
BLIP-2 2022.01

论文时间:2023年1月
官方github:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
BLIP-2:在冻结图像encoders和LLMs辅助下,提升语言-图像预训练效果
1. 论文目的
背景:端对端的训练模式,使得视觉-语言预训练大模型的成本变得越来越高。
目的:提出一个通用高效的视觉-语言预训练框架,不用全参训练就可以提升效果
2. 背景知识
交叉注意力(cross attention,CA)
互信息(mutual information)
LM Loss / Prefix LM Loss
ViT / OPT / FlanT5
3. 模型方法 —— 两阶段训练、联合学习三个任务
BLIP-2,一个新的视觉-语言预训练方法,通过冻结单模态预训练模型来提升效果。为了实现跨模态交互,论文提出Query Transformer(Q-Former),并分为两个阶段进行预训练。
3.1 模型架构
如下图,Q-Former包括两个共享自注意力层的Transformer子模块,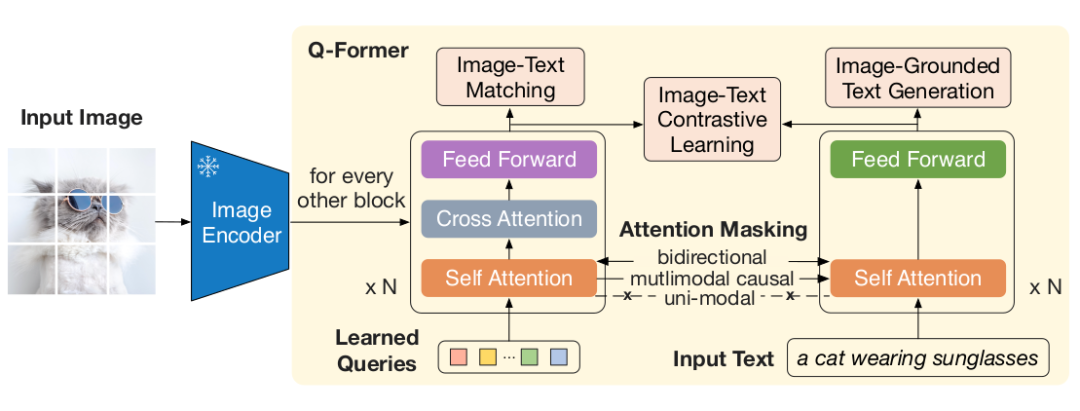
图像transformer模块,和冻结的图像编码器相互作用;其输入是一系列可学习的query embeddings,它们在自注意力层(SA)中相互作用;交叉注意力层(CA)用于将query embeddings和冻结图像编码器提取的特征进行相互作用。
文本transformer,可作为文本编码器和解码器;输入是文本embeddings,自注意力层和图像transformer模块共享,以此使得文本可以与queries相互作用。
从实验细节上看,Q-Former用预训练的 进行初始化,但是交叉注意力层的参数是随机初始化的。总的来说,Q-Former包含了188M的参数量。值得注意,queries是作为模型的参数,不是模型输入。 实验中使用32个queries,每个query有768维,和Q-Former隐含层维度一致,论文使用 来表示query表征的输出,它的维度远比冻结的图像编码器特征维度小(比如ViT-L/14的输出特征维度是 )。
3.2 一阶段预训练 —— 视觉-语言表征学习
通过带冻结参数的图像编码器进行视觉-语言表征学习(representation learning),旨在让queries学习如何提取出和文本最相关的视觉表征。受BLIP-1的启发,联合学习三个子任务,并共享同样的输入格式和模型参数,每个任务采用不同的注意力掩码策略用于控制queries和text之间的交互。
3.2.1 任务一:图像-文本匹配(Image-Text Matching,ITM)
目的:旨在学习图像和文本表征之间的细粒度对齐
本质:二元分类任务,即判断image-text pair是否positive(匹配)还是negative(不匹配)
掩码策略:双向自注意力掩码,所有queries和texts都可以互相关注到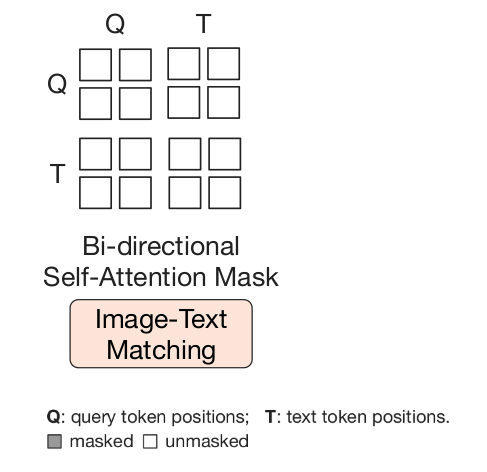
多模态特征矩阵:query embeddings
分类任务:将每个query嵌入输入到两分类线性分类器得到logit,然后对所有logits取平均
负采样技术:难负样本挖掘策略(hard negative mining)
3.2.2 任务二:基于图像的文本生成(Image-grounded Text Generation,ITG)
目的:给定输入图像作为条件,生成文本。
掩码策略:多模态因果自注意力掩码,类似在UniLM的掩码策略;细节如下图所示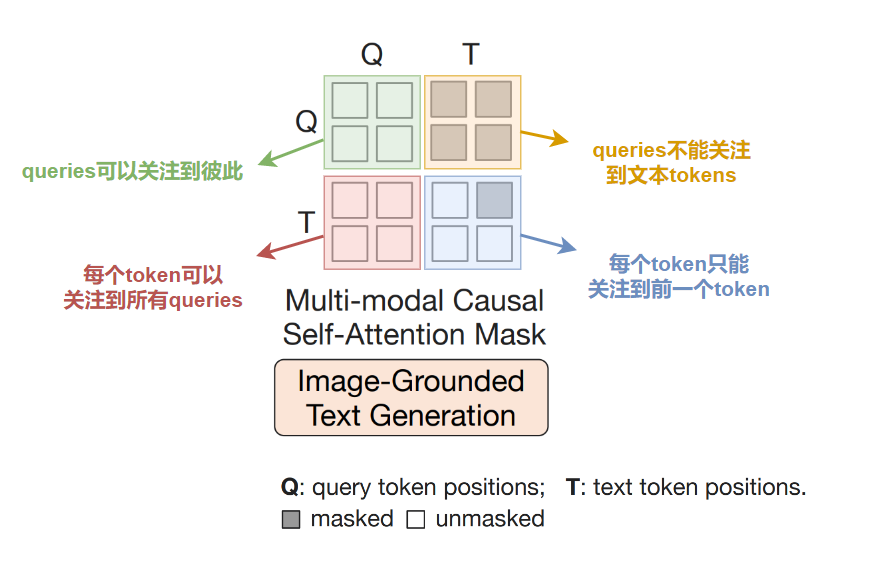 除此之外,论文还用一个新的标记 [DEC] 作为第一个文本token来替代原先的 [CLS] 标记,表示开始解码任务。
除此之外,论文还用一个新的标记 [DEC] 作为第一个文本token来替代原先的 [CLS] 标记,表示开始解码任务。
queries的作用:被强制用于抽取和文本相关的视觉特征,原因是Q-Former不允许文本tokens直接关注到(冻结参数的)图像编码器提取的视觉特征,所以需要先通过queries将生成文本所需的视觉信息提取出来,然后文本tokens才能通过自注意力层关注到必要的视觉信息。
3.2.3 任务三:图像-文本对比学习(Image-Text Contrastive Learning,ITC)
目的:学习如何对齐图像表征和文本表征,以最大化他们之间的互信息(mutual information)
方式:通过image-text pair的正负样本相似度之间的比较进行学习,具体如下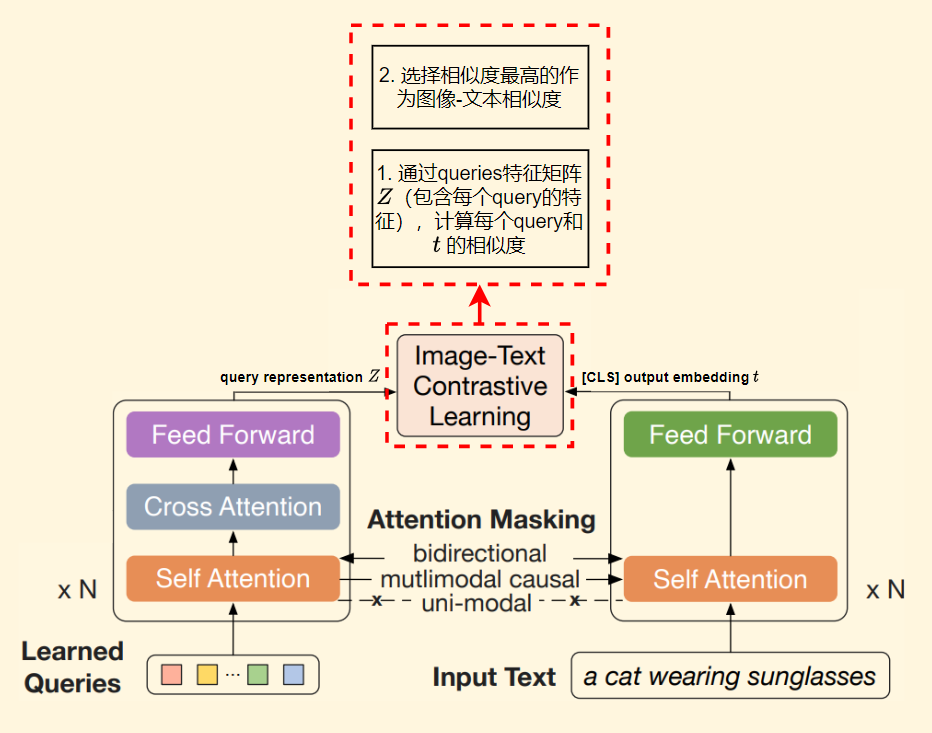
掩码策略:单模态自注意力掩码策略(如下),使得queries和文本之间都不能看到彼此,目的是防止信息泄露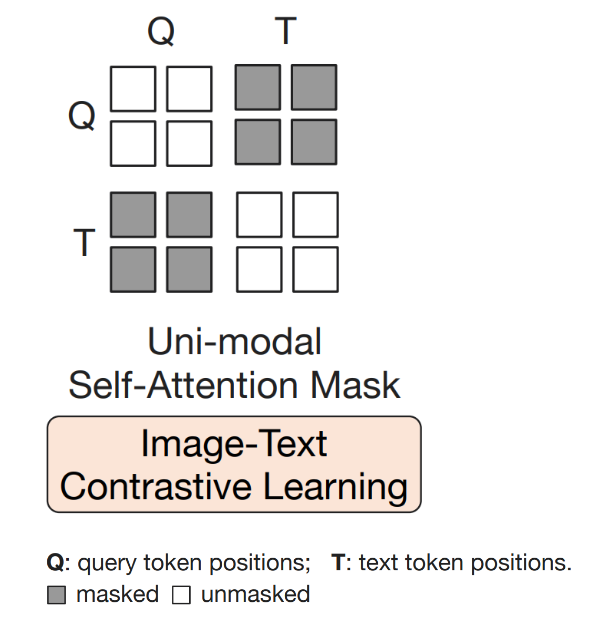
优势:由于使用了冻结的图像编码器,相比于端对端全参训练而言,每个GPU可以fit进更多的样本
3.3 二阶段预训练 —— 视觉-语言生成学习
在生成式预训练阶段,将第一阶段预训练后的Q-Former、冻结的图像编码器、冻结的LLM三者连接起来,如下图所示,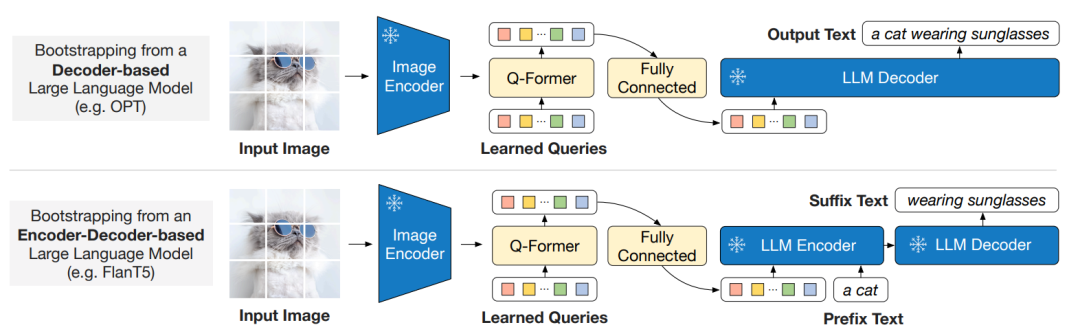 论文用全连接(FC)层将输出的query特征嵌入 映射到和文本嵌入的维度相同的特征,然后将该特征拼接到输入文本嵌入的前面,用作软视觉提示(soft visual prompts)来约束LLM的生成内容。
论文用全连接(FC)层将输出的query特征嵌入 映射到和文本嵌入的维度相同的特征,然后将该特征拼接到输入文本嵌入的前面,用作软视觉提示(soft visual prompts)来约束LLM的生成内容。
3.3.1 方法优势
因为在第一阶段预训练中,Q-Former已经获取了提取文本相关的视觉信息的能力,也就意味着它能摒弃不相关的视觉信息,提供更多实际有用的视觉信息给到LLM
减少了LLM去学习视觉-语言对齐的负担,也因此缓解了知识灾难性遗忘的问题
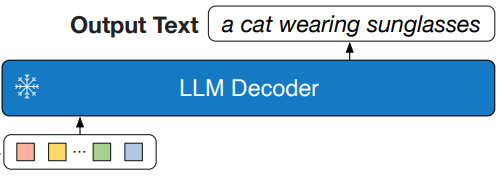
3.3.2 基于两种类型的LLM实验
基于decoder-only的LLMs,用LM损失进行预训练
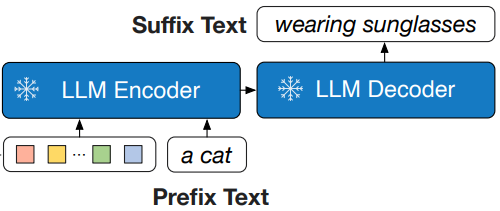
基于encode-decoder的LLMs,用Preifx LM损失进行预训练。如下图,将输入text分成两部分,text前缀部分(“a cat”)和视觉表征拼接一起作为LLM编码器的输入;text的后缀部分(“wearing sunglasses”)是生成目标,用于LLM的decoder部分的训练
4. 实验
4.1 预训练数据集与构建
总共129M张图像,包括:
COCO
Visual Genome
CC3M
CC12M
SBU
LAION400M(只用其中的115M张图像)
采用CapFilt方法(在BLIP 2022.02中有介绍),基于 标题生成模型,对网络图像生成10个候选标题,然后和原始标题一并进行排序,根据CLIP(ViT-L/14)模型计算的图像-文本相似度进行排序。实验中,排序前2的标题固定被用作训练,每一步迭代时,随机从这两个标题中选一个作为“y”。
4.2 图像编码器选型
两种SOTA的ViT模型:
CLIP的ViT-L/14(2021年)
EVA-CLIP的ViT-G/14(2022年)
4.3 LLM选型
OPT系列(2022年),作为decoder-only的LLMs
FlanT5系列(2022年),作为encoder-decoder的LLMs
4.4 预训练参数设置
迭代步数:第一阶段预训练250k;第二阶段预训练80k
batch大小:
第一阶段:对于ViT-L设置2320;对于ViT-G设置1680
第二阶段:对于OPT设置1920;对于FlanT5设置1520
精度:除了FlanT5用BFloat16精度之外,其他冻结的ViTs和LLMs参数都转成半精度(FP16);论文发现相比于32-bit模型,这种量化方式并没有导致性能退化
训练配置:单卡A100(40G),在配置最大模型(用上ViT-G和FlanT5-XXL)的前提下,第一阶段预训练不超过6天,第二阶段预训练不超过3天
优化器:AdamW(2017年),β1 = 0.9,β1 = 0.98,权重衰减率为0.05
学习率:余弦学习率衰减策略,峰值在1e-4,2k步的线性warm-up;第二阶段的最小学习率是5e-5
图像size:
图像增强:随机大小和随机宽高比的裁剪(random resized cropping,对应torchvision.transforms中的RandomResizedCrop方法)以及水平翻转

