
Python+Selenium自动化测试:Page Object模式
Page Objects是selenium的一种测试设计模式,主要将每个页面看作是一个class。class的内容主要包括属性和方法,属性不难理解,就是这个页面中的元素对象,比如输入用户名的输入框,输入登陆密码的输入框、登陆按钮、这个页面的url等。而方法,主要是指这个页面可以提供的具体功能。
我们先看一段简单的代码如下:
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.implicitly_wait(30)
# 启动浏览器,访问百度
driver.get("http://www.baidu.com")
# 定位百度搜索框,并输入selenium
driver.find_element_by_id("kw").send_keys("selenium")
# 定位百度一下按钮并单击进行搜索
driver.find_element_by_id("su").click()
time.sleep(5)
driver.quit()
这是一个简单的小脚本。脚本维护看起来很简单。但随着时间测试套件的增长。随着你在代码中添加越来越多的行,事情变得艰难。脚本维护的主要问题是,如果10个不同的脚本使用相同的页面元素,并且该元素中的任何更改,则需要更改所有10个脚本。这是耗时且容易出错的。
更好的脚本维护方法是创建一个单独的类文件,它可以找到Web元素,填充或验证它们。该类可以在使用该元素的所有脚本中重用。将来,如果web元素有变化,我们需要在1个类文件中进行更改,而不是10个不同的脚本。
页面对象模型是为Web UI元素创建Object Repository的设计模式 。
在这个模型下,对于应用程序中的每个网页,应该有相应的页面类。
此Page类将会找到该Web页面的WebElements,并且还包含对这些WebElements执行操作的页面方法。
这些方法的名称应该按照他们正在执行的任务给出,即如果一个加载程序正在等待支付网关出现,POM方法名称可以是waitForPaymentScreenDisplay()。
下图为非POM和POM对比图:
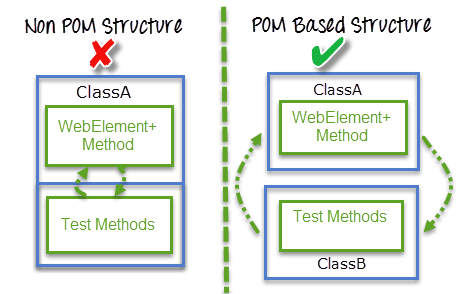
在自动化测试中,引入了Page Object Model(POM):页面对象模式来解决,POM能让我们的测试代码变得可读性更好,高可维护性,高复用性。
POM的优势:
POM提供了一种在UI层操作、业务流程与验证分离的模式,这使得测试代码变得更加清晰和高可读性。
对象库与用例分离,使得我们更好的复用对象,甚至能与不同的工具进行深度结合应用。
可复用的页面方法代码会变得更加优化。
更加有效的命名方式使得我们更加清晰的知道方法所操作的UI元素。例如我们要回到首页,方法名命名为: gotoHomePage(),通过方法名即可清晰的知道具体的功能实现。
以下是简单普通的登录测试用例:
def test_login_mail(self):
driver = self.driver
driver.get("http://www.xxx.xxx.com")
driver.find_element_by_id("idInput").clear()
driver.find_element_by_id("xxxxxxx").send_keys("xxxxx")
driver.find_element_by_id("xxxxxxx").clear()
driver.find_element_by_id("xxxxxxx").send_keys("xxxxxx")
driver.find_element_by_id("loginBtn").click()
那我们如何进行一个改造升级呢?
改造案例思路:
1.我们要分离测试对象(元素对象)和测试脚本(用例脚本),那么我们分别创建两个脚本文件,分别为:LoginPage.py 用于定义页面元素对象,每一个元素都封装成组件(可以看做存放页面元素对象的仓库) CaseLoginTest.py 测试用例脚本。
2.设计实现思想,一切元素和元素的操作组件化定义在Page页面,用例脚本页面,通过调用Page中的组件对象,进行拼凑成一个登录脚本。
BasePage.py:
#-*- coding: utf-8-*-
from selenium.webdriver.support.wait importWebDriverWait
from seleniumimport webdriver
classAction(object):
"""
BasePage封装所有页面都公用的方法,例如driver, url ,FindElement等
"""
#初始化driver、url、等
def __init__(self,selenium_driver, base_url, pagetitle):
self.base_url = base_url
self.pagetitle = pagetitle
self.driver = selenium_driver
#打开页面,校验页面链接是否加载正确
def _open(self,url, pagetitle):
#使用get打开访问链接地址
self.driver.get(url)
self.driver.maximize_window()
#使用assert进行校验,打开的链接地址是否与配置的地址一致。调用on_page()方法
assertself.on_page(pagetitle), u"打开开页面失败 %s"% url
#重写元素定位方法
def find_element(self,*loc):
#returnself.driver.find_element(*loc)
try:
WebDriverWait(self.driver,10).until(lambdadriver: driver.find_element(*loc).is_displayed())
return self.driver.find_element(*loc)
except:
print u"%s 页面中未能找到 %s 元素"%(self, loc)
#重写switch_frame方法
def switch_frame(self, loc):
return self.driver.switch_to_frame(loc)
#定义open方法,调用_open()进行打开链接
def open(self):
self._open(self.base_url, self.pagetitle)
#使用current_url获取当前窗口Url地址,进行与配置地址作比较,返回比较结果(True False)
def on_page(self,pagetitle):
return pagetitlein self.driver.title
#定义script方法,用于执行js脚本,范围执行结果
def script(self,src):
self.driver.execute_script(src)
#重写定义send_keys方法
def send_keys(self, loc, vaule, clear_first=True, click_first=True):
try:
loc = getattr(self,"_%s"% loc)
if click_first:
self.find_element(*loc).click()
if clear_first:
self.find_element(*loc).clear()
self.find_element(*loc).send_keys(vaule)
exceptAttributeError:
print u"%s 页面中未能找到 %s 元素"%(self, loc)
LoginPage.py:
#-*- coding: utf-8-*-
from selenium.webdriver.common.by importBy
import BasePage
#继承BasePage类
class LoginPage(BasePage.Action):
#定位器,通过元素属性定位元素对象
username_loc=(By.ID,"idInput")
password_loc =(By.ID,"pwdInput")
submit_loc =(By.ID,"loginBtn")
span_loc=(By.CSS_SELECTOR,"div.error-tt>p")
dynpw_loc =(By.ID,"lbDynPw")
userid_loc =(By.ID,"spnUid")
#Action
def open(self):
#调用page中的_open打开连接
self._open(self.base_url,self.pagetitle)
#调用send_keys对象,输入用户名
def input_username(self, username):
self.find_element(*self.username_loc).send_keys(username)
#调用send_keys对象,输入密码
def input_password(self, password):
self.find_element(*self.password_loc).send_keys(password)
#调用send_keys对象,点击登录
def click_submit(self):
self.find_element(*self.submit_loc).click()
#用户名或密码不合理是Tip框内容展示
def show_span(self):
returnself.find_element(*self.span_loc).text
#切换登录模式为动态密码登录(IE下有效)
def swich_DynPw(self):
self.find_element(*self.dynpw_loc).click()
#登录成功页面中的用户ID查找
def show_userid(self):
returnself.find_element(*self.userid_loc).text
Caselongintest.py:
#-*- coding: utf-8-*-
import sys
reload(sys)
sys.setdef aultencoding('utf-8')
import unittest
from POimportLoginPage
from seleniumimport webdriver
classCaselogin126mail(unittest.TestCase):
"""
登录case
"""
@classmethod
def setUpClass(cls):
cls.driver = webdriver.Chrome()
cls.driver.implicitly_wait(30)
cls.url ="http://xxxx.xxx.com"
cls.username ="xxxxx"
cls.password ="xxxxx"
#用例执行体
def test_login_mail(self):
#声明LoginPage类对象
login_page=LoginPage.LoginPage(self.driver, self.url, u”xxxxx”)
#调用打开页面组件
login_page.open()
#调用用户名输入组件
login_page.input_username(self.username)
#调用密码输入组件
login_page.input_password(self.password)
#调用点击登录按钮组件
login_page.click_submit()
@classmethod
def tearDownClass(cls):
cls.driver.quit()
if __name__=="__main__":
unittest.main()
使用POM进行重新构造代码结构后,发现代码测试用例代码的可读性提高很多,元素写成组件的方式,不需要每次都写findElement直接在脚本中调用组件就可以使用。
在CaseLoginTest脚本用例执行体中,一旦我们输入 login_page并敲入一个点时,LoginPage页面中的元素对象组件都显示出来。并且定义好的PageObject组件可以重复在其它的脚本中进行使用,减少了代码的工作量,也方便对脚本进行后期的维护管理,当元素属性发生变化时,我们只需要对一个PageObaject页面中的对象组件定义进行更改即可。
最后做个总结,所有代码请手动输入,不要直接拷贝。再次对POM进行小结:
POM是selenium webdriver自动化测试实践对象库设计模式
POM使得测试脚本更易于维护
POM通过对象库方式进一步优化了元素、用例、数据的维护组织
PS: 最近由狂师老师授课主讲的「全栈测试开发技能训练营」二期已经开班了,课程内容非常值得推荐,课程深入、实用!想提升测开能力的同学,推荐报名,课程大纲:重磅消息 | 2021年最新全栈测试开发技能实战指南(第2期)
END

长按二维码/微信扫码 添加作者
阅读原文