
这是《吃透 MQ 系列》之 Kafka 的第 4 篇,错过前 3 篇的,通过下面的链接一睹为快:第 1 篇:扒开 Kafka 的神秘面纱
第 2 篇:Kafka 架构设计的任督二脉
第 3 篇:Kafka 存储选型的奥秘
第 3 篇文章我深入剖析了 Kafka 选用「日志文件」作为存储方案的来龙去脉以及背后「磁盘顺序写 + 稀疏索引」的精妙设计思路。但是,Kafka 能做到单机每秒几十万的吞吐量,它的性能优化手段绝不止这一点。Kafka 的高性能设计可以说是全方位的,从 Prodcuer 、到 Broker、再到 Consumer,Kafka 在掏空心思地优化每一个细节,最终才做到了这样的极致性能。这篇文章我想先带大家建立一个高性能设计的思维模式,然后再一探究竟 Kafka 的高性能设计方案,最终让大家更体系地掌握所有知识点,并理解它的设计哲学。我们暂且把 Kafka 抛在一边,先尝试理解下高性能设计的本质。有过高并发开发经验的同学,对于线程池、多级缓存、IO 多路复用、零拷贝等技术概念早就了然于胸,但是返璞归真,这些技术手段的本质到底是什么?这其实是一个系统性的问题,至少需要深入到操作系统层面,从 CPU 和存储入手,去了解底层的实现机制,然后再自底往上,一层一层去解密和贯穿起来。但是站在更高的视角来看,我认为:高性能设计其实万变不离其宗,一定是从「计算和 IO」这两个维度出发,去考虑可能的优化点。那「计算」维度的性能优化手段有哪些呢?无外乎这两种方式:
1、让更多的核来参与计算:比如用多线程代替单线程、用集群代替单机等。
2、减少计算量:比如用索引来取代全局扫描、用同步代替异步、通过限流来减少请求处理量、采用更高效的数据结构和算法等。
再看下「IO」维度的性能优化手段又有哪些? 可以通过 Linux 系统的 IO 栈图来辅助思考。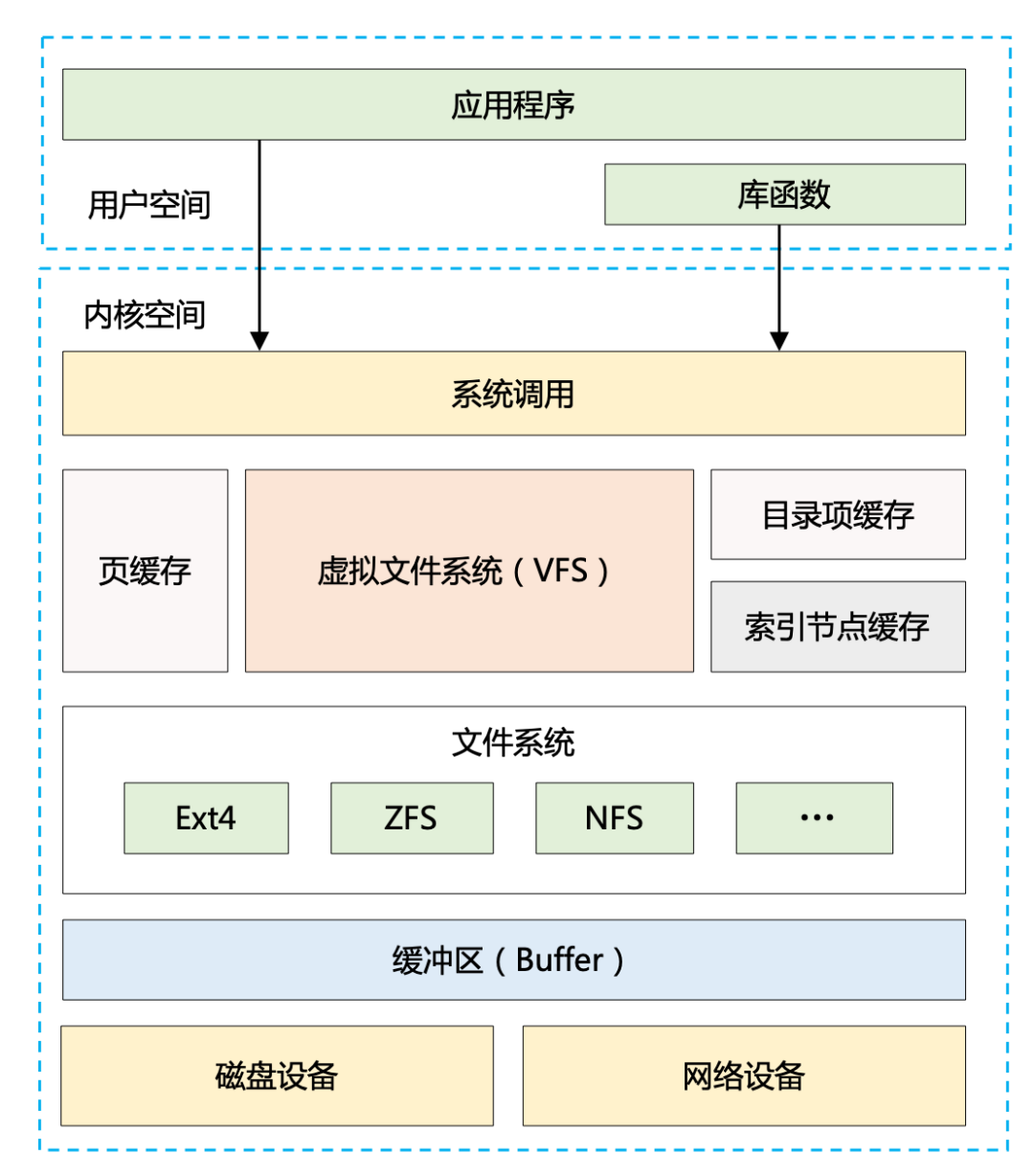
可以看到,整个 IO 体系结构是分层的,我们能够从应用程序、操作系统、磁盘等各个层次来考虑性能优化,而所有这些手段又几乎围绕以下两个方面展开:
1、加快 IO 速度:比如用磁盘顺序写代替随机写、用 NIO 代替 BIO、用性能更好的 SSD 代替机械硬盘等。
2、减少 IO 次数或者 IO 数据量:比如借助系统缓存或者外部缓存、通过零拷贝技术减少 IO 复制次数、批量读写、数据压缩等。
上面这些内容可以理解成高性能设计的「道」,当然绝不是几百字就可以说清楚的,我更多的是抛砖引玉,用另外一个视角来看高并发,给大家一个方向上的指引。当大家抓住了「计算和 IO」这两个最本质的东西,然后以这两点作为根,再去探究这两个维度分别有哪些性能优化手段?它们的原理又是什么样的?便能一层一层剥开高性能设计的神秘面纱,形成可靠的知识体系。这种分析方法可用来研究 Kafka,同样可以用来研究我们熟知的 Redis、ES 以及其他高性能的应用系统。有了高性能设计的思维模式后,我们再回到 Kafka 本身进行分析。前文提到过 Kafka 的性能优化手段非常丰富,至少有 10 条以上的精妙设计,虽然我们可以从计算和 IO 两个维度去联想这些手段,但是要完整地记住它们,似乎也不是件容易的事。这样就引出了另外一个话题:我们应该选用一条什么样的脉络,去串联这些优化手段呢?之前的文章做过分析:不管 Kafka 、RocketMQ 还是其他消息队列,其本质都是「一发一存一消费」。我们完全可以顺着这条主线去做结构化梳理。基于这个思路,便形成了下面这张 Kafka 高性能设计的全景图,我按照生产消息、存储消息、消费消息 3 个模块,将 Kafka 最具代表性的 12 条性能优化手段做了归类。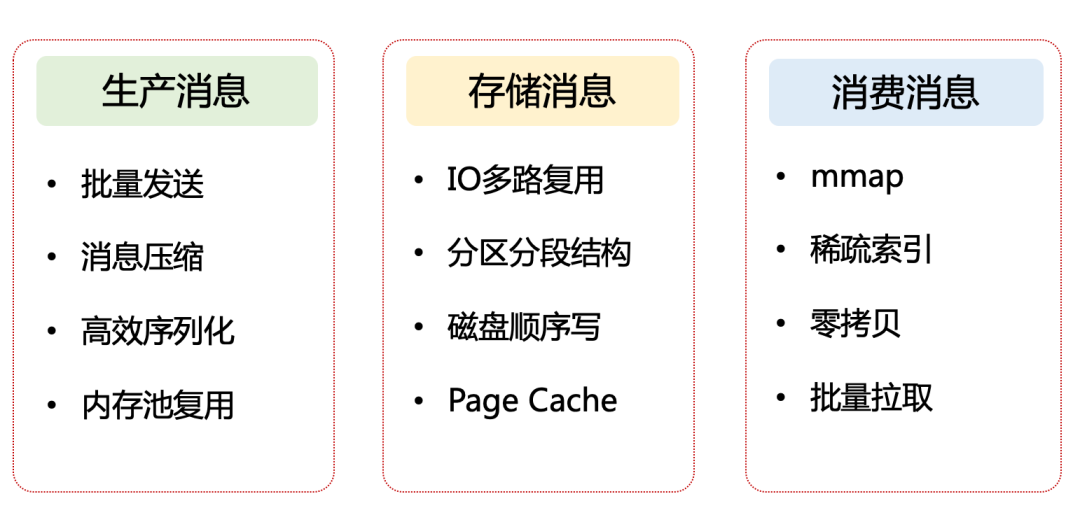
图 2:Kafka 高性能设计的全景图
有了这张全景图,下面我再挨个分析下每个手段背后的大致原理,并尝试解读下 Kafka 的设计哲学。
我们先从生产消息开始看,下面是 Producer 端所采用的 4 条优化手段。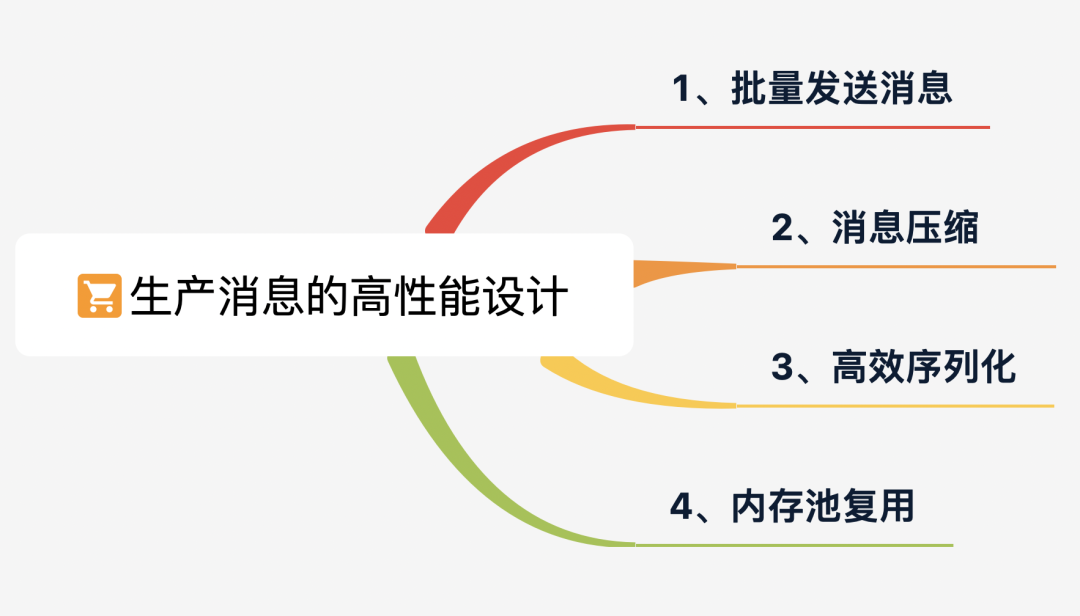
Kafka 作为一个消息队列,很显然是一个 IO 密集型应用,它所面临的挑战除了磁盘 IO(Broker 端需要对消息持久化),还有网络 IO(Producer 到 Broker,Broker 到 Consumer,都需要通过网络进行消息传输)。在上一篇文章已经指出过:磁盘顺序 IO 的速度其实非常快,不亚于内存随机读写。这样网络 IO 便成为了 Kafka 的性能瓶颈所在。基于这个背景, Kafka 采用了批量发送消息的方式,通过将多条消息按照分区进行分组,然后每次发送一个消息集合,从而大大减少了网络传输的 overhead。看似很平常的一个手段,其实它大大提升了 Kafka 的吞吐量,而且它的精妙之处远非如此,下面几条优化手段都和它息息相关。消息压缩的目的是为了进一步减少网络传输带宽。而对于压缩算法来说,通常是:数据量越大,压缩效果才会越好。因为有了批量发送这个前期,从而使得 Kafka 的消息压缩机制能真正发挥出它的威力(压缩的本质取决于多消息的重复性)。对比压缩单条消息,同时对多条消息进行压缩,能大幅减少数据量,从而更大程度提高网络传输率。有文章对 Kafka 支持的三种压缩算法:gzip、snappy、lz4 进行了性能对比,测试 2 万条消息,效果如下: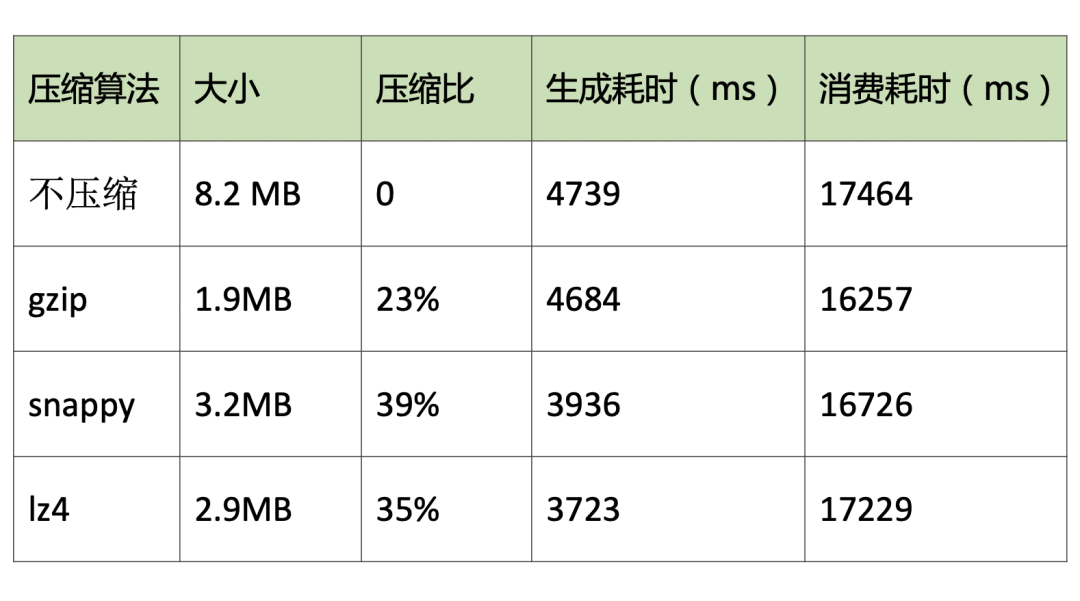
图 3:压缩效果对比,来源:https://www.jianshu.com/p/d69e27749b00
整体来看,gzip 压缩效果最好,但是生成耗时更长,综合对比 lz4 性能最佳。
其实压缩消息不仅仅减少了网络 IO,它还大大降低了磁盘 IO。因为批量消息在持久化到 Broker 中的磁盘时,仍然保持的是压缩状态,最终是在 Consumer 端做了解压缩操作。
这种端到端的压缩设计,其实非常巧妙,它又大大提高了写磁盘的效率。Kafka 消息中的 Key 和 Value,都支持自定义类型,只需要提供相应的序列化和反序列化器即可。因此,用户可以根据实际情况选用快速且紧凑的序列化方式(比如 ProtoBuf、Avro)来减少实际的网络传输量以及磁盘存储量,进一步提高吞吐量。前面说过 Producer 发送消息是批量的,因此消息都会先写入 Producer 的内存中进行缓冲,直到多条消息组成了一个 Batch,才会通过网络把 Batch 发给 Broker。
当这个 Batch 发送完毕后,显然这部分数据还会在 Producer 端的 JVM 内存中,由于不存在引用了,它是可以被 JVM 回收掉的。但是大家都知道,JVM GC 时一定会存在 Stop The World 的过程,即使采用最先进的垃圾回收器,也势必会导致工作线程的短暂停顿,这对于 Kafka 这种高并发场景肯定会带来性能上的影响。有了这个背景,便引出了 Kafka 非常优秀的内存池机制,它和连接池、线程池的本质一样,都是为了提高复用,减少频繁的创建和释放。具体是如何实现的呢?其实很简单:Producer 一上来就会占用一个固定大小的内存块,比如 64MB,然后将 64 MB 划分成 M 个小内存块(比如一个小内存块大小是 16KB)。当需要创建一个新的 Batch 时,直接从内存池中取出一个 16 KB 的内存块即可,然后往里面不断写入消息,但最大写入量就是 16 KB,接着将 Batch 发送给 Broker ,此时该内存块就可以还回到缓冲池中继续复用了,根本不涉及垃圾回收。最终整个流程如下图所示:
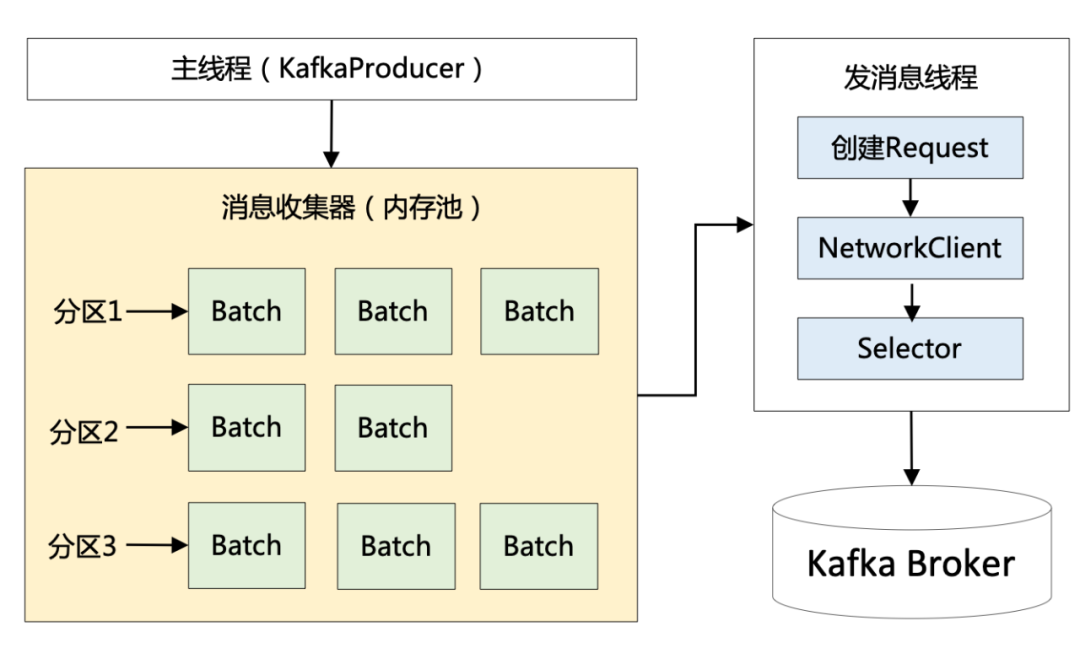
图 4:Kafka 发送端的流程
了解了 Producer 端上面 4 条高性能设计后,大家一定会有一个疑问:传统的数据库或者消息中间件都是想办法让 Client 端更轻量,将 Server 设计成重量级,仅让 Client 充当应用程序和 Server 之间的接口。但是 Kafka 却反其道而行之,采取了独具一格的设计思路,在将消息发送给 Broker 之前,需要先在 Client 端完成大量的工作,例如:消息的分区路由、校验和的计算、压缩消息等。这样便很好地分摊 Broker 的计算压力。可见,没有最好的设计,只有最合适的设计,这就是架构的本源。Kafka 在创造一个以性能为核心导向的解决方案上做得极其出色,它有非常多的设计理念值得深入研究和学习。考虑篇幅问题,我将 Kafka 的高性能设计分成了上下两篇,下一篇将继续展开阐述剩余 8 条高性能设计手段以及背后的设计思想。看到这里,我更希望大家能建立起高性能设计的思维模式以及学习方法,这些技巧同样可以帮助你吃透其他高性能的中间件。推荐阅读:
如出一辙。。。
Java 中的监控与管理原理概述
《吃透 MQ 系列》之 Kafka 架构设计的任督二脉
《吃透 MQ 系列》之扒开 Kafka 的神秘面纱
《吃透 MQ 系列》之 Kafka 存储选型的奥秘
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。
