法调用如下,假设A方法调用耗时1000ms。如何能够确定调用栈中哪个子方法的调用最耗时?
public void A() {
B();
C();
D();
}
❝Matrix框架已经实现了调用栈耗时监测,具体分析我放到后面讲解。「重点就是后文6.2章节」
❞
4.4 获取主线程耗时
依赖主线程Looper,监控每次dispatchMessage的执行耗时
public static void loop() {
...
for (;;) {
...
// This must be in a local variable, in case a UI event sets the logger
Printer logging = me.mLogging;
if (logging != null) {
logging.println(">>>>> Dispatching to " + msg.target + " " +
msg.callback + ": " + msg.what);
}
msg.target.dispatchMessage(msg);
if (logging != null) {
logging.println("<<<<< Finished to " + msg.target + " " + msg.callback);
}
...
}
}
主线程所有执行的任务都在 dispatchMessage 方法中派发执行完成,「我们通过 setMessageLogging 的方式给主线程的 Looper 设置一个 Printer ,因为 dispatchMessage 执行前后都会打印对应信息。我们可以计算出执行前后的时间花费。」
5. Matrix如何实现插桩
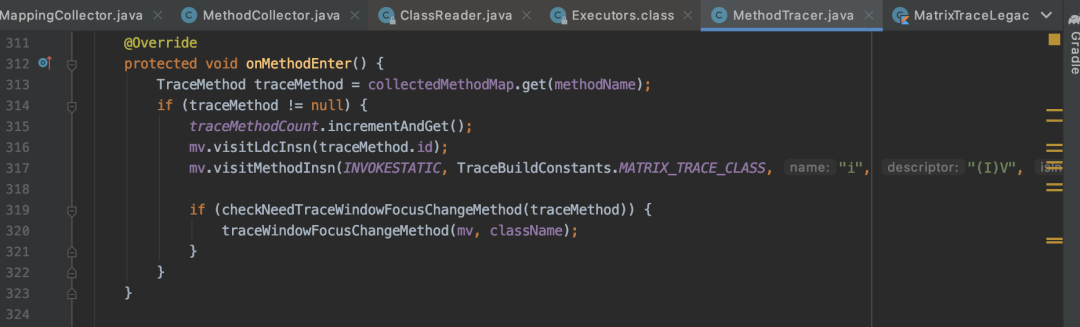
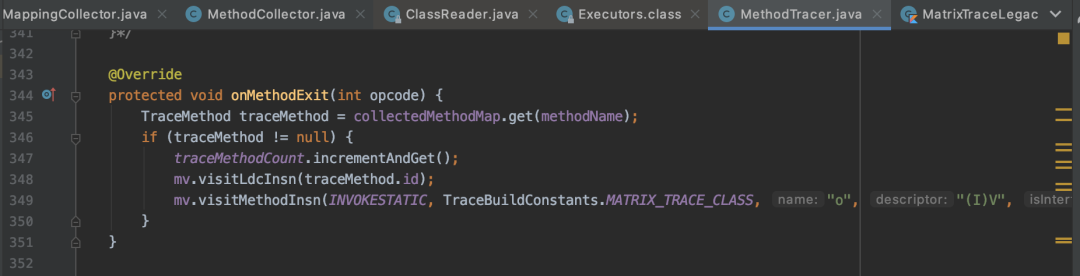
本文只是简单介绍Matrix的插桩技术。浅尝辄止。实现插桩的代码是com/tencent/matrix/trace/MethodTracer.java,「它的内部类TraceMethodAdapter实现了AppMethoBeat.i()和AppMethoBeat.o()的插入功能。」
6. 慢方法监测的原理
6.1 手画调用栈树
第三节提到的慢方法演示,它的代码调用如下。
public void testJankiess(View view) {
A();
}
private void A() {
B();
H();
L();
SystemClock.sleep(800);
}
private void B() {
C();
G();
SystemClock.sleep(200);
}
private void C() {
D();
E();
F();
SystemClock.sleep(100);
}
private void D() {
SystemClock.sleep(20);
}
private void E() {
SystemClock.sleep(20);
}
private void F() {
SystemClock.sleep(20);
}
private void G() {
SystemClock.sleep(20);
}
private void H() {
SystemClock.sleep(20);
I();
J();
K();
}
private void I() {
SystemClock.sleep(20);
}
private void J() {
SystemClock.sleep(6);
}
private void K() {
SystemClock.sleep(10);
}
private void L() {
SystemClock.sleep(1000);
}
「它对应的methodMapping文件如下:」
117,1,sample.tencent.matrix.trace.TestTraceMainActivity testJankiess (Landroid.view.View;)V
121,2,sample.tencent.matrix.trace.TestTraceMainActivity A ()V
122,4,sample.tencent.matrix.battery.TestBatteryActivity onDestroy ()V
123,9,sample.tencent.matrix.sqlitelint.TestSQLiteLintHelper qualityClose (Ljava.io.Closeable;)V
124,2,sample.tencent.matrix.trace.TestTraceMainActivity B ()V
125,2,sample.tencent.matrix.trace.TestTraceMainActivity C ()V
126,2,sample.tencent.matrix.trace.TestTraceMainActivity D ()V
127,2,sample.tencent.matrix.trace.TestTraceMainActivity E ()V
128,2,sample.tencent.matrix.trace.TestTraceMainActivity F ()V
129,2,sample.tencent.matrix.trace.TestTraceMainActivity G ()V
130,2,sample.tencent.matrix.trace.TestTraceMainActivity H ()V
131,2,sample.tencent.matrix.trace.TestTraceMainActivity I ()V
132,2,sample.tencent.matrix.trace.TestTraceMainActivity J ()V
133,2,sample.tencent.matrix.trace.TestTraceMainActivity K ()V
134,2,sample.tencent.matrix.trace.TestTraceMainActivity L ()V
1048574,1,android.os.Handler dispatchMessage (Landroid.os.Message;)V
「以上方法调用可以归纳成以下树形结构:」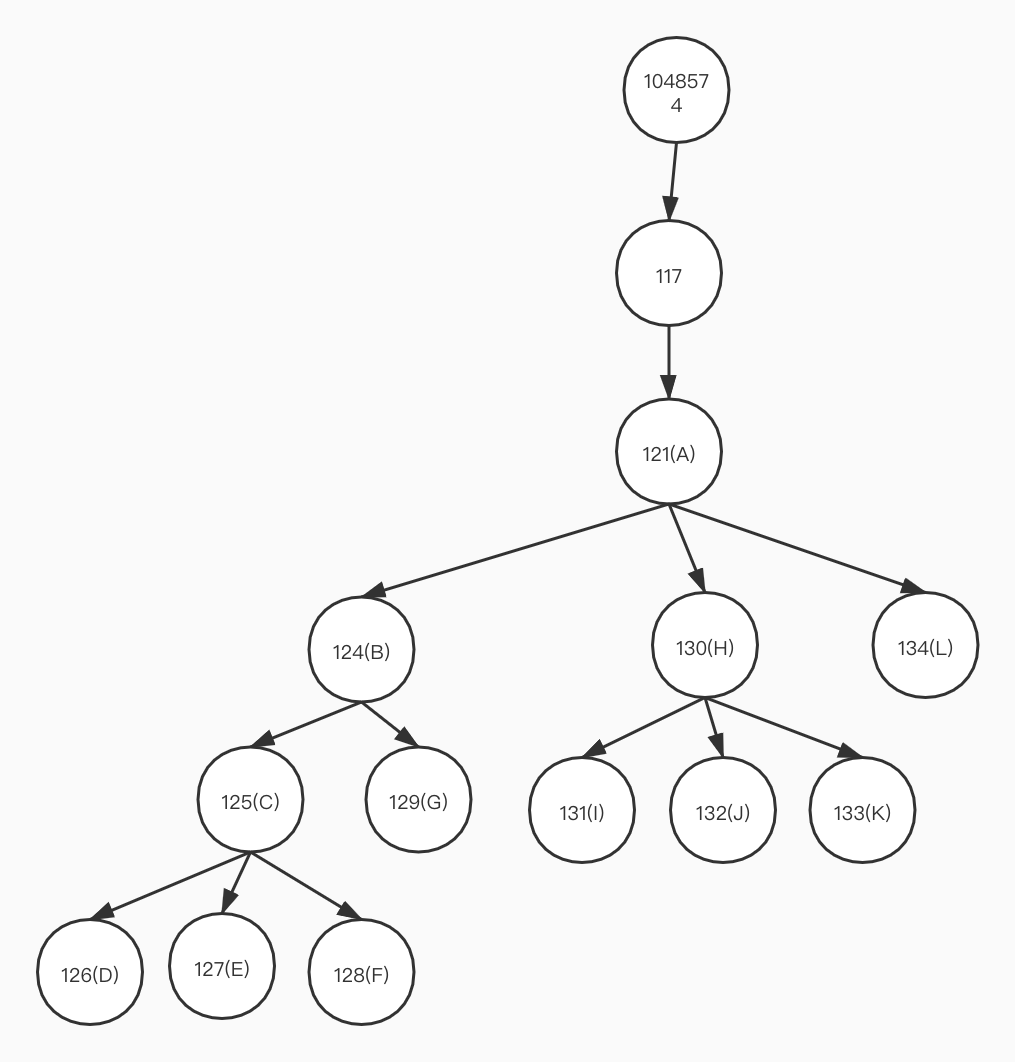
❝「请注意,该树形图,是我直接根据调用次序画出来的,程序是如何根据调用次序生成调用栈树呢?」
❞
6.2 生成调用栈树
6.2.1 函数调用记录在队列中
编译期已经对全局的函数进行插桩,在运行期间每个函数的执行前后都会调用 MethodBeat.i/o 的方法,如果是在主线程中执行,则在函数的执行前后获取当前距离 MethodBeat 模块初始化的时间 offset 「(为了压缩数据,存进一个long类型变量中),」 并将当前执行的是 MethodBeat i或者o、mehtod id 及时间 offset,存放到一个 long 类型变量中,记录到一个预先初始化好的数组 long[] 中 index 的位置(预先分配记录数据的 buffer 长度为 100w,内存占用约 7.6M)。数据存储如下图: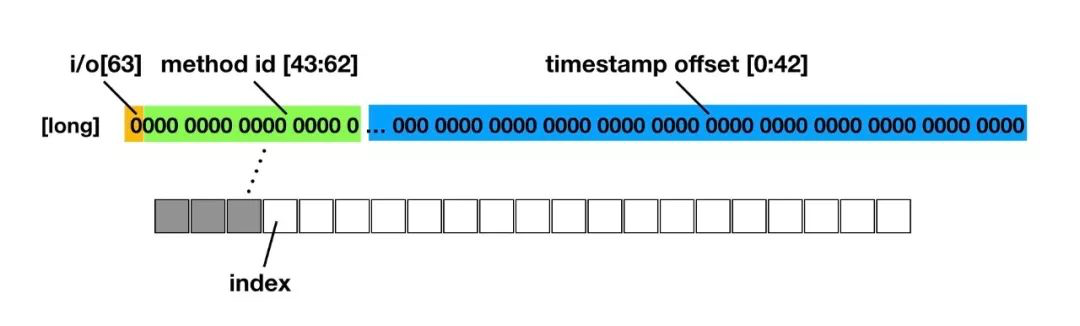
//AppMethodBeat.java
private static long[] sBuffer = new long[Constants.BUFFER_SIZE];
//Constants.java
public static final int BUFFER_SIZE = 100 * 10000; // 7.6M
「AppMethodBeat.i/o方法最终会调用到」
//AppMethodBeat.java
private static void mergeData(int methodId, int index, boolean isIn) {
if (methodId == AppMethodBeat.METHOD_ID_DISPATCH) {
sCurrentDiffTime = SystemClock.uptimeMillis() - sDiffTime;
}
long trueId = 0L;
if (isIn) {
trueId |= 1L << 63;
}
trueId |= (long) methodId << 43;
trueId |= sCurrentDiffTime & 0x7FFFFFFFFFFL;
sBuffer[index] = trueId;
checkPileup(index);
sLastIndex = index;
}
「testJankiess方法调用,通过mergeData方法,最终填充sBuffer如下图:」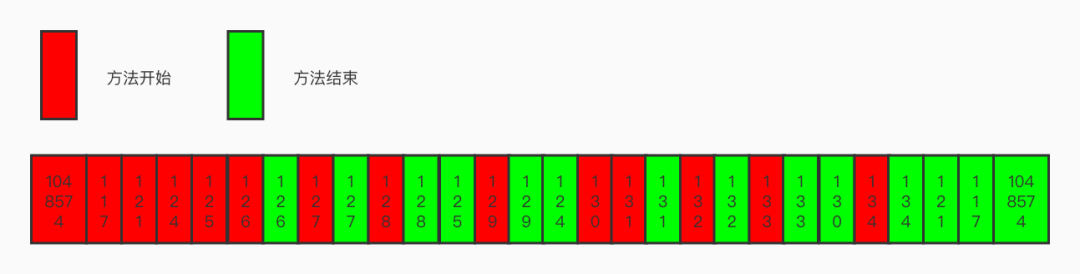
6.2.2 主线程调用结束后判断是否超过阈值
EvilMethodTracer.java dispatchEnd表示主线程执行结束,如果耗时超过阈值,会在MatrixHandlerThread中执行AnalyseTask,分析调用栈的耗时情况。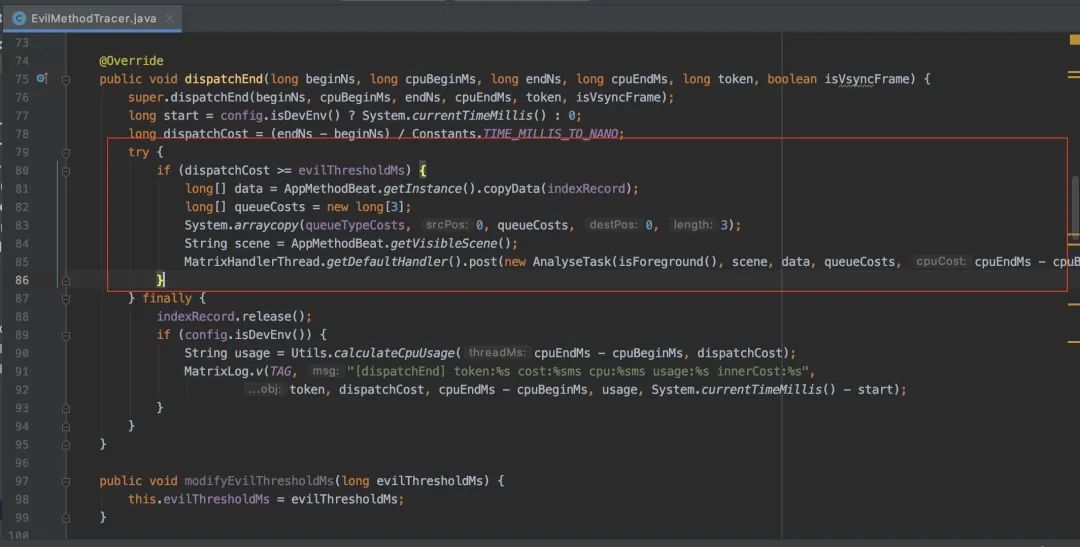
6.2.3 分析堆栈
调用TraceDataUtils.structuredDataToStack()方法 调用TraceDataUtils.trimStack()方法 调用TraceDataUtils.getTreeKey()方法 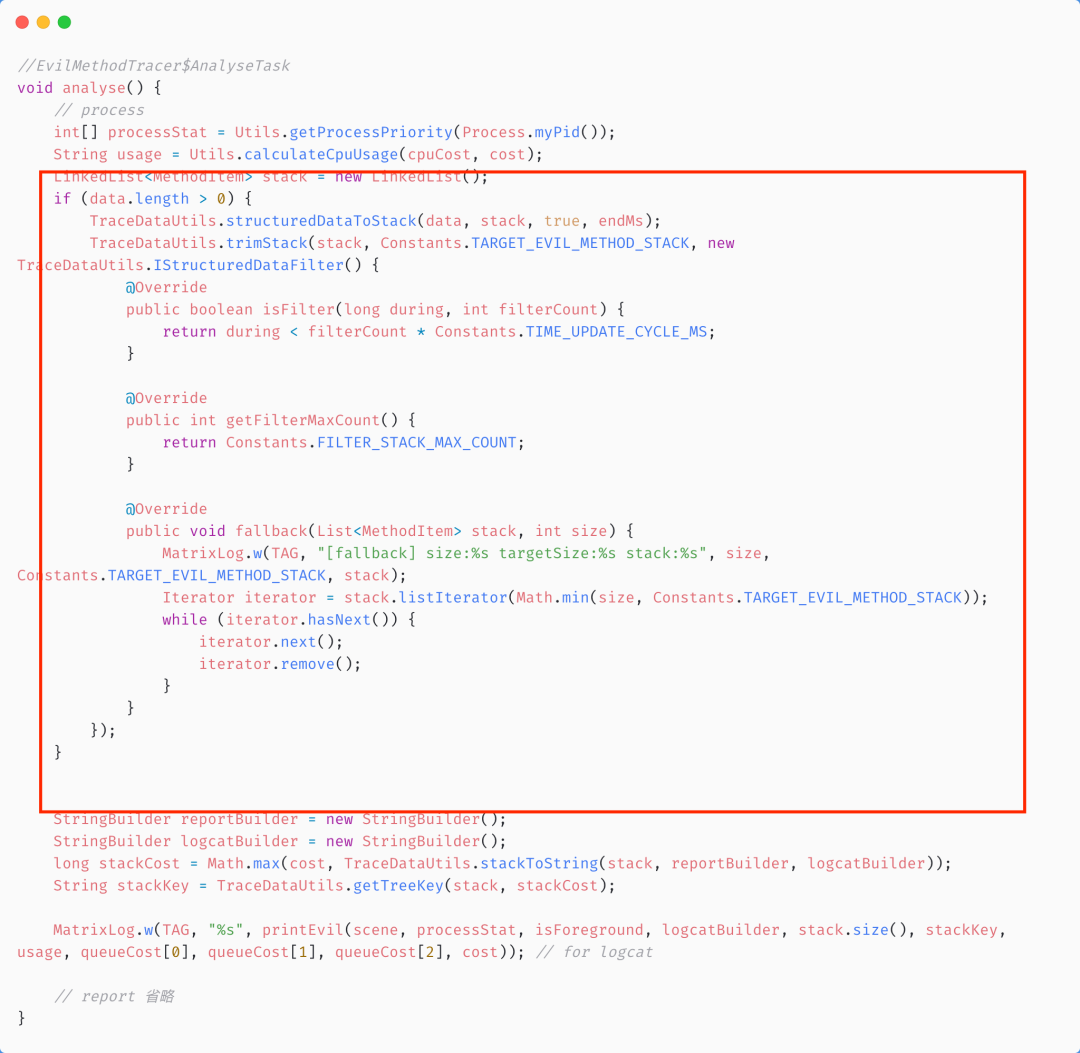
6.2.4 将调用队列转换成树的先序遍历结果
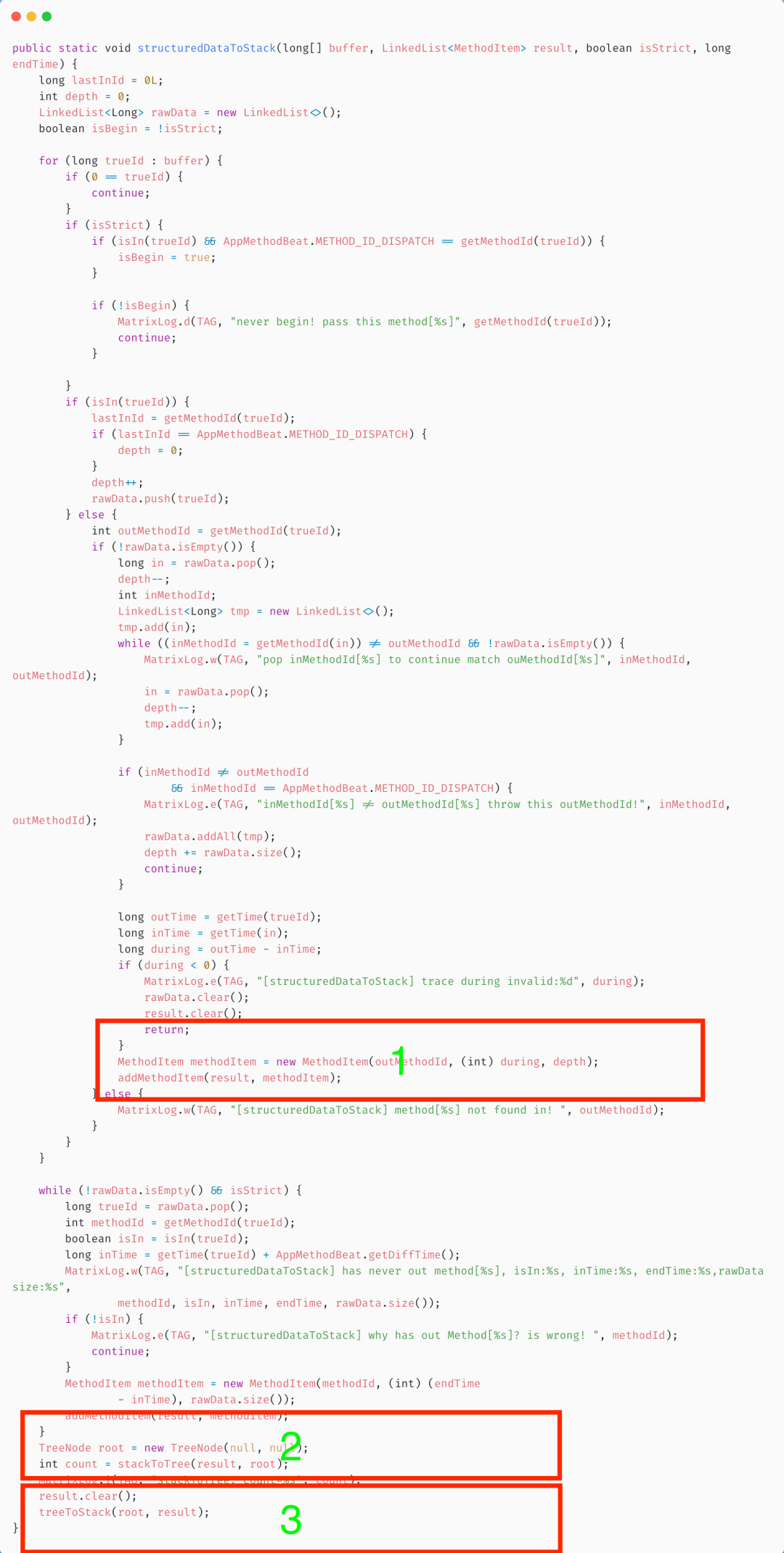
「1. 调用addMethodItem方法,将后序遍历结果push到栈中」
structuredDataToStack()中,如果是out方法,将会出栈,并且push到栈底。得到结果如下: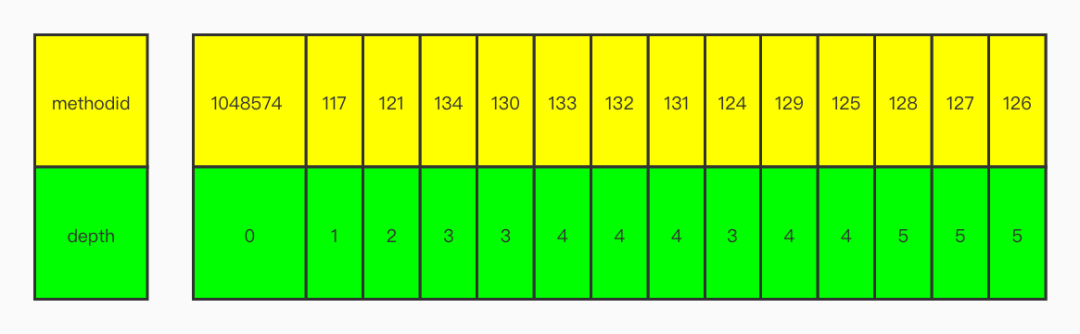
如果我们将队列反转过来,对照手画的树我们可知结果是「后序遍历。」
126 127 128 125 129 124 131 132 133 130 134 121 117 1048574
「2. 调用stackToTree()将队列转换成多叉树。」
结果和手画的树一样
「3. 调用treeToStack(),获得先序遍历结果」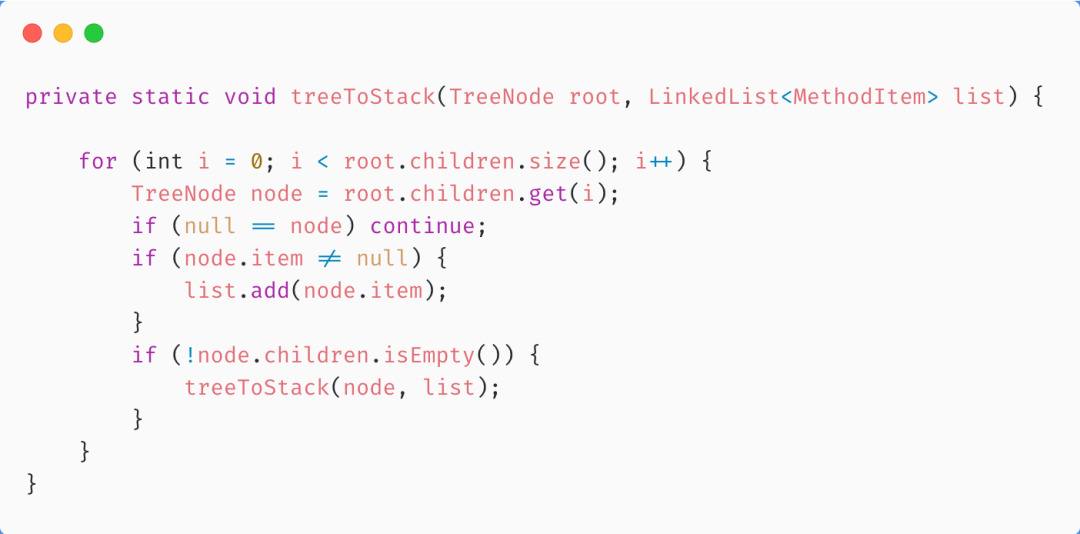 结果如下
结果如下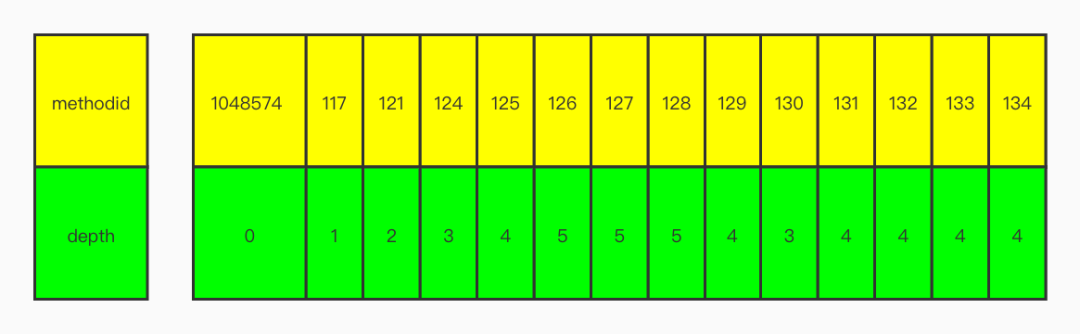
6.2.5 裁剪调用堆栈
Matrix默认最多上传30个堆栈。如果堆栈调用超过30条,需要裁剪堆栈。裁剪策略如下:
从后往前遍历先序遍历结果,如果堆栈大小大于30,则将执行时间小于5*整体遍历次数的节点剔除掉
最多整体遍历60次,每次整体遍历,比较时间增加5ms
如果遍历了60次,堆栈大小还是大于30,将后面多余的删除掉

6.2.5 堆栈信息生成key
如果某个方法调用时间大于整个主线程调用时长的0.3倍,会将该方法id记录到list中,最后排序,过滤。生成traceKey。
6.2.6 根据裁剪后的先序遍历结果生成上报堆栈
reportBuilder就是最终上报的堆栈信息。与文章开头的日志信息一致
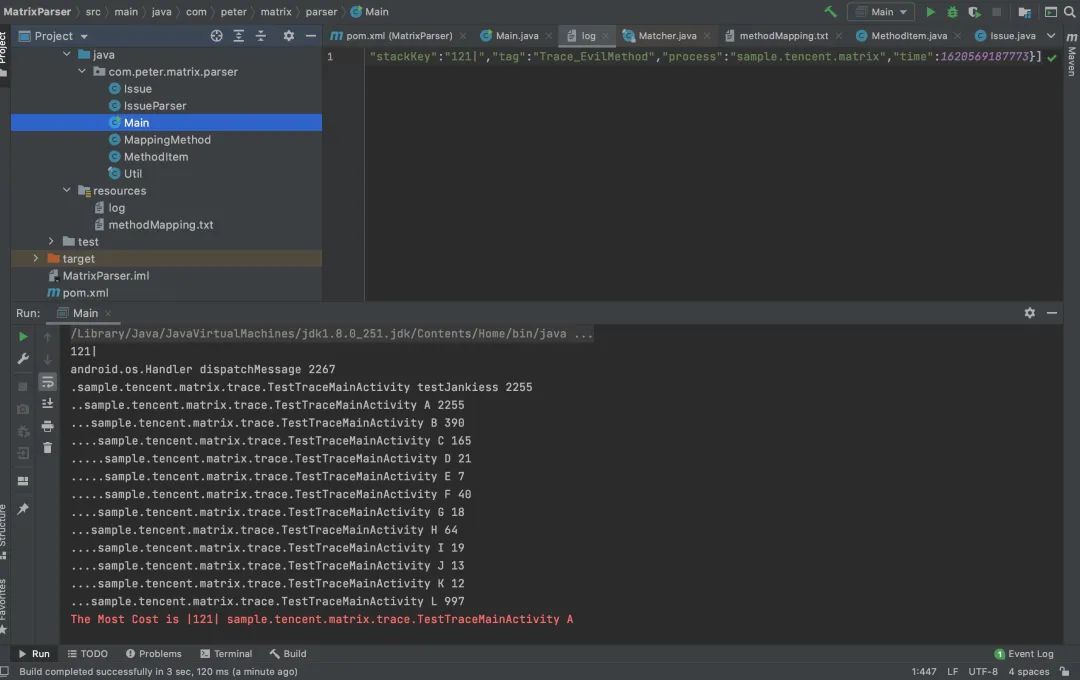
7. 解析日志
日志解析结果如下: