
Hudi 版本 | Flink Hudi 0.10.0 发布,多项重要更新,稳定性大幅提升
▼ 关注「Apache Flink」,获取更多技术干货 ▼
前言
随着云数仓技术的不断成熟,数据湖俨然已成为当下最热门的技术之一,而 Apache Hudi 是当下最具竞争力的数据湖格式之一:
拥有最活跃的开源社区之一,周活跃 PR 一直维持在 50+ 水平; 拥有最活跃的国内用户群之一,目前的 Apache Hudi 钉钉群用户已超过 2200+,国内各大厂商都已经布局 Apache Hudi 生态。
类 LSM 的 file format 布局很好的适配了近实时更新场景,解决了超大数据集更新的痛点; Hudi 的事物层语义在目前的湖存储中是极其成熟和丰富的,基本所有的数据治理都可以自动化完成:compaction、rollback、cleaning、clustering。
Flink On Hudi
版本 Highlights
0.10.0 版本经过社区用户的千锤百炼,贡献了多项重要的 fix,更有核心读写能力的大幅增强,解锁了多个新场景,Flink On Hudi 侧的更新重点梳理如下:
Bug 修复
修复对象存储上极端 case 流读数据丢失的问题 [HUDI-2548]; 修复全量+增量同步偶发的数据重复 [HUDI-2686]; 修复 changelog 模式下无法正确处理 DELETE 消息 [HUDI-2798]; 修复在线压缩的内存泄漏问题 [HUDI-2715]。
支持增量读取; 支持 batch 更新; 新增 Append 模式写入,同时支持小文件合并; 支持 metadata table。
写入性能大幅提升:优化写入内存、优化了小文件策略(更加均衡,无碎片文件)、优化了 write task 和 coordinator 的交互; 流读语义增强:新增参数
earliest,提升从最早消费性能、支持参数跳过压缩读取,解决读取重复问题;在线压缩策略增强:新增 eager failover + rollback,压缩顺序改为从最早开始; 优化事件顺序语义:支持处理序,支持事件序自动推导。
小文件优化
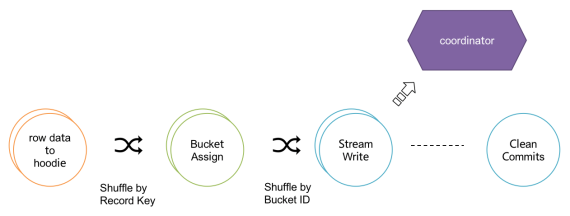
row data to hoodie:负责将 table 的数据结构转成 HoodieRecord; bucket assigner:负责新的文件 bucket (file group) 分配; write task:负责将数据写入文件存储; coordinator:负责写 trasaction 的发起和 commit; cleaner:负责数据清理。
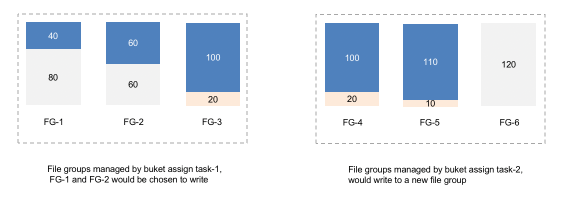
全局文件视图
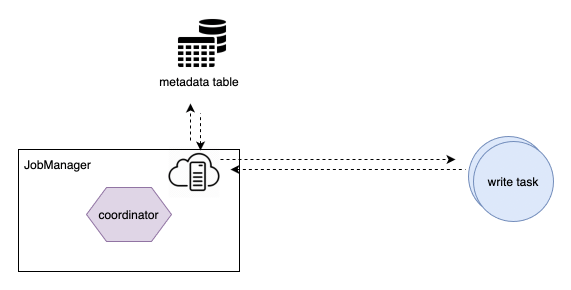
流读能力增强
0.10.0 版本新增了从最早消费数据的参数,通过指定 read.start-commit 为 earliest 即可流读全量 + 增量数据,值得一提的是,当从 earliest 开始消费时,第一次的 file split 抓取会走直接扫描文件视图的方式,在开启 metadata table 功能后,文件的扫描效率会大幅度提升;之后的增量读取部分会扫描增量的 metadata,以便快速轻量地获取增量的文件讯息。
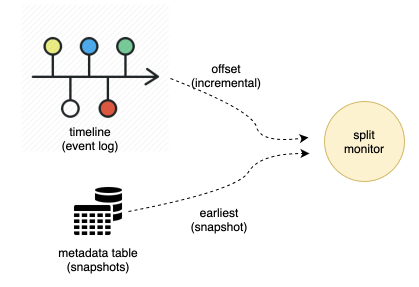
新增处理顺序
write.precombine.field 字段来判断版本新旧,如下图中标注蓝色方块的消息为合并后被选中的消息。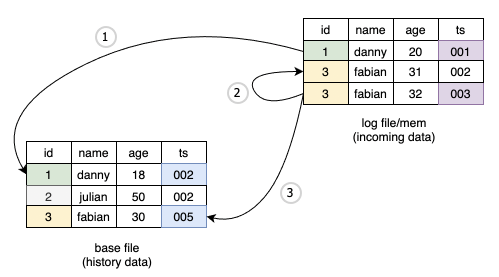
0.10.0 版本可以不指定 write.precombine.field 字段,此时使用处理顺序:即后来的消息比较新,对应上图紫色部分被选中的消息。
Metadata Table
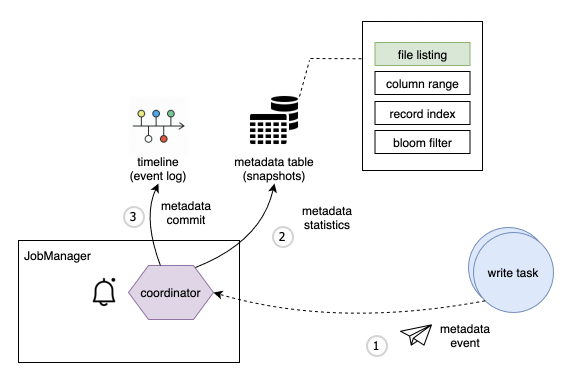
总结和展望
Flink On Hudi 是 Apache Hudi 社区接下来两个大版本主要的发力方向,在未来规划中,主要有三点:
完善端到端 streaming ETL 场景 支持原生的 change log、支持维表查询、支持更轻量的去重场景; Streaming 查询优化 record-level 索引,二级索引,独立的文件索引; Batch 查询优化 z-ordering、data skipping。
Flink+Hudi 构架湖仓一体化解决方案 顺丰科技 Hudi on Flink 实时数仓实践 37 手游基于 Flink CDC + Hudi 湖仓一体方案实践 Apache Hudi 在 B 站构建实时数据湖的实践 使用 Flink Hudi 构建流式数据湖

 戳我,查看更多技术干货~
戳我,查看更多技术干货~
评论