
通过 eBPF 深入探究 Go GC
对程序员来说,内存管理是很重要的。编程语言按内存管理方式一般可以分为手动内存管理和自动内存管理。手动内存管理典型代表有 C、C++;自动内存管理代表有 Java、C# 等。通常,自动内存管理即自带垃圾收集器,即 GC(当然,Rust 另辟蹊径,它既没有 GC,也不需要手动内存管理,感兴趣的可以了解下)。Go 语言也采用了 GC 的方式管理内存,虽然 Gopher 不需要手动管理内存了,但了解 Go 如何分配和释放内存可以让我们编写更好、更高效的应用程序。垃圾收集器是这个难题的关键部分。本文就探讨 Go 中的 GC。
为了更好地理解垃圾收集器的工作原理,我决定在实时应用程序上跟踪它的底层行为。本文将使用 eBPF uprobes 检测 Go 垃圾收集器。这篇文章的源代码在这里[1]。
1、前提知识
在深入研究之前,让我们快速了解一下 uprobes、垃圾收集器的设计以及我们将使用的演示应用程序。
为什么用 uprobes?
uprobes[2] 很酷,因为它们让我们无需修改代码即可动态收集新信息。当你不能或不想重新部署你的应用程序时,这会非常有用。
函数参数、返回值、延迟和时间戳都可以通过 uprobes 收集。在这篇文章中,我将把 uprobes 部署到 Go 垃圾收集器的关键函数上。这让我们能看到它在正在运行的应用程序中的实际表现。
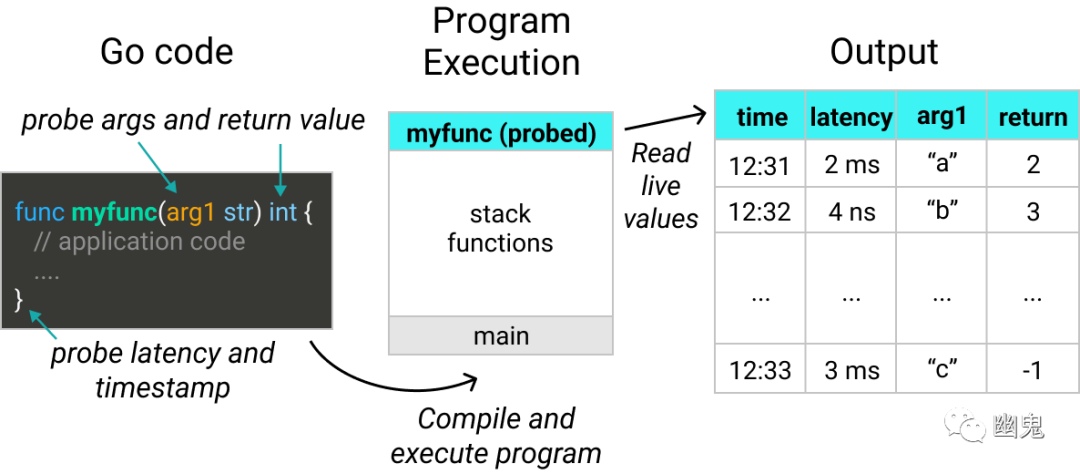
uprobes 可以跟踪延迟、时间戳、参数和函数的返回值片
注意:这篇文章使用的 Go 版本是 1.16。我将在 Go 运行时中跟踪私有函数,因此这些功能在 Go 的后续版本中可能会发生变化。
垃圾回收的阶段
Go 使用并发标记和清除垃圾收集器。对于那些不熟悉这些术语的人,阅读以下内容,方便你理解本文其他内容。
https://agrim123.github.io/posts/go-garbage-collector.html https://en.wikipedia.org/wiki/Tracing_garbage_collection https://go.dev/blog/ismmkeynote https://www.iecc.com/gclist/GC-algorithms.html
Go 的垃圾收集器被称为并发的,因为它可以安全地与主程序并行运行。换句话说,它不需要停止你程序的执行来完成它的工作(稍后会详细介绍)。
垃圾收集有两个主要阶段:
标记(Mark)阶段:识别并标记程序不再需要的对象。
清除(Sweep)阶段:对于标记阶段标记为“无法访问”的每个对象,释放内存以供其他地方使用。
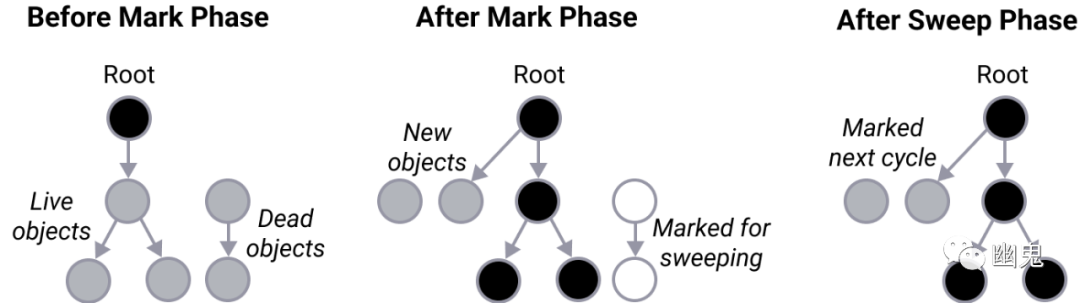
一个简单的演示应用程序
这是一个简单的端点(endpoint),我将使用它来触发垃圾收集器。它创建一个可变大小的字符串数组,然后通过调用 runtime.GC() 来启动垃圾收集器。
实际代码中,你不需要手动调用垃圾收集器,因为 Go 会自动为你处理。
http.HandleFunc("/allocate-memory-and-run-gc", func(w http.ResponseWriter, r *http.Request) {
arrayLength, bytesPerElement := parseArrayArgs(r)
arr := generateRandomStringArray(arrayLength, bytesPerElement)
fmt.Fprintf(w, fmt.Sprintf("Generated string array with %d bytes of data\n", len(arr) * len(arr[0])))
runtime.GC()
fmt.Fprintf(w, "Ran garbage collector\n")
})
2、跟踪垃圾收集的主要阶段
我们已经了解了 uprobes 和 Go 垃圾收集器的基础知识,接下来深入观察它的行为。
跟踪 runtime.GC()
首先,我们计划在 Go 的 runtime 库中的以下函数中添加 uprobes:
| 函数 | 描述 |
|---|---|
| GC[3] | 调用 GC |
| gcWaitOnMark[4] | 等待标记阶段完成 |
| gcSweep[5] | 执行清除阶段 |
(如果你有兴趣了解 uprobes 是如何生成的,这里是代码[6]。)
部署 uprobes 后,点击端点并生成了一个包含 10 个字符串的数组,每个字符串为 20 个字节。
$ curl '127.0.0.1:8080/allocate-memory-and-run-gc?arrayLength=10&bytesPerElement=20'
Generated string array with 200 bytes of data
Ran garbage collector
这时 uprobes 会观察到以下事件:
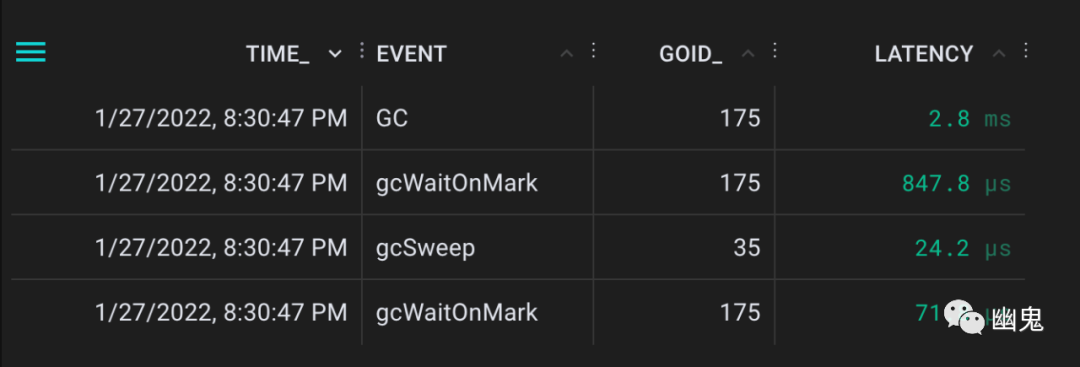
从源代码[7]来看这是有道理的——gcWaitOnMark被调用两次,一次是在开始下一个循环之前对前一个循环进行验证。标记阶段触发清除阶段。
接下来,使用各种输入请求 /allocate-memory-and-run-gc 端点对 runtime.GC 后的延迟进行了一些测量。
| arrayLength | bytesPerElement | Approximate size (B) | GC latency (ms) | GC throughput (MB/s) |
|---|---|---|---|---|
| 100 | 1,000 | 100,000 | 3.2 | 31 |
| 1,000 | 1,000 | 1,000,000 | 8.5 | 118 |
| 10,000 | 1,000 | 10,000,000 | 53.7 | 186 |
| 100 | 10,000 | 1,000,000 | 3.2 | 313 |
| 1,000 | 10,000 | 10,000,000 | 12.4 | 807 |
| 10,000 | 10,000 | 100,000,000 | 96.2 | 1,039 |
跟踪标记和清除阶段
虽然这是一个很好的高级视图,但我们可以使用更多细节。接下来探索一些用于内存分配、标记和清除的辅助函数,以获取下一级信息。
这些辅助函数有参数或返回值,可以帮助我们更好地可视化正在发生的事情(例如分配的内存页)。
| 函数 | 描述 | 捕获的信息 |
|---|---|---|
| allocSpan[8] | 分配新内存 | 分配的内存页 |
| gcDrainN[9] | 执行 N 个单位的标记工作 | 完成的标记工作单位 |
| sweepone[10] | 从 span 中清除内存 | 清除的内存页 |
$ curl '127.0.0.1:8080/allocate-memory-and-run-gc?arrayLength=20000&bytesPerElement=4096'
Generated string array with 81920000 bytes of data
Ran garbage collector
在以更大的负载命中垃圾收集器之后,以下是原始结果:
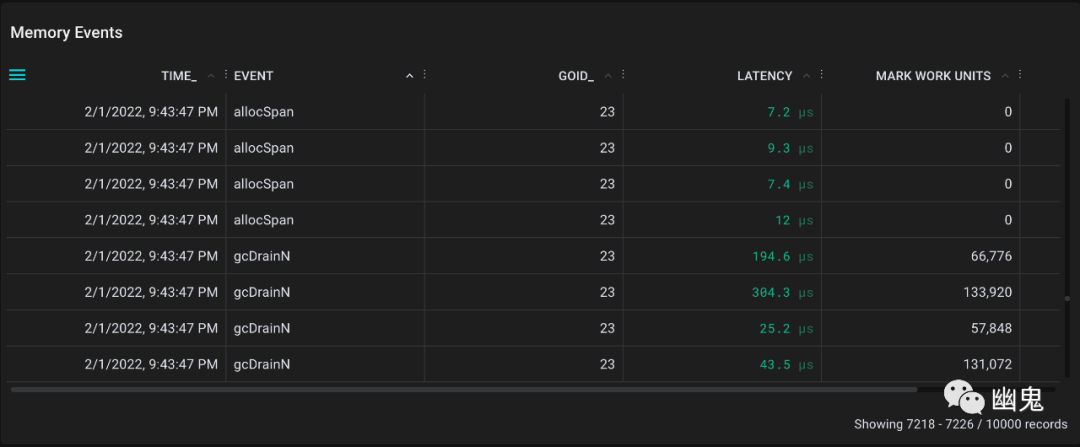
绘制为时间序列更容易解释:
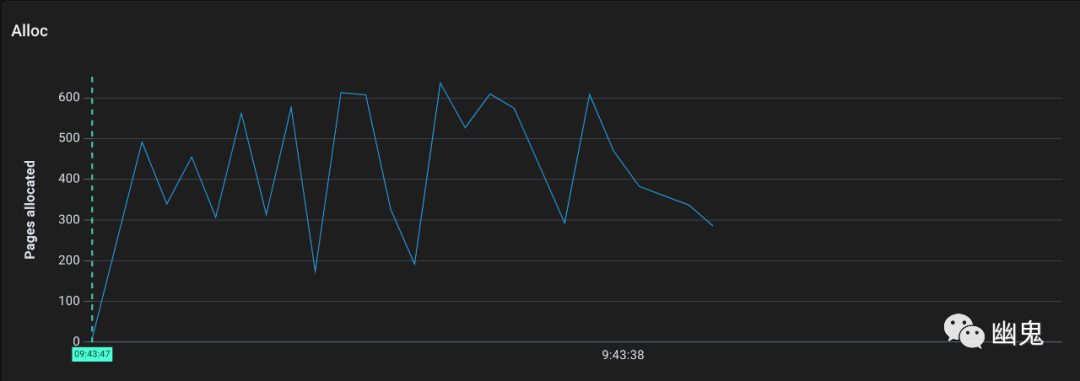
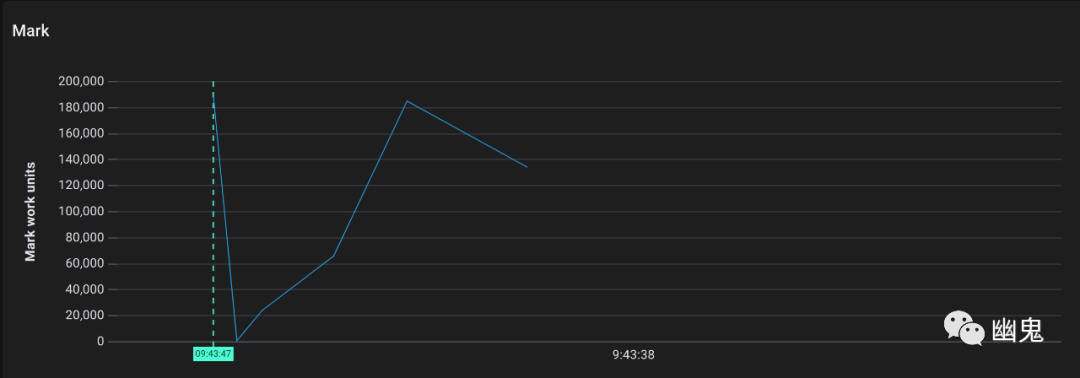
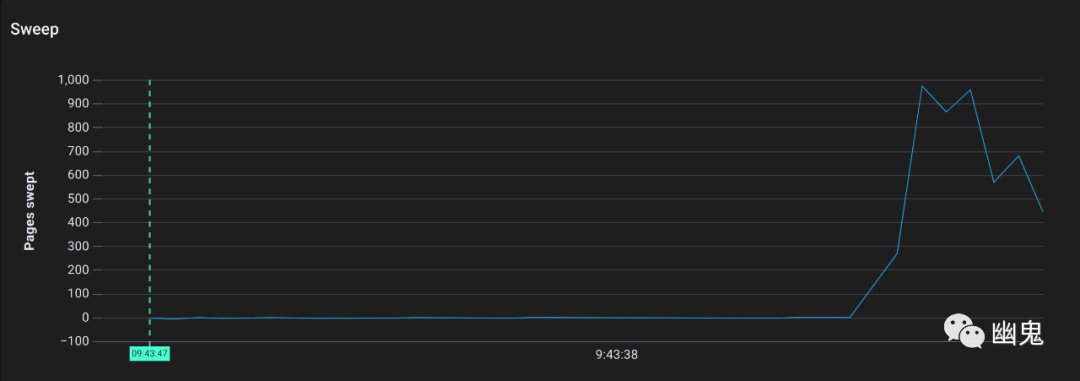
现在我们可以看到发生了什么:
Go 分配了几千内存页,这是正常的,因为我们直接向堆中添加了大约 80MB 的字符串。 标记工作拉开了序幕(注意它的单位不是页,而是标记工作单位) 有标记的内存页被清除器清除。(这应该是所有内存页,因为在调用完成后我们不会重用字符串数组)。
追踪 Stop The World 事件
“Stopping the world”是指垃圾收集器暂时停止除自身之外的一切,以安全地修改状态。我们通常更喜欢最小化 STW 阶段,因为 STW 会减慢我们的程序速度(通常是在最不方便的时候……)。
一些垃圾收集器会在垃圾收集运行的整个过程中 stop the world。这些是“非并发”垃圾收集器。虽然 Go 的垃圾收集器在很大程度上是并发的,但我们可以从代码中看到,它在技术上确实在两个地方 STW 了。
我们跟踪以下函数:
| 函数 | 描述 |
|---|---|
| stopTheWorldWithSema[11] | 停止其他 goroutine 直到startTheWorldWithSema被调用 |
| startTheWorldWithSema[12] | 启动暂停的 goroutine |
再次触发 GC:
$ curl '127.0.0.1:8080/allocate-memory-and-run-gc?arrayLength=10&bytesPerElement=20'
Generated string array with 200 bytes of data
Ran garbage collector
这次产生了如下事件:
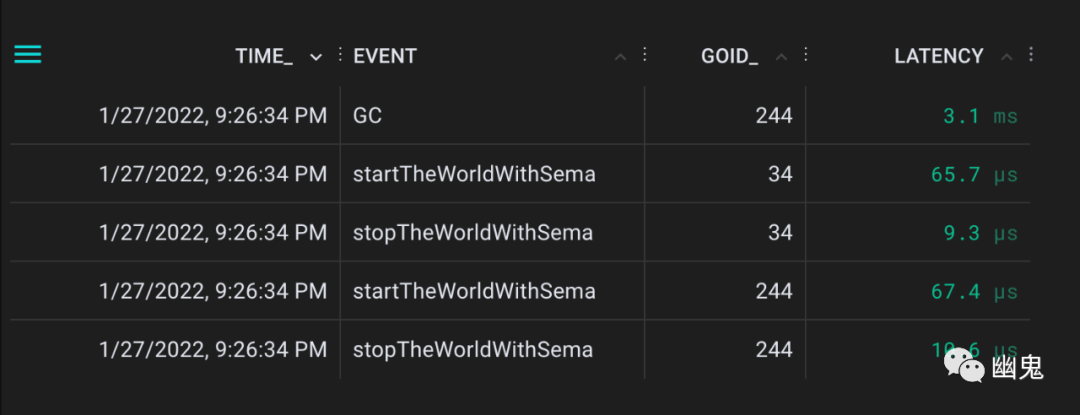
我们可以从GC事件中看到垃圾收集需要 3.1 毫秒才能完成。在我检查了确切的时间戳之后,事实证明 STW 第一次停止了 300 µs,第二次停止了 365 µs。换句话说,~80%垃圾收集是同时执行的。当垃圾收集器在实际内存压力下自动调用时,我们预计这个比率会变得更好。
为什么 Go 垃圾收集器需要 STW?
1st Stop The World(标记阶段之前):设置状态并打开写屏障。写屏障确保在 GC 运行时正确跟踪新的写入(这样它们就不会被意外释放或保留)。
2nd Stop The World(标记阶段之后):清理标记状态并关闭写屏障。
3、垃圾收集器如何调整自己的速度?
知道何时运行垃圾收集是 Go 等并发垃圾收集器的重要考虑因素。
早期的垃圾收集器被设计为一旦达到一定的内存消耗水平就会启动。如果垃圾收集器是非并发的,这可以正常工作。但是使用并发垃圾收集器,主程序在垃圾收集期间仍在运行 —— 因此可能仍在进行内存分配。
这意味着如果太晚运行垃圾收集器,可能会超出内存目标。(Go 也不能一直运行垃圾收集 —— GC 会从主应用程序中夺走资源和性能。)
Go 的垃圾收集器使用 pacer[13] 来估计垃圾收集的最佳时间。这有助于 Go 满足其内存和 CPU 目标,而不会牺牲不必要的应用程序性能。
pacer,可以理解为定速装置
触发率
Go 的并发垃圾收集器依赖于一个 pacer 来确定何时进行垃圾收集。但它是如何做出这个决定的呢?
每次调用垃圾收集器时,pacer 都会更新其内部目标,即下次应该何时运行 GC。这个目标称为触发率。触发率0.6意味着一旦堆大小增加 60%,系统应该运行垃圾收集。触发率是CPU、内存和其他因素共同决定的数字。
让我们看看当我们一次分配大量内存时,垃圾收集器的触发率是如何变化的。我们可以通过跟踪函数来获取触发率gcSetTriggerRatio。
$ curl '127.0.0.1:8080/allocate-memory-and-run-gc?arrayLength=20000&bytesPerElement=4096'
Generated string array with 81920000 bytes of data
Ran garbage collector
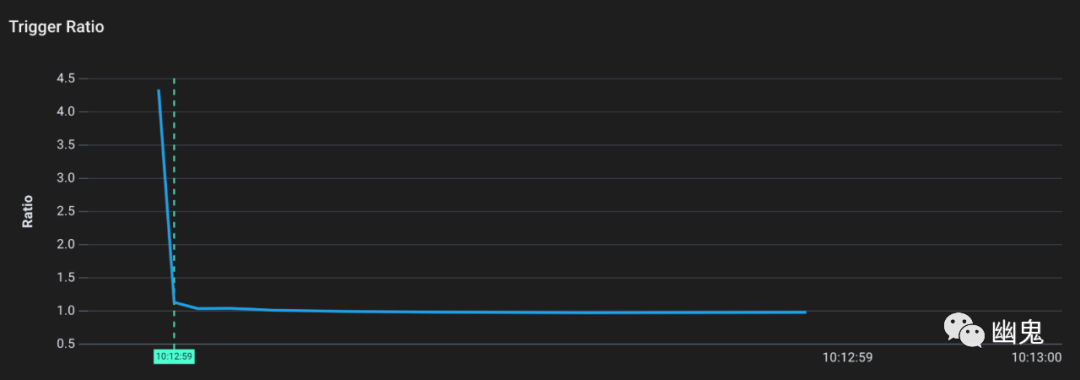
从图中可以看到,最初,触发率相当高。运行时已经确定,在程序使用 450% 或更多内存之前,不需要进行垃圾收集。这是有道理的,因为应用程序没有做太多事情(并且没有使用很多堆)。
然而,一旦我们请求端点进行 ~81MB 堆分配时,触发率迅速下降到 ~1。现在如果增加 100% 的内存就可以进行垃圾收集(因为我们的内存消耗增加了)。
标记和清除助手
当分配内存但不调用垃圾收集器会发生什么?接下来,请求 /allocate-memory 端点,它和 /allocate-memory-and-gc 类似,但不调用 runtime.GC()。
$ curl '127.0.0.1/allocate-memory?arrayLength=10000&bytesPerElement=10000'
Generated string array with 100000000 bytes of data
根据最近的触发率,垃圾收集器应该还没有启动。但是,我们看到标记和清除仍然发生了:
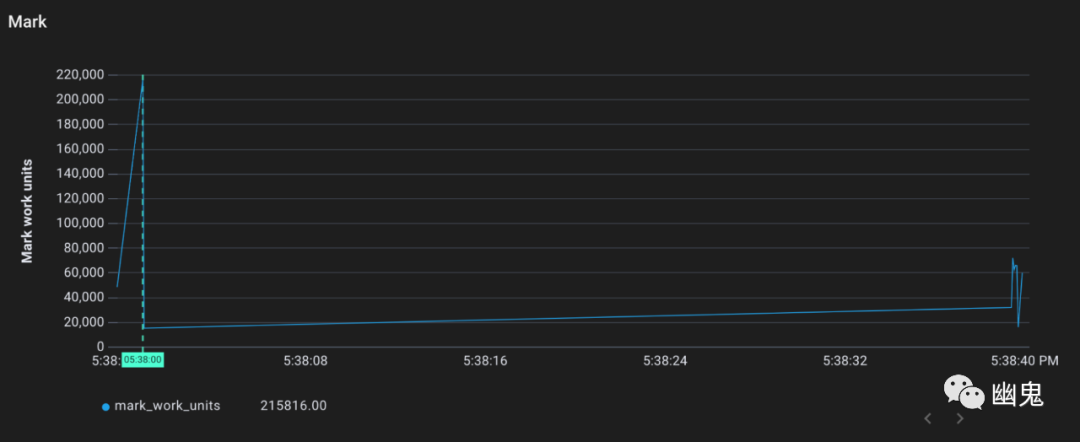
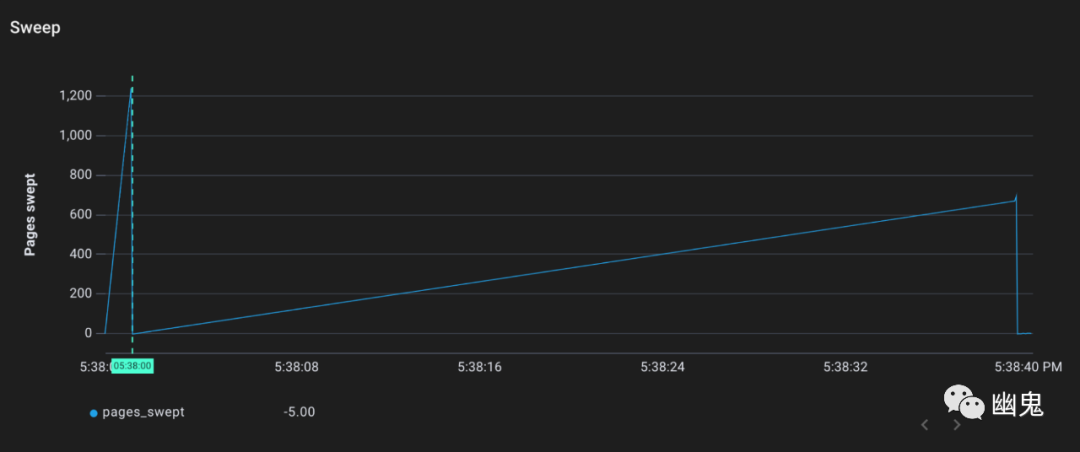
事实证明,垃圾收集器还有另一个技巧可以防止失控的内存增长。如果堆内存开始增长过快,垃圾收集器将对任何分配新内存的请求收“税”。请求新堆分配的 Goroutines 将必须先协助垃圾收集,然后才能获得它们所要求的东西。
这种“辅助”系统增加了分配的延迟,因此有助于系统抗压(backpressure)。这非常重要,因为它解决了并发垃圾收集器可能引起的问题。在并发垃圾收集器中,内存分配在垃圾收集运行时仍进行内存分配。如果程序分配内存的速度快于垃圾收集器释放它的速度,那么内存增长将是无限的。通过减慢(背压)新内存的净分配来帮助解决这个问题。
我们可以跟踪 gcAssistAlloc1[14] 以查看此过程的运行情况。gcAssistAlloc1 接受一个名为 scanWork 的参数,它是请求的辅助工作量。
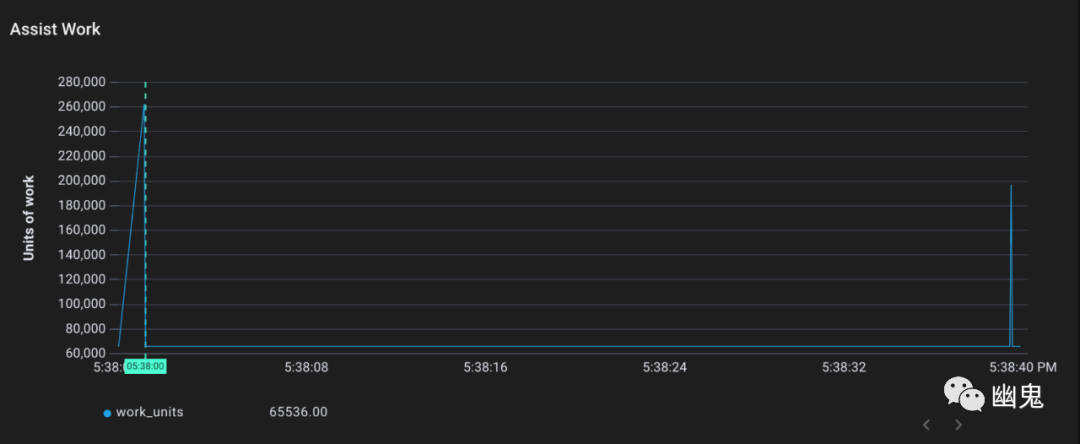
可以看到,gcAssistAlloc1 就是 mark 和 sweep 工作的来源。它收到了完成大约 30 万个工作单元的请求。在之前的标记阶段图中,gcDrainN 在相同的时间段完成了大约 30 万个标记工作单元(只是稍微分散一点)。
4、总结
还有很多关于 Go 中的内存分配和垃圾收集的知识!这里有一些其他的资源可以查看:
Go 对小对象的特殊清除[15] 通过逃逸分析[16]查看对象是分配在堆还是栈 sync.Pool[17],一种并发数据结构,通过池的方式共享对象来减少分配[18]
就像我们在本文例子中所做的那样,创建 uprobes 通常最好在更高级别的 BPF 框架中完成。对于这篇文章,我使用了 Pixie 的 Dynamic Go 日志记录[19]功能(仍处于 alpha 阶段)。bpftrace[20] 是另一个创建 uprobes 的好工具。
检查 Go 垃圾收集器行为的另一个不错的选择是 gc 跟踪器。只需在你启动程序时传入 GODEBUG=gctrace=1。这会输出有关垃圾收集器正在做什么的各种有用信息。
原文链接:https://blog.px.dev/go-garbage-collector/。
参考资料
这里: https://github.com/pixie-io/pixie-demos/tree/main/go-garbage-collector
[2]uprobes: https://jvns.ca/blog/2017/07/05/linux-tracing-systems/#uprobes
[3]GC: https://github.com/golang/go/blob/go1.16/src/runtime/mgc.go#L1126
[4]gcWaitOnMark: https://github.com/golang/go/blob/go1.16/src/runtime/mgc.go#L1201
[5]gcSweep: https://github.com/golang/go/blob/go1.16/src/runtime/mgc.go#L2170
[6]代码: https://github.com/pixie-io/pixie-demos/tree/main/go-garbage-collector
[7]从源代码: https://github.com/golang/go/blob/go1.16/src/runtime/mgc.go#L1126
[8]allocSpan: https://github.com/golang/go/blob/go1.16/src/runtime/mheap.go#L1124
[9]gcDrainN: https://github.com/golang/go/blob/go1.16/src/runtime/mgcmark.go#L1095
[10]sweepone: https://github.com/golang/go/blob/go1.16/src/runtime/mgcsweep.go#L188
[11]stopTheWorldWithSema: https://github.com/golang/go/blob/go1.16/src/runtime/proc.go#L1073
[12]startTheWorldWithSema: https://github.com/golang/go/blob/go1.16/src/runtime/proc.go#L1151
[13]pacer: https://go.googlesource.com/proposal/+/a216b56e743c5b6b300b3ef1673ee62684b5b63b/design/44167-gc-pacer-redesign.md
[14]gcAssistAlloc1: https://github.com/golang/go/blob/go1.16/src/runtime/mgcmark.go#L504
[15]特殊清除: https://github.com/golang/go/blob/master/src/runtime/mgc.go#L93
[16]逃逸分析: https://medium.com/a-journey-with-go/go-introduction-to-the-escape-analysis-f7610174e890
[17]sync.Pool: https://pkg.go.dev/sync#Pool
[18]减少分配: https://medium.com/swlh/go-the-idea-behind-sync-pool-32da5089df72
[19]Dynamic Go 日志记录: https://docs.px.dev/tutorials/custom-data/dynamic-go-logging/
[20]bpftrace: https://github.com/iovisor/bpftrace
推荐阅读