
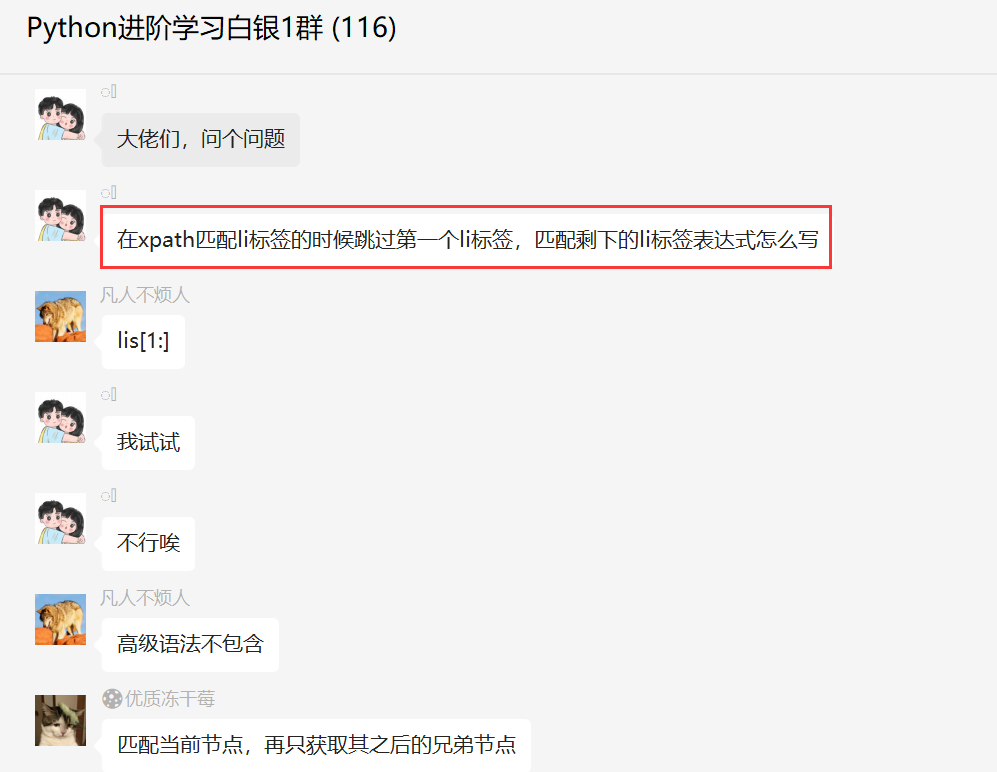
在xpath匹配li标签的时候跳过第一个li标签,匹配剩下的li标签表达式怎么写?
回复“资源”即可获赠Python学习资料
大家好,我是皮皮。
一、前言
前几天在Python白银交流群【꯭】问了一道Python选择器的问题,如下图所示。
二、实现过程
这个问题其实在爬虫中还是很常见的,尤其是遇到那种表格的时候,往往第一个表头是需要跳过的,这时候,我们就需要使用xpath高级语法了。
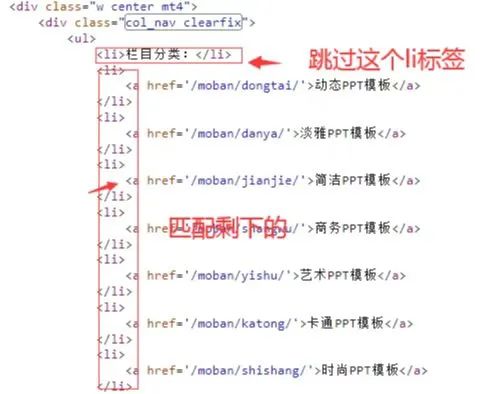
这里给出一个可行的代码,大家后面遇到了,可以对应的修改下,事半功倍,思路是先筛选再匹配,代码如下所示:
li.xpath('/li[position() > 1 and position() < 5]')
上面这个代码的意思是跳过第一个li标签,然后取到第五个li标签为止。
当然了,方法还是有挺多的,两种思路都可行。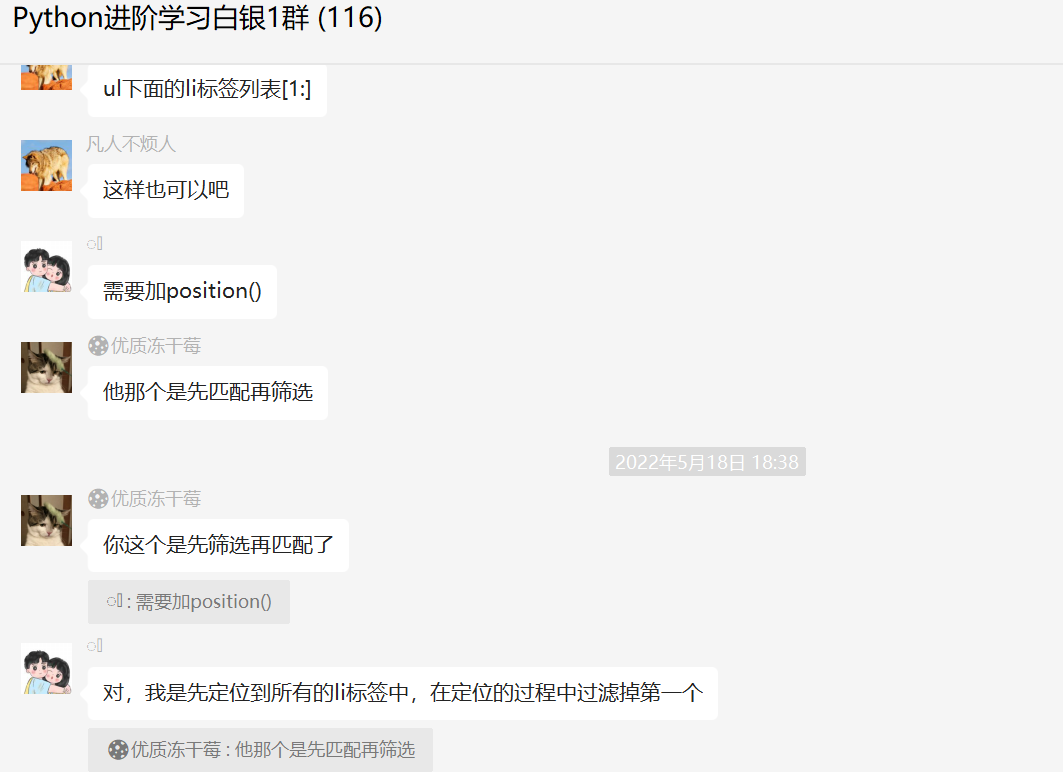
三、总结
大家好,我是皮皮。这篇文章主要盘点了一道使用xpath提取目标信息的问题,文中针对该问题给出了具体的解析,帮助粉丝顺利解决了问题。
最后感谢粉丝【꯭】提问,感谢【月神】、【凡人不烦人】给出的解析,感谢【dcpeng】、【艾希·觉罗】等人参与学习交流。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
评论