Java 对象头信息分析和三种锁的性能对比
你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
编辑:业余草
推荐:https://www.xttblog.com/?p=5277
Java 头的信息分析
首先为什么我要去研究 java 的对象头呢?这里截取一张 hotspot 的源码当中的注释。

这张图换成可读的表格如下:

意思是 java 的对象头在对象的不同状态下会有不同的表现形式,主要有三种状态,无锁状态、加锁状态、gc 标记状态。
那么我可以理解 java 当中的取锁其实可以理解是给对象上锁,也就是改变对象头的状态,如果上锁成功则进入同步代码块。
但是 java 当中的锁有分为很多种,从上图可以看出大体分为偏向锁、轻量锁、重量锁三种锁状态。
这三种锁的效率 完全不同、关于效率的分析会在下文分析,我们只有合理的设计代码,才能合理的利用锁、那么这三种锁的原理是什么? 所以我们需要先研究这个对象头。
java对象的布局以及对象头的布局
使用 JOL 来分析 java 的对象布局,添加依赖。
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.8</version>
</dependency>
测试类:
public class JOLExample1 {
static B b = new B();
public static void main(String [] args) {
//jvm的信息
out.println(VM.current().details());
out.println(ClassLayout.parseInstance(b).toPrintable());
}
}
看下结果:
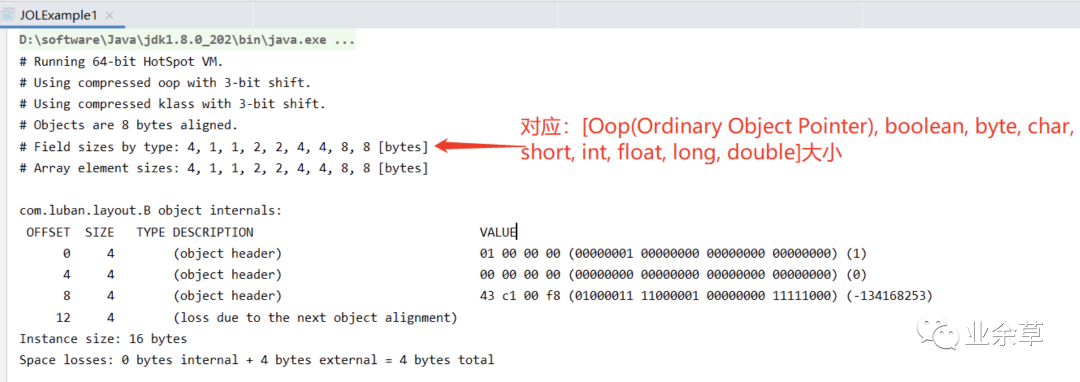
分析结果 1:整个对象一共 16B,其中对象头(Object header)12B,还有 4B 是对齐的字节(因为在 64 位虚拟机上对象的大小必 须是 8 的倍数)。
由于这个对象里面没有任何字段,故而对象的实例数据为 0B?
两个问题:
1、什么叫做对象的实例数据呢?
2、那么对象头里面的 12B 到底存的是什么呢?
首先要明白什么对象的实例数据很简单,我们可以在 B 当中添加一个 boolean 的字段,大家都知道 boolean 字段占 1B,然后再看结果。
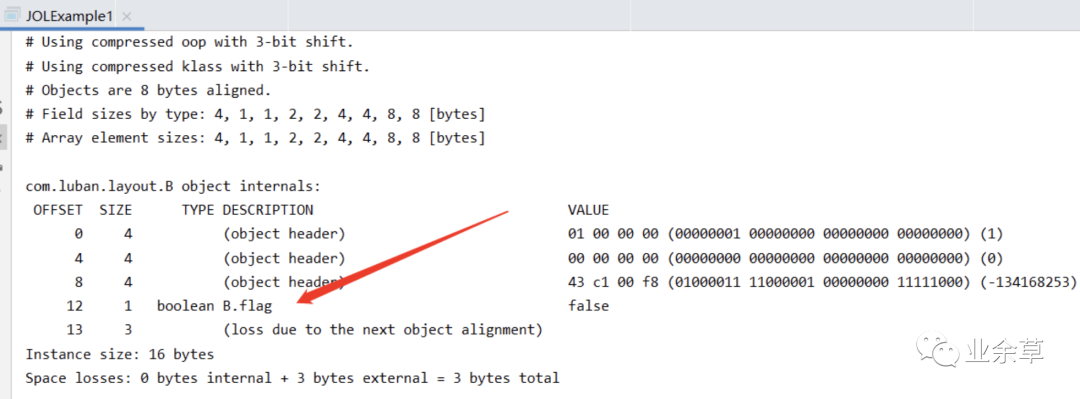
整个对象的大小还是没有改变一共 16B,其中对象头(Object header)12B, boolean 字段 flag(对象的实例数据)占 1B、剩下的 3B 就是对齐字节。
由此我们可以认为一个对象的布局大体分为三个部分分别是:对象头(Object header)、 对象的实例数据和字节对齐。
接下来讨论第二个问题,对象头为什么是 12B?这个 12B 当中分别存储的是什么呢?(不同位数的 VM 对象头的长度不一 样,这里指的是 64bit 的 vm)。
首先引用 openjdk 文档当中对对象头的解释:

上述引用中提到一个 java 对象头包含了 2 个 word,并且好包含了堆对象的布局、类型、GC 状态、同步状态和标识哈希码,具体怎么包含的呢?又是哪两个 word呢?

mark word 为第一个 word 根据文档可以知他里面包含了锁的信息,hashcode,gc 信息等等,第二个 word 是什么 呢?

klass word 为对象头的第二个 word 主要指向对象的元数据。

假设我们理解一个对象头主要上图两部分组成(数组对象除外,数组对象的对象头还包含一个数组长度)。
那么 一个 java 的对象头多大呢?我们从 JVM 的源码注释中得知到一个 mark word 一个是 64bit,那么 klass 的长度是多少呢?
所以我们需要想办法来获得 java 对象头的详细信息,验证一下他的大小,验证一下里面包含的信息是否正确。
根据上述利用 JOL 打印的对象头信息可以知道一个对象头是 12B,其中 8B 是 mark word 那么剩下的 4B 就是 klass word 了,和锁相关的就是 mark word 了。
那么接下来重点分析 mark word 里面信息 在无锁的情况下 markword 当中的前 56bit 存的是对象的 hashcode,那么来验证一下
先上代码:手动计算 HashCode。
public class HashUtil {
public static void countHash(Object object) throws NoSuchFieldException, IllegalAccessException {
// 手动计算HashCode
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe unsafe = (Unsafe) field.get(null);
long hashCode = 0;
for (long index = 7; index > 0; index--) {
// 取Mark Word中的每一个Byte进行计算
hashCode |= (unsafe.getByte(object, index) & 0xFF) << ((index - 1) * 8);
}
String code = Long.toHexString(hashCode);
System.out.println("util-----------0x"+code);
}
}
public class JOLExample2 {
public static void main(String[] args) throws Exception {
B b = new B();
out.println("befor hash");
//没有计算HASHCODE之前的对象头
out.println(ClassLayout.parseInstance(b).toPrintable());
//JVM 计算的hashcode
out.println("jvm------------0x"+Integer.toHexString(b.hashCode()));
HashUtil.countHash(b);
//当计算完hashcode之后,我们可以查看对象头的信息变化
out.println("after hash");
out.println(ClassLayout.parseInstance(b).toPrintable());
}
}
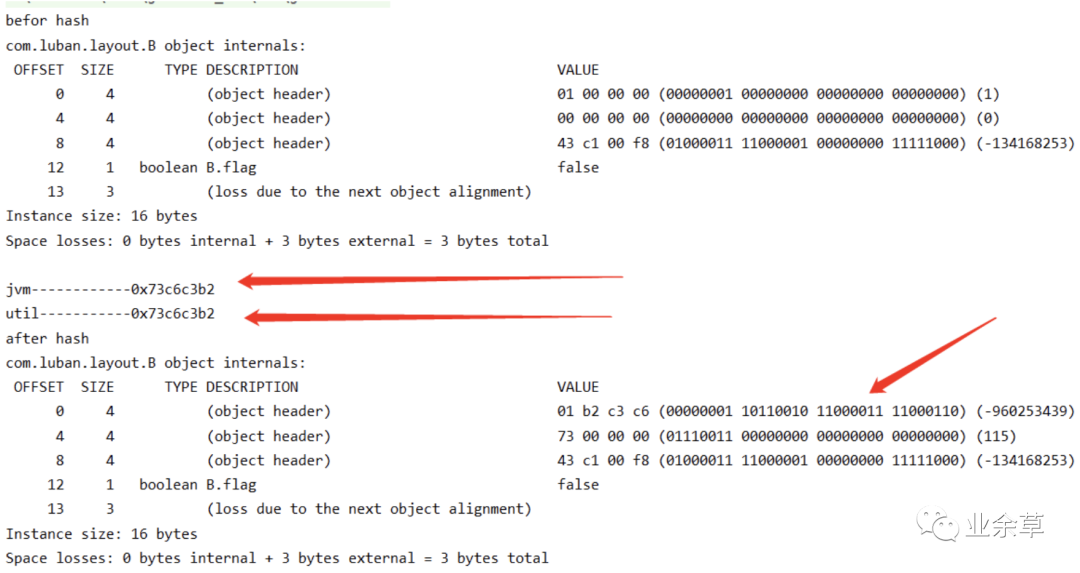
分析结果 3:
上面没有进行 hashcode 之前的对象头信息,可以看到的 56bit 没有值,打印完 hashcode 之后就有值了,为什么是 1-7B,不是 0-6B 呢?因为是「小端存储」。
其中两行是我们通过 hashcode 方法打印的结果,第一行是我根据 1-7B 的信息计算出来的 hashcode,所以可以确定 java 对象头当中的 mark work 里面的后七个字节存储的是 hashcode 信息。
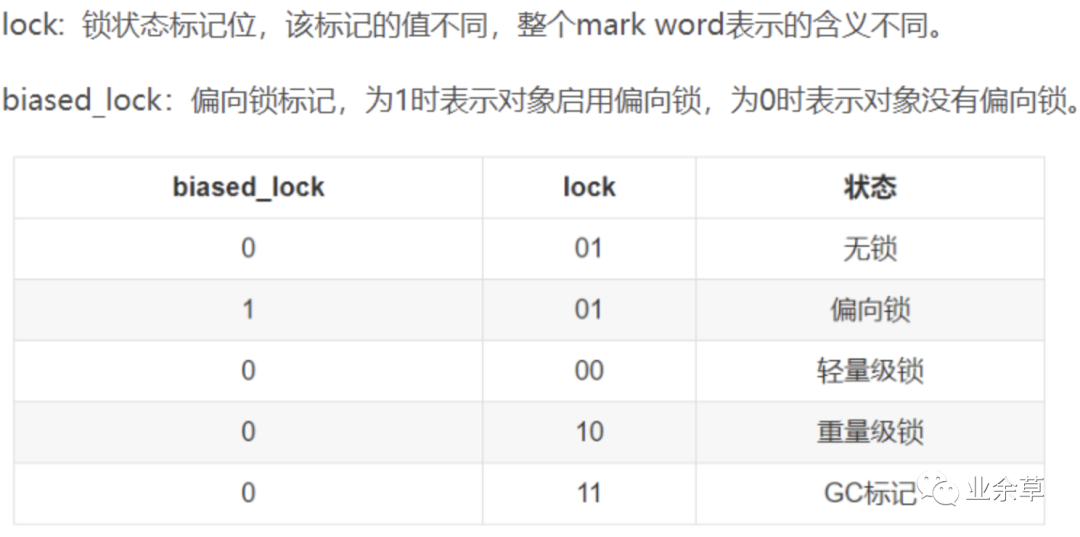
那么第一个字节当中的八位分别存的就是分带年龄、偏向锁信息,和对象状态,这个 8bit 分别表示的信息如下图(其实上图也有信息),这个图会随着对象状态改变而改变,下图是无锁状态下。
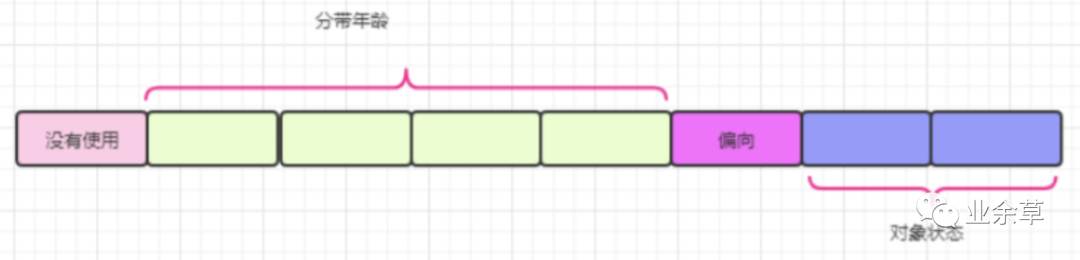
关于对象状态一共分为五种状态,分别是无锁、偏向锁、轻量锁、重量锁、GC 标记。
那么 2bit,如何能表示五种状 态(2bit 最多只能表示 4 中状态分别是:00,01,10,11)。
jvm 做的比较好的是把偏向锁和无锁状态表示为同一个状态,然 后根据图中偏向锁的标识再去标识是无锁还是偏向锁状态。
什么意思呢?写个代码分析一下,「在写代码之前我们先记得 无锁状态下的信息00000001」,然后写一个偏向锁的例子看看结果。
public static void main(String[] args) throws Exception {
//-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
B b = new B();
out.println("befor lock");
out.println(ClassLayout.parseInstance(b).toPrintable());
synchronized (b){
out.println("lock ing");
out.println(ClassLayout.parseInstance(b).toPrintable());
}
out.println("after lock");
out.println(ClassLayout.parseInstance(b).toPrintable());
}
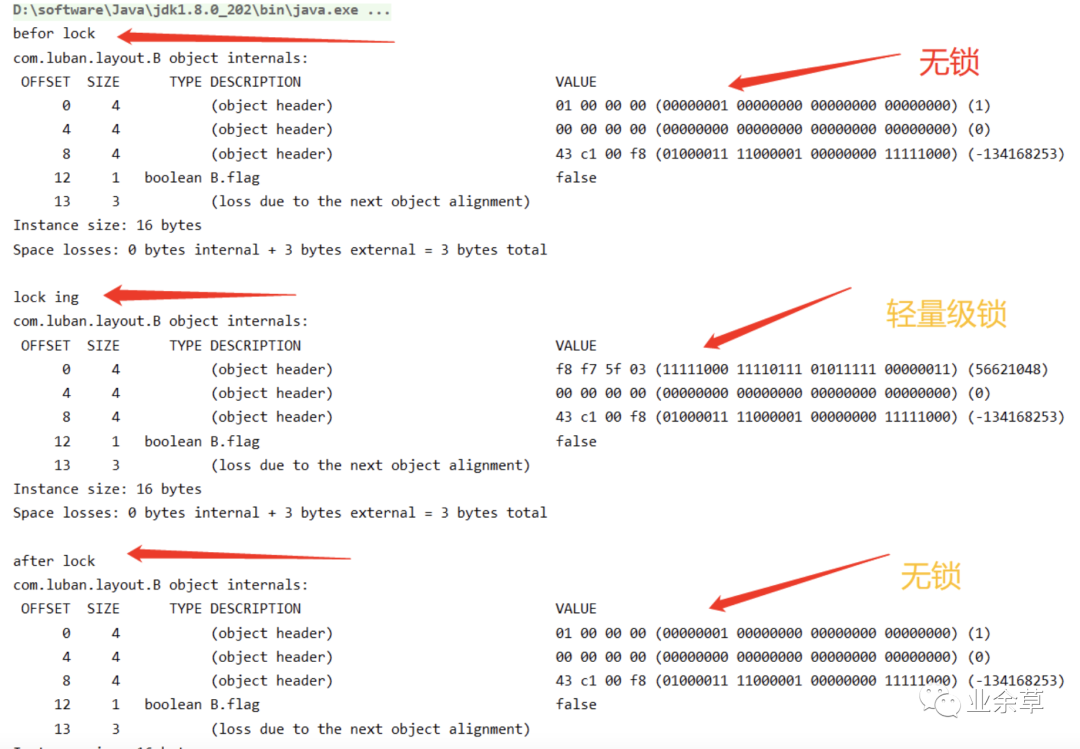
上面这个程序只有一个线程去调用 sync 方法,故而讲道理应该是偏向锁,但是此时却是轻量级锁。
而且你会发现最后输出的结果(第一个字节)依 然是 00000001 和无锁的时候一模一样,其实这是因为虚拟机在启动的时候对于偏向锁有延迟。
比如把上述代码当中加上睡眠 5 秒的代码,结果就会不一样了。
public static void main(String[] args) throws Exception {
//-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
Thread.sleep(5000);
B b = new B();
out.println("befor lock");
out.println(ClassLayout.parseInstance(b).toPrintable());
synchronized (b){
out.println("lock ing");
out.println(ClassLayout.parseInstance(b).toPrintable());
}
out.println("after lock");
out.println(ClassLayout.parseInstance(b).toPrintable());
}
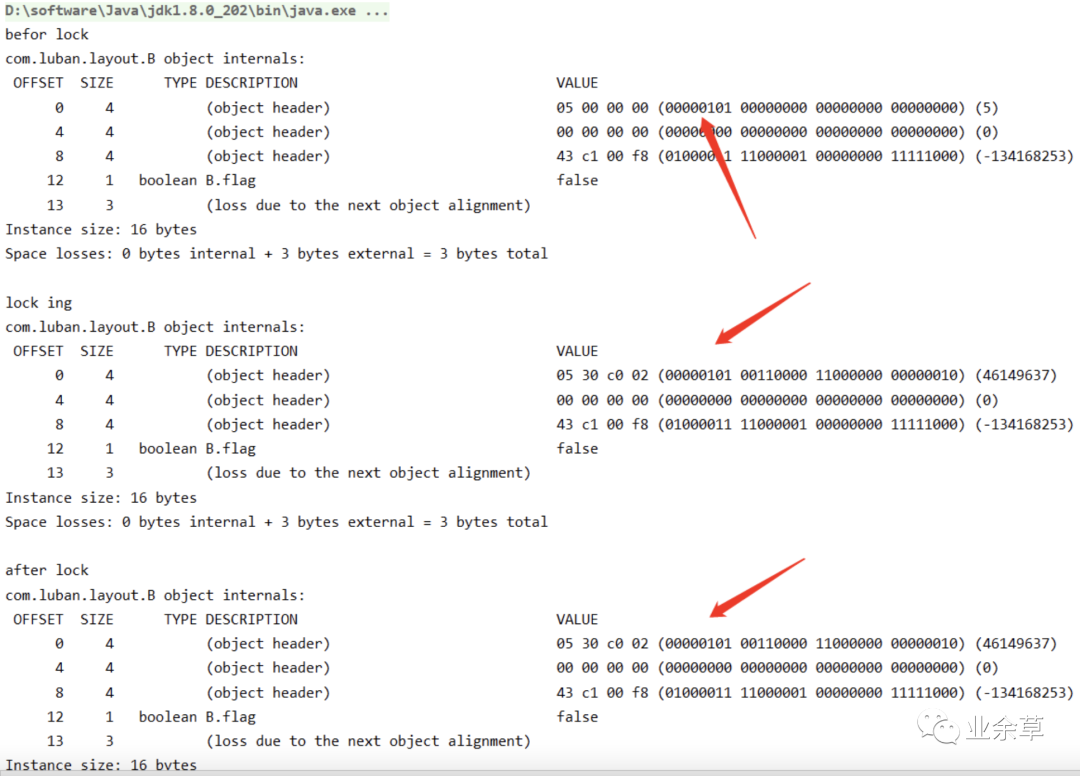
结果变成 00000101。当然为了方便测试我们也可以直接通过 JVM 的参数来禁用延迟。
-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
结果是和睡眠 5 秒一样的。
想想为什么偏向锁会延迟?因为启动程序的时候,jvm 会有很多操作,包括 gc 等等,jvm 刚运行时存在大量的同步方法,很多都不是偏向锁。
「而偏向锁升级为轻/重量级锁的很费时间和资源,因此 jvm 会延迟 4 秒左右再开启偏向锁。」
「那么为什么同步之前就是偏向锁呢?我猜想是 jvm 的原因,目前还不清楚。」
需要注意的 after lock,退出同步后依然保持了偏向信息。
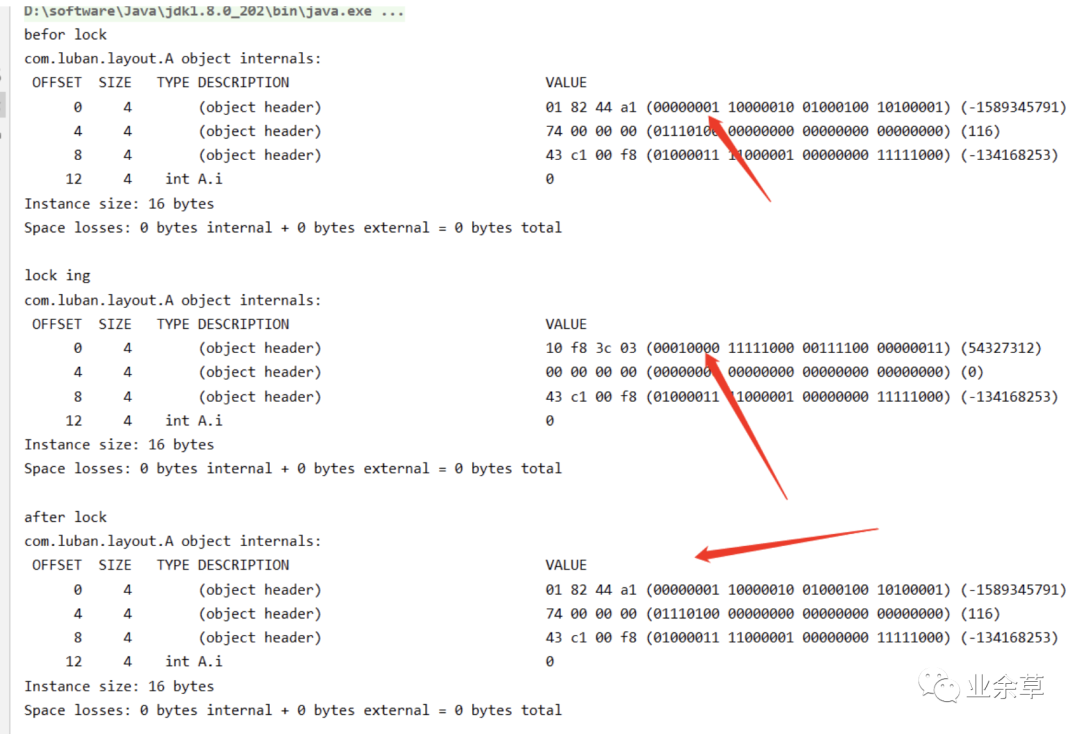
然后看下轻量级锁的对象头。
static A a;
public static void main(String[] args) throws Exception {
a = new A();
out.println("befre lock");
out.println(ClassLayout.parseInstance(a).toPrintable());
synchronized (a){
out.println("lock ing");
out.println(ClassLayout.parseInstance(a).toPrintable());
}
out.println("after lock");
out.println(ClassLayout.parseInstance(a).toPrintable());
}
看结果:
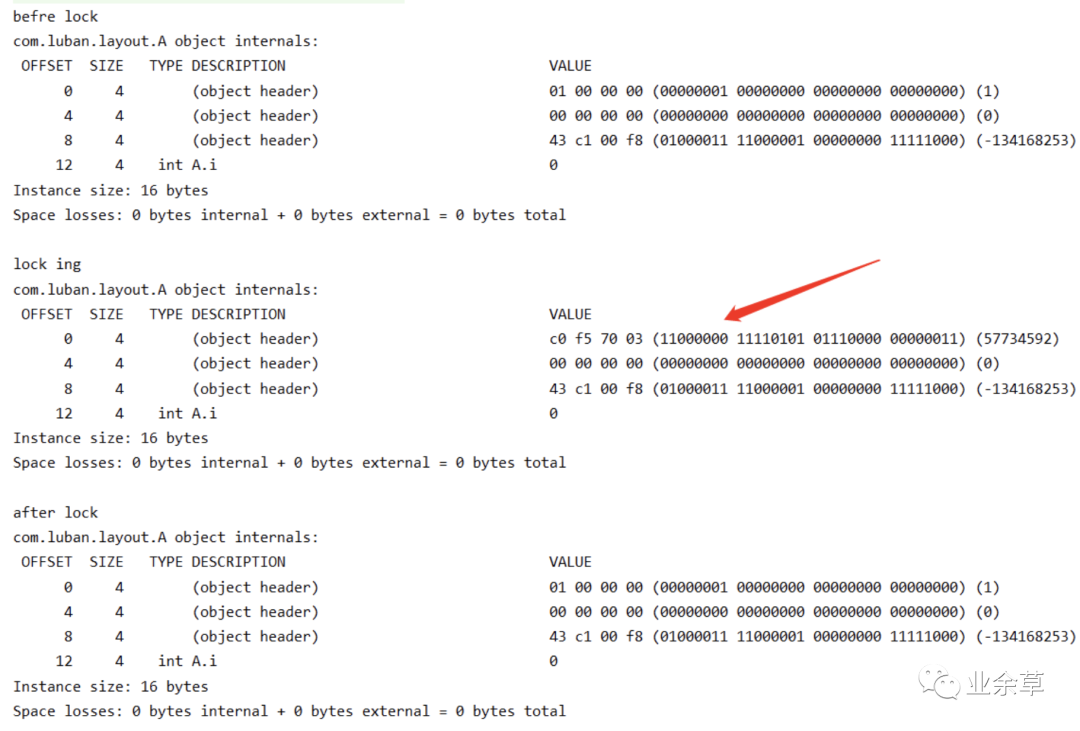
关于重量锁首先看对象头。
static A a;
public static void main(String[] args) throws Exception {
//Thread.sleep(5000);
a = new A();
out.println("befre lock");
out.println(ClassLayout.parseInstance(a).toPrintable());//无锁
Thread t1= new Thread(){
public void run() {
synchronized (a){
try {
Thread.sleep(5000);
System.out.println("t1 release");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
t1.start();
Thread.sleep(1000);
out.println("t1 lock ing");
out.println(ClassLayout.parseInstance(a).toPrintable());//轻量锁
sync();
out.println("after lock");
out.println(ClassLayout.parseInstance(a).toPrintable());//重量锁
System.gc();
out.println("after gc()");
out.println(ClassLayout.parseInstance(a).toPrintable());//无锁---gc
}
public static void sync() throws InterruptedException {
synchronized (a){
System.out.println("t1 main lock");
out.println(ClassLayout.parseInstance(a).toPrintable());//重量锁
}
}
看结果。
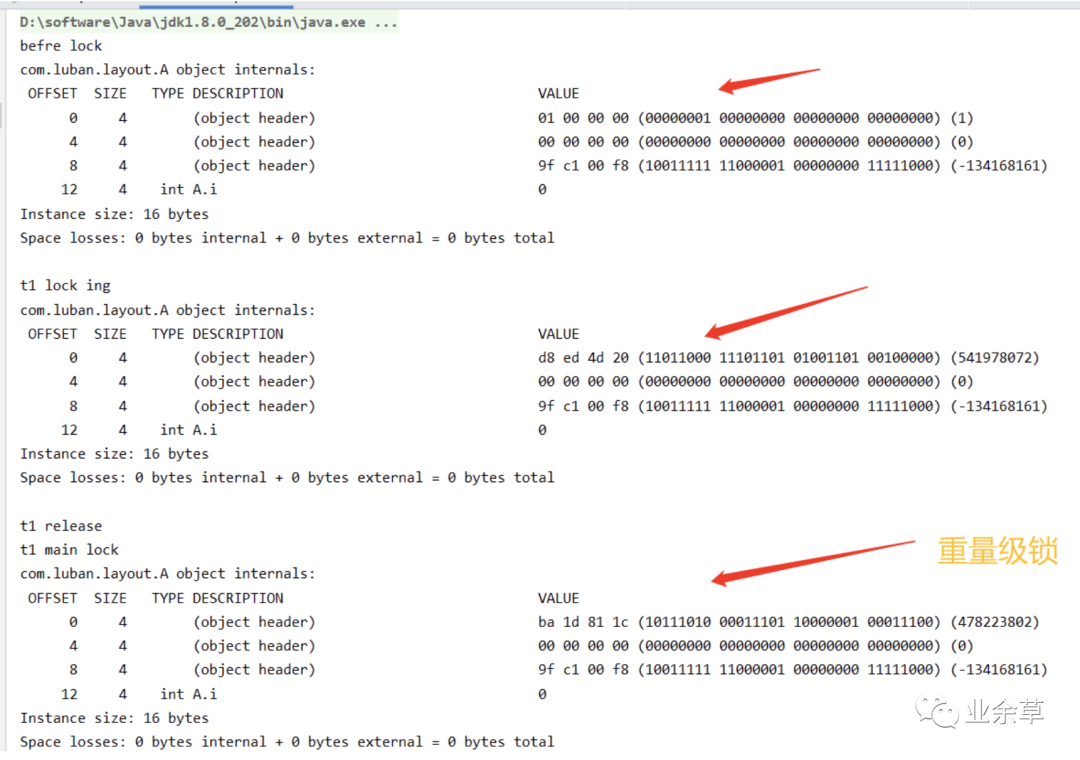
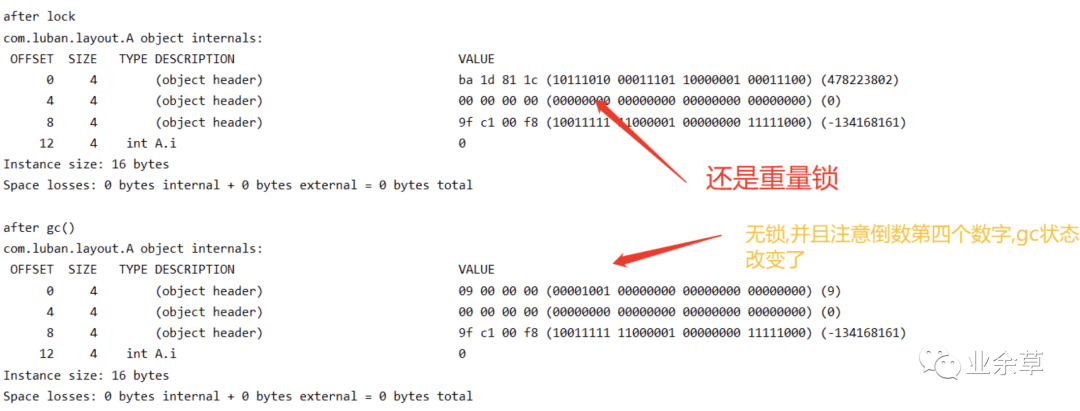
「由上述实验可总结下图:」
性能对比偏向锁和轻量级锁:
public class A {
int i=0;
public synchronized void parse(){
i++;
}
//JOLExample6.countDownLatch.countDown();
}
执行 1000000000L 次 ++ 操作。
public class JOLExample4 {
public static void main(String[] args) throws Exception {
A a = new A();
long start = System.currentTimeMillis();
//调用同步方法1000000000L 来计算1000000000L的++,对比偏向锁和轻量级锁的性能
//如果不出意外,结果灰常明显
for(int i=0;i<1000000000L;i++){
a.parse();
}
long end = System.currentTimeMillis();
System.out.println(String.format("%sms", end - start));
}
}
此时根据上面的测试可知是轻量级锁,看下结果。
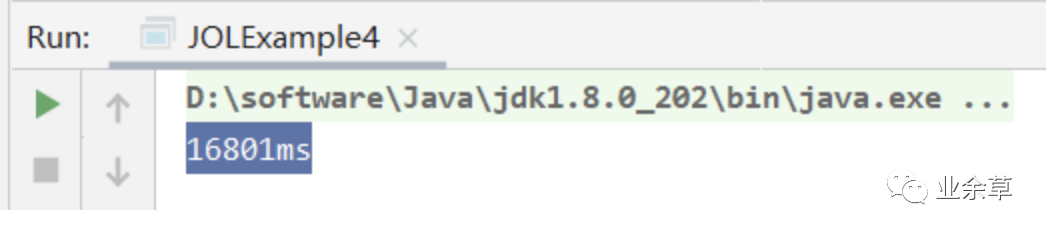
大概 16 秒。
然后我们让偏向锁启动无延时,在启动一次。
-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
再看下结果。
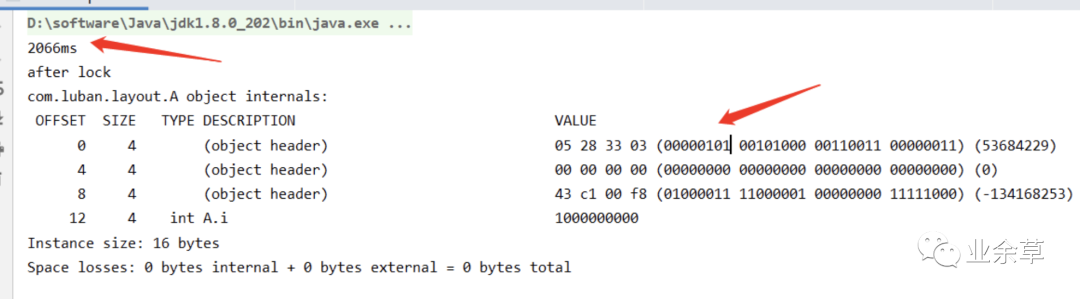
只需要 2 秒,速度提升了很多。
再看下重量级锁的时间。
static CountDownLatch countDownLatch = new CountDownLatch(1000000000);
public static void main(String[] args) throws Exception {
final A a = new A();
long start = System.currentTimeMillis();
//调用同步方法1000000000L 来计算1000000000L的++,对比偏向锁和轻量级锁的性能
//如果不出意外,结果灰常明显
for(int i=0;i<2;i++){
new Thread(){
@Override
public void run() {
while (countDownLatch.getCount() > 0) {
a.parse();
}
}
}.start();
}
countDownLatch.await();
long end = System.currentTimeMillis();
System.out.println(String.format("%sms", end - start));
}
看下结果,大概 31 秒。
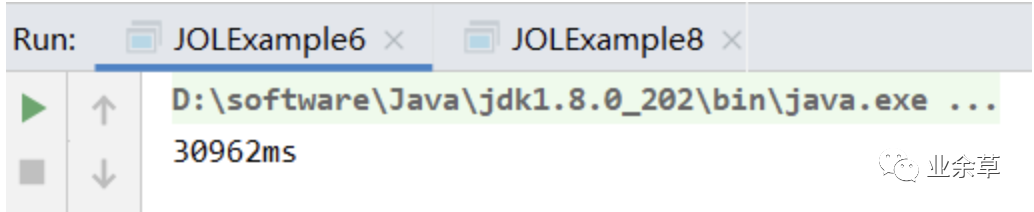
可以看出三种锁的消耗是差距很大的,这也是 1.5 以后 synchronized 优化的意义。
需要注意的是如果对象已经计算了 hashcode 就不能偏向了
static A a;
public static void main(String[] args) throws Exception {
Thread.sleep(5000);
a= new A();
a.hashCode();
out.println("befor lock");
out.println(ClassLayout.parseInstance(a).toPrintable());
synchronized (a){
out.println("lock ing");
out.println(ClassLayout.parseInstance(a).toPrintable());
}
out.println("after lock");
out.println(ClassLayout.parseInstance(a).toPrintable());
}
看下结果。