
同事说,我写Java代码像写诗
点击关注公众号,Java干货及时送达👇

文章来源:http://33h.co/kntu3
前几天空闲时间写了一遍关于平时自己写代码的一些习惯,这里跟大家分享一下。
定义配置文件信息✦
有时候我们为了统一管理会把一些变量放到 yml 配置文件中。
例如:
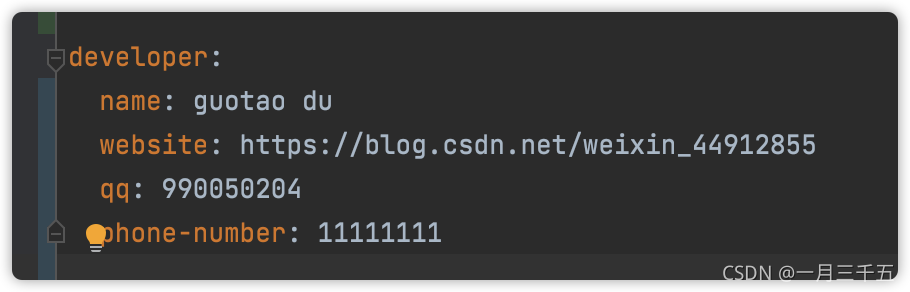
用 @ConfigurationProperties 代替 @Value。
使用方法:
定义对应字段的实体:
@Data
// 指定前缀
@ConfigurationProperties(prefix = "developer")
@Component
public class DeveloperProperty {
private String name;
private String website;
private String qq;
private String phoneNumber;
}
使用时注入这个 bean:
@RestController
@RequiredArgsConstructor
public class PropertyController {
final DeveloperProperty developerProperty;
@GetMapping("/property")
public Object index() {
return developerProperty.getName();
}
}
用@RequiredArgsConstructor代替@Autowired✦
我们都知道注入一个 bean 有三种方式哦(set 注入,构造器注入,注解注入),spring 推荐我们使用构造器的方式注入 Bean。

RequiredArgsConstructor:lombok 提供。
代码模块化✦
阿里巴巴 Java 开发手册中说到每个方法的代码不要超过 50 行(我没记错的话)。
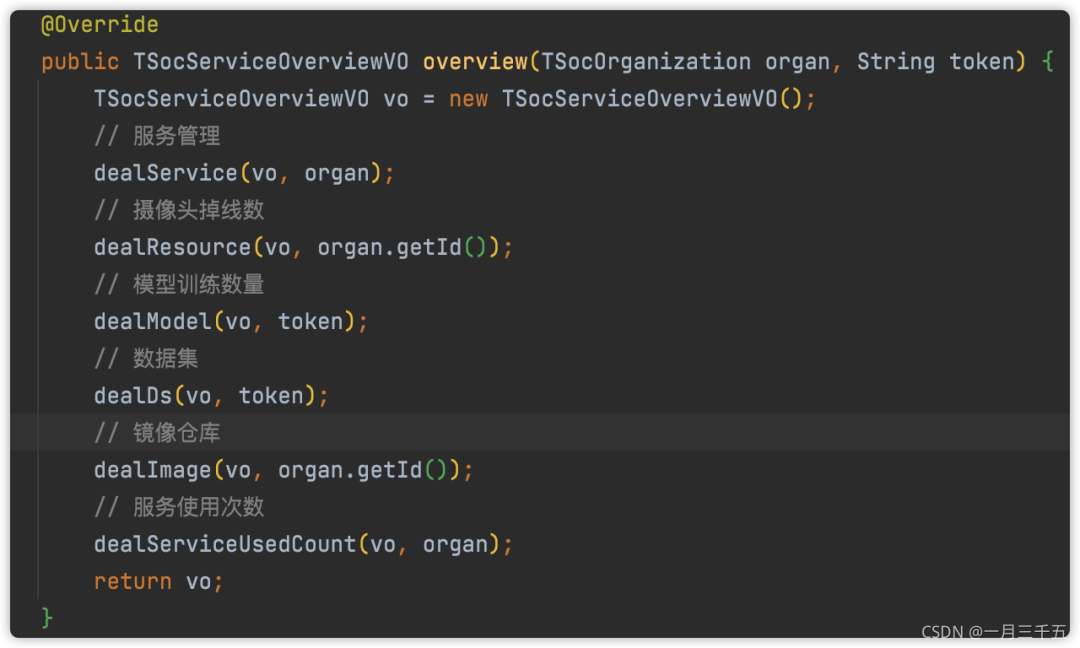
抛异常而不是返回✦
在写业务代码的时候,经常会根据不同的结果返回不同的信息,尽量减少返回,会显得代码比较乱。

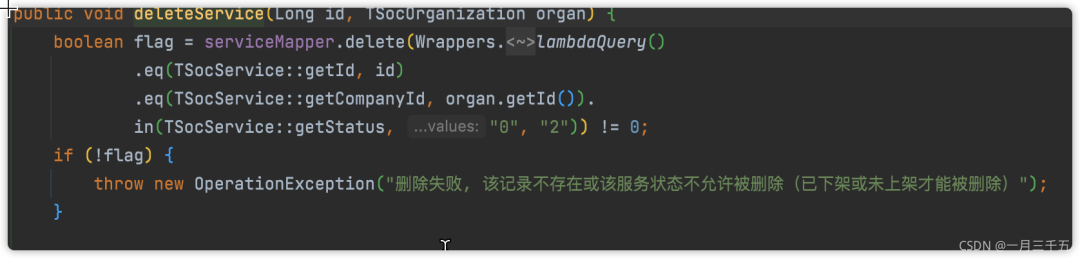
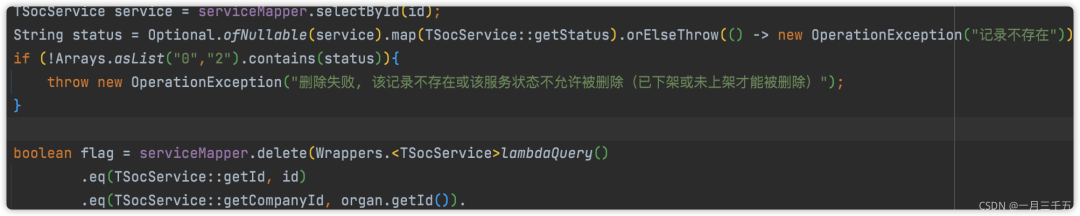
减少不必要的db✦
尽可能的减少对数据库的查询。
举例子:删除一个服务(已下架或未上架的才能删除),之前有看别人写的代码,会先根据 id 查询该记录,然后做一些判断。

不要返回null✦
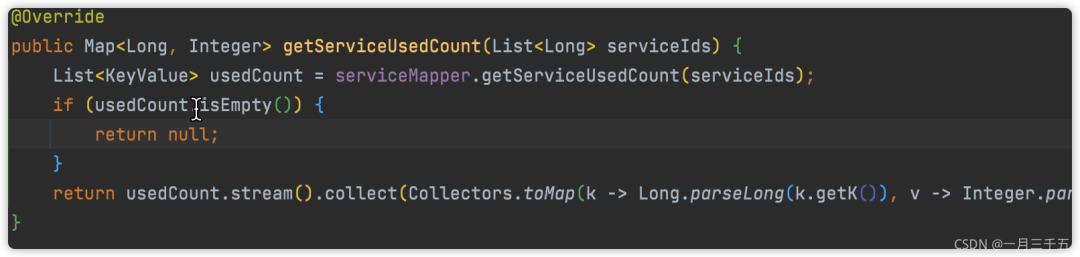
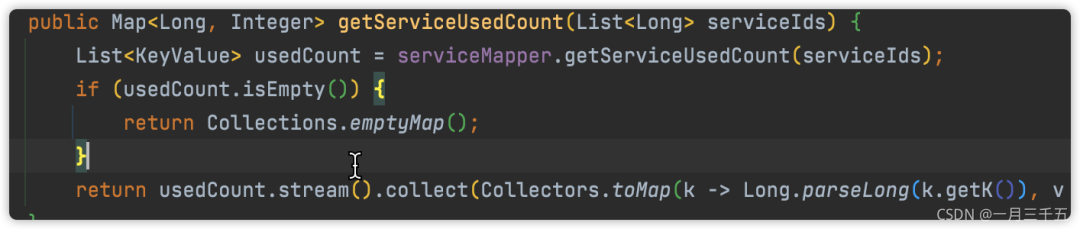
别处调用方法时,避免不必要的空指针。
if else✦
不要太多了 if else if,可以试试策略模式代替。
减少controller业务代码✦
业务代码尽量放到 service 层进行处理,后期维护起来也好操作而且美观。

利用好Idea✦
目前为止市面上的企业基本都用 idea 作为开发工具了吧。
举一个小例子:idea 会对我们的代码进行判断,提出合理的建议。

它推荐我们用 lanbda 的形式代替。

阅读源码✦
一定要养成阅读源码的好习惯包括优秀的开源项目 GitHub上stars:>1000,会从中学好好多知识包括其对代码的设计思想以及高级 API,面试加分(好多面试官习惯问源码相关的知识)。
设计模式✦
23 种设计模式,要尝试代码中运用设计模式思想,写出的代码即规范又美观还高大上,哈哈。
拥抱新知识✦
像我们这种工作年限少的程序员,我觉得要多学习自己认知之外的知识,不能每天 crud,有机会就多用用有点难度的知识,没有机会(项目较传统),可以自己下班多些相关 demo 练习。
基础问题✦
HashMap<String, String> map = new HashMap<>();
map.put("name", "du");
for (String key : map.keySet()) {
String value = map.get(key);
}
map.forEach((k, v) -> {
});
// 推荐
for (Map.Entry<String, String> entry : map.entrySet()) {
}
//获取子目录列表
public List getChild(String pid) {
if (V.isEmpty(pid)) {
pid = BasicDic.TEMPORARY_DIRECTORY_ROOT;
}
CatalogueTreeNode node = treeNodeMap.get(pid);
return Optional.ofNullable(node)
.map(CatalogueTreeNode::getChild)
.orElse(Collections.emptyList());
}
递归
大数据量的递归时,避免在递归方法里 new 对象,可以试试把对象当作方法参数进行传递使用
注释
类、接口方法、注解、较复杂的方法,注释都要写而且要写清楚,有时候写注释不是给别人看的,而是给自己看的
判断元素是否存在✦
hashSet 而不是 list
ArrayList list = new ArrayList<>();
// 判断a是否在list中
for (int i = 0; i < list.size(); i++)
if ("a".equals(elementData[i]))
return i;
由此可见其复杂度为 On
HashSet<String> set = new HashSet<>();
// 判断a是否在set中
int index = hash(a);
return getNode(index) != null
由此可见其复杂度为 O1。
统一管理线程池✦
private static volatile ThreadPoolExecutor threadPoolExecutor = null;
private static final int CORE_POOL_SIZE = 0;
private static final int MAX_MUM_POOL_SIZE = 1000;
private static final long KEEP_ALIVE_TIME = 2;
private static final TimeUnit UNIT = TimeUnit.MINUTES;
private static final int CAPACITY = 1;
private static final RejectedExecutionHandler HANDLER = new ThreadPoolExecutor.CallerRunsPolicy();
private static final BasicThreadFactory factory =
new BasicThreadFactory.Builder().namingPattern("aiserviceplatform-util-thread-pool-%d").build();
private ThreadPoolFactory() {
}
public static ThreadPoolExecutor getInstance() {
if (threadPoolExecutor == null) {
synchronized (ThreadPoolFactory.class) {
if (threadPoolExecutor == null) {
threadPoolExecutor = new ThreadPoolExecutor(CORE_POOL_SIZE, MAX_MUM_POOL_SIZE, KEEP_ALIVE_TIME, UNIT, new ArrayBlockingQueue<>(CAPACITY), factory, HANDLER);
}
}
}
return threadPoolExecutor;
}
大量数据同步✦
String realTabelName = ....;
String tempTableName = realTableName + "_temp";
createTable(tempTableName); // 创建临时表
boolean flag = sync(tempTableName); // 同步数据
// 根据结果
if(flag) {
dropTable(realTabelName);
alterTabelName(realTableName, tempTableName); // 临时表改名 实际表
}else {
// 同步失败 删除临时表
dropTabel(tempTableName)
}
实测:比对一张表做处理会快很多而且不会出问题。
接口入参✦
定义接口的方法时,如接受一个集合类型,尽可能的用 Collection
Collection<String> getNodeIds(Collection<String> ids);
锁的颗粒度✦
同步方法直接在方法上加 synchronized 实现加锁,同步代码块则在方法内部加锁,很明显,同步方法锁的范围比较大,而同步代码块范围要小点,一般同步的范围越大,性能就越差,一般需要加锁进行同步的时候,肯定是范围越小越好,这样性能更好
我一般使用 lock:ReentrantLock,ReentrantReadWriteLock,减少锁的颗粒度,提高系统的并发能力。
缓存名称✦
简短,精练,以文件夹形式保存,xxx:xxx:xxx,以:隔开。
方便查看缓存信息。
@Cacheable✦
使用 Cacheable 做缓存时,也要加上缓存失效时间。

@Bean
public CacheManager cacheManager(RedisConnectionFactory factory) {
return new RedisCacheManager(
RedisCacheWriter.lockingRedisCacheWriter(factory),
this.getRedisCacheConfigurationWithTtl(1),
this.getRedisCacheConfigurationMap()
);
}
private RedisCacheConfiguration getRedisCacheConfigurationWithTtl(Integer hour) {
Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.activateDefaultTyping(LaissezFaireSubTypeValidator.instance, ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
return RedisCacheConfiguration.defaultCacheConfig().serializeValuesWith(
RedisSerializationContext
.SerializationPair
.fromSerializer(jackson2JsonRedisSerializer)).entryTtl(Duration.ofHours(hour));
}
public static final String REGION_LIST_BY_CODE_CACHE_KEY = "region:list";
public static final String REGION_NAME_BY_CODE_CACHE_KEY = "region:name";
/**
* 已知缓存名称的映射以及用于这些缓存的配置
*/
private Map<String, RedisCacheConfiguration> getRedisCacheConfigurationMap() {
Map<String, RedisCacheConfiguration> redisCacheConfigurationMap = new HashMap<>();
// 自定义缓存名称对应的配置
redisCacheConfigurationMap.put(REGION_LIST_BY_CODE_CACHE_KEY, this.getRedisCacheConfigurationWithTtl(24));
redisCacheConfigurationMap.put(REGION_NAME_BY_CODE_CACHE_KEY, this.getRedisCacheConfigurationWithTtl(120));
redisCacheConfigurationMap.put(RedisKey.MARK_SERVICE_RENEW, this.getRedisCacheConfigurationWithTtl(-1));
redisCacheConfigurationMap.put(RedisKey.MARK_ORGAN_RENEW, this.getRedisCacheConfigurationWithTtl(-1));
redisCacheConfigurationMap.put(RedisKey.MARK_SERVICE_STREAM, this.getRedisCacheConfigurationWithTtl(-1));
redisCacheConfigurationMap.put(RedisKey.MARK_ORGAN_STREAM, this.getRedisCacheConfigurationWithTtl(-1));
return redisCacheConfigurationMap;
}
异步任务✦
为了提高接口的响应速度,我们会把比较耗时的操作异步处理。例如异步任务,消息队列等。
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
获取方式:点“在看”,关注公众号并回复 Java 领取,更多内容陆续奉上。
PS:因公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。
点“在看”支持小哈呀,谢谢啦😀
