
数据仓库组件Data-Stash:助力区块链节点“轻装上阵”
当下,数据在全球经济运转中的价值日益凸显,与传统的土地、劳动力、资本、技术等并列,成为重要生产要素。
数据最终的价值来源于治理。只有经过采集、清洗、分析和处理后的数据,才能在流通中更顺畅地使用,其价值才能得到更充分地挖掘。同时,随着区块链技术的蓬勃发展,区块链渐趋规模化应用,链上数据总量呈指数级增长,其中蕴藏的巨大价值,也需要通过高效、规范的数据治理,才能得到充分彰显。
在区块链数据治理方面,微众银行区块链基于多年技术研究和应用实践经验,研发了一套数据治理通用组件(WeBankBlockchain-Data),多维提升开发、运营、运维效率,实现数据从要素到资源的转化。
目前,该套组件由数据仓库组件(Data-Stash)、数据导出组件(Data-Export)、数据对账组件(Data-Reconcile)三个相互独立、可插拔、可灵活组装的子组件构成,所有代码和文档均于2020年12月正式对外开源。详情可参考开源公告。
三个子组件面向不同角色解决相应的数据治理需求,业务、运营、开发、运维等不同角色,如何快速上手使用?我们将通过系列文章,抽丝剥茧解析每一个子组件的关键特性和使用方式。本文介绍数据仓库组件Data-Stash,欢迎大家积极体验并将使用诉求或优化建议反馈给我们。
认识Data-Stash
随着区块链业务不断运行,累积的海量链上数据会对区块链节点乃至网络的运维带来挑战。
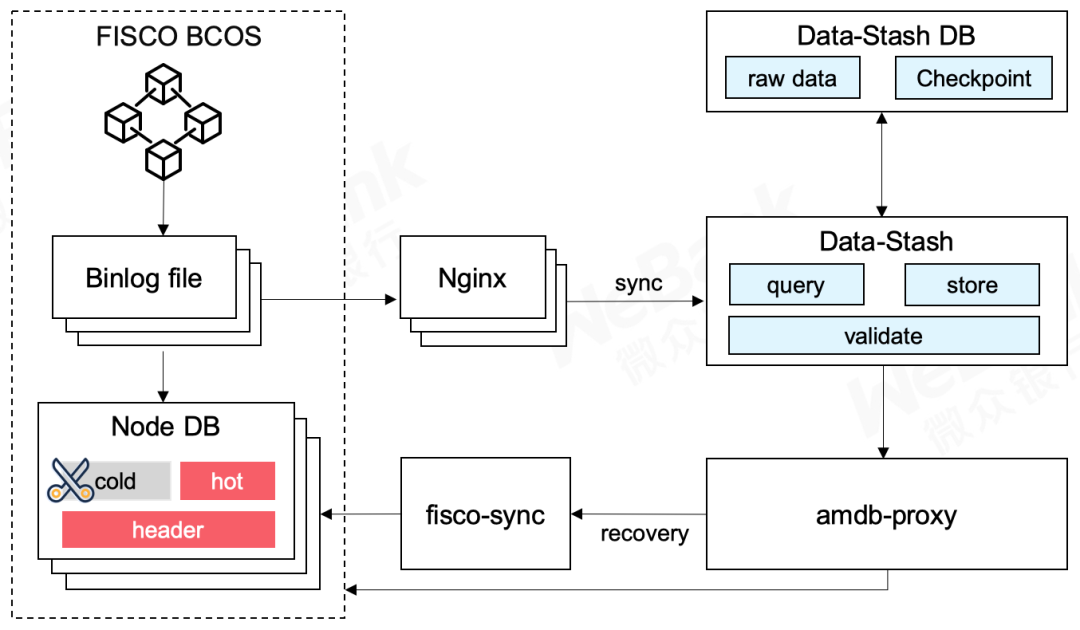

确保节点已经开启Binlog,如果节点未开启Binlog并已在运行,可先停止节点,删除群组数据、开启Binlog后再重启节点,节点即可重新同步并生成Binlog。 准备好一个第三方数据库,启动Data-Stash服务,将节点Binlog持续导入到该数据库中,实现全量备份。 开发者可对链上数据做一定划分,可将节点上不常用数据删除,特别是对于存证这样关联性较弱的业务,保留近期数据即可。 为了让节点运行不受影响,用户需要保证启用amdb,这样缺失的冷数据会自动从数据仓库读取,完成节点瘦身。 启用amdb请参考:
https://fisco-bcos-documentation.readthedocs.io/zh_CN/latest/docs/manual/data_governance.html#amdb-proxy
开发者可通过Data-Stash实现节点同步:
开发者需要通过Data-Stash生成全量数据备份。 当需要节点同步时,开发者可以通过FISCO BCOS项目下的fisco sync数据同步工具,将数据仓库导回到节点。这一过程不依赖于任何其他节点,所以同步不会占用区块链的网络资源。 fisco sync数据同步工具参考链接:
https://fisco-bcos-documentation.readthedocs.io/zh_CN/latest/docs/manual/data_governance.html#fisco-sync
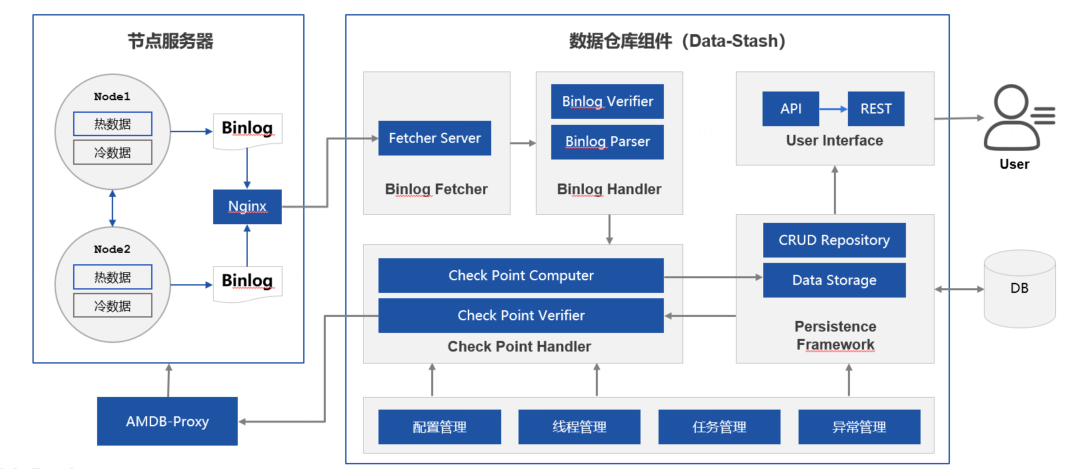


1)下载服务Fetcher Server
2)解析服务Binlog Parser
3)校验服务Binlog verifier
4)存储服务Data Storage
https://github.com/WeBankBlockchain/Data-Stash
