Flink Forward Asia 2020 -- Keynote 总结

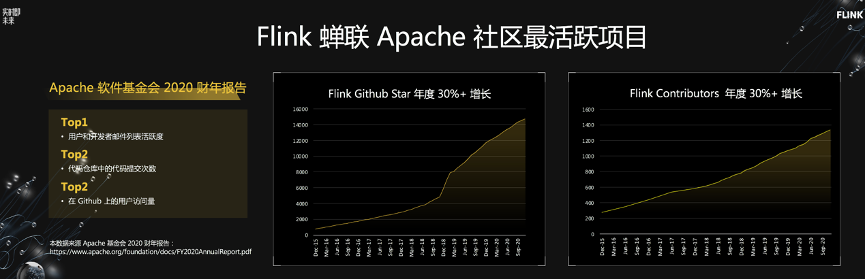

主会场议题


Flink as a Unified Engine
–– Now and Next



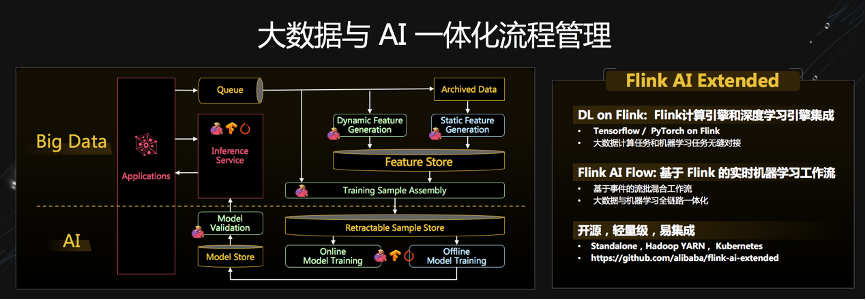
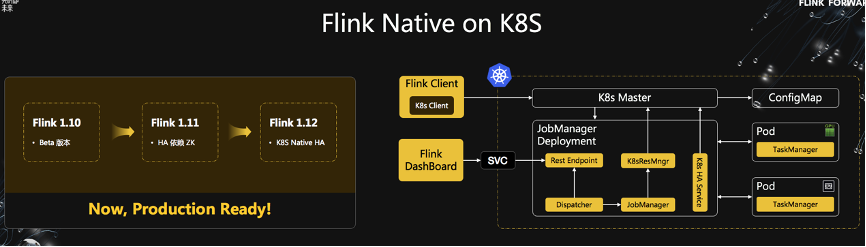
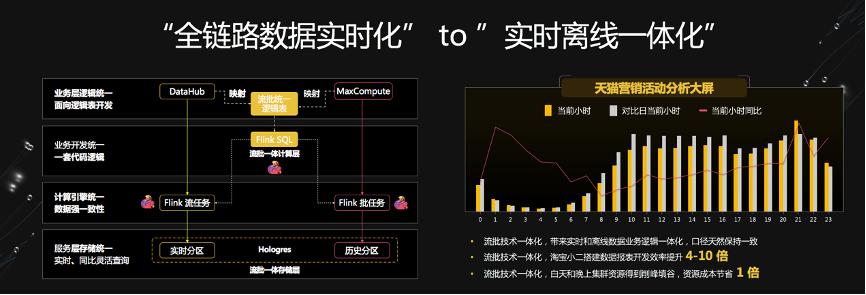
Flink 助力美团数仓增量生产

Apache Flink 在快手的过去、现在和未来

Stream is the New File
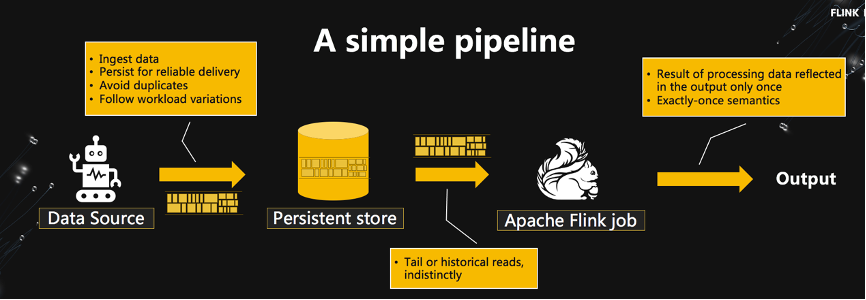
总结和感想

评论
 下载APP
下载APP
主会场议题
Flink as a Unified Engine
–– Now and Next
Flink 助力美团数仓增量生产
Apache Flink 在快手的过去、现在和未来
Stream is the New File
总结和感想