
大白话教你认识 Kafka 背后优秀的架构设计
点击下方公众号「关注」和「星标」
回复666加群!
一、Kafka基础
消息系统的作用
应该大部份小伙伴都清楚,用机油装箱举个例子
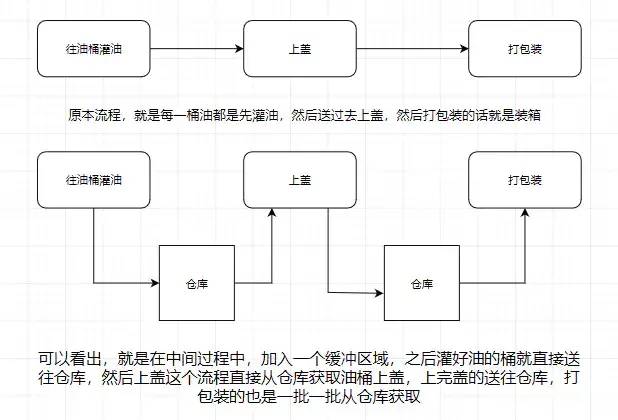
所以消息系统就是如上图我们所说的仓库,能在中间过程作为缓存,并且实现解耦合的作用。
引入一个场景,我们知道中国移动,中国联通,中国电信的日志处理,是交给外包去做大数据分析的,假设现在它们的日志都交给了你做的系统去做用户画像分析。
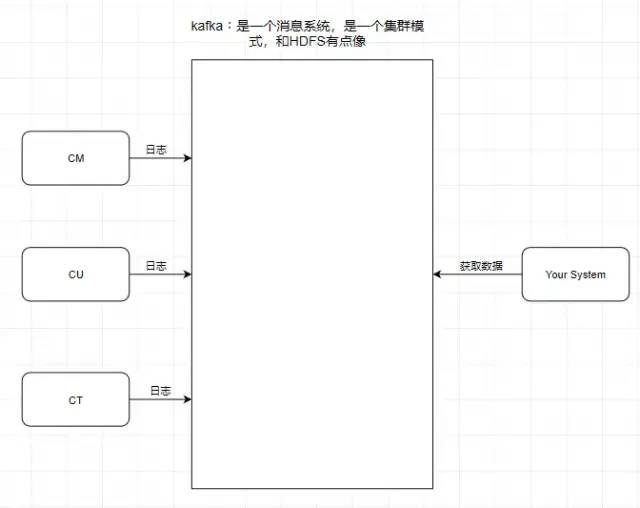
按照刚刚前面提到的消息系统的作用,我们知道了消息系统其实就是一个模拟缓存 ,且仅仅是起到了缓存的作用 而并不是真正的缓存,数据仍然是存储在磁盘上面而不是内存。
1.Topic 主题
kafka学习了数据库里面的设计,在里面设计了topic(主题),这个东西类似于关系型数据库的表
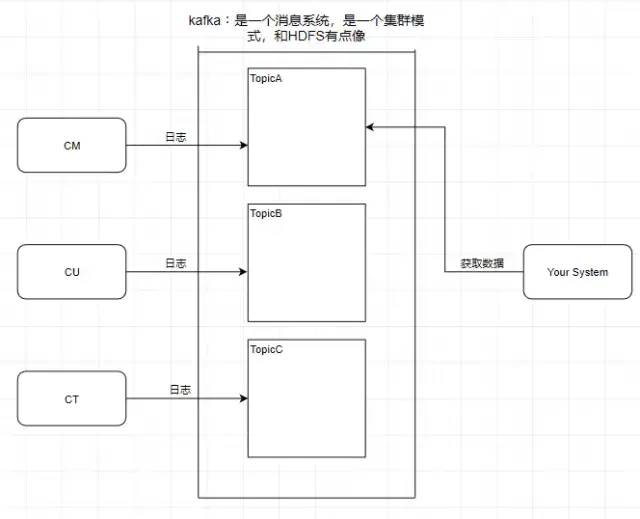
此时我需要获取中国移动的数据,那就直接监听TopicA即可
2.Partition 分区
kafka还有一个概念叫Partition(分区),分区具体在服务器上面表现起初就是一个目录,一个主题下面有多个分区,这些分区会存储到不同的服务器上面,或者说,其实就是在不同的主机上建了不同的目录。
这些分区主要的信息就存在了.log文件里面。跟数据库里面的分区差不多,是为了提高性能。
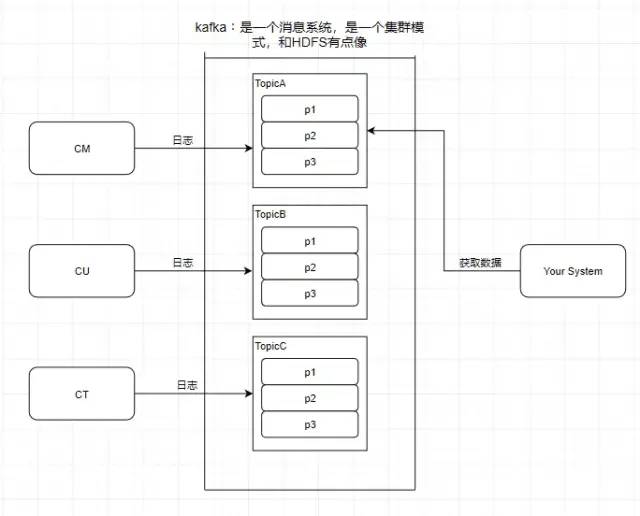
至于为什么提高了性能,很简单,多个分区多个线程,多个线程并行处理肯定会比单线程好得多
Topic和partition像是HBASE里的table和region的概念,table只是一个逻辑上的概念,真正存储数据的是region,这些region会分布式地存储在各个服务器上面,对应于kafka,也是一样,Topic也是逻辑概念 ,而partition就是分布式存储单元。这个设计是保证了海量数据处理的基础。
我们可以对比一下,如果HDFS没有block的设计,一个100T的文件也只能单独放在一个服务器上面,那就直接占满整个服务器了,引入block后,大文件可以分散存储在不同的服务器上。
注意:1.分区会有单点故障问题,所以我们会为每个分区设置副本数 2.分区的编号是从0开始的
3.Producer - 生产者
往消息系统里面发送数据的就是生产者
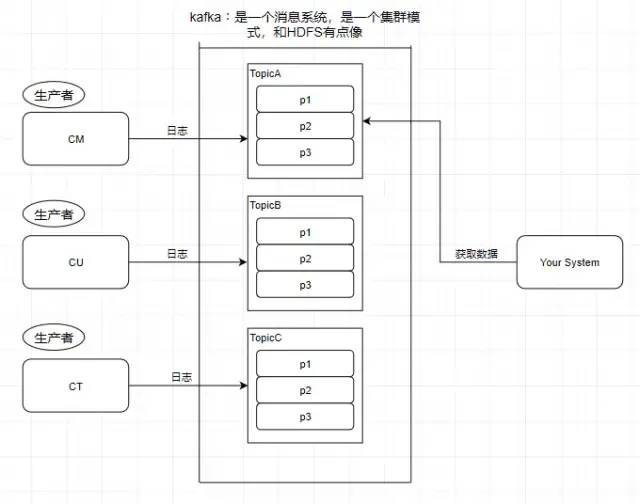
4.Consumer - 消费者
从kafka里读取数据的就是消费者
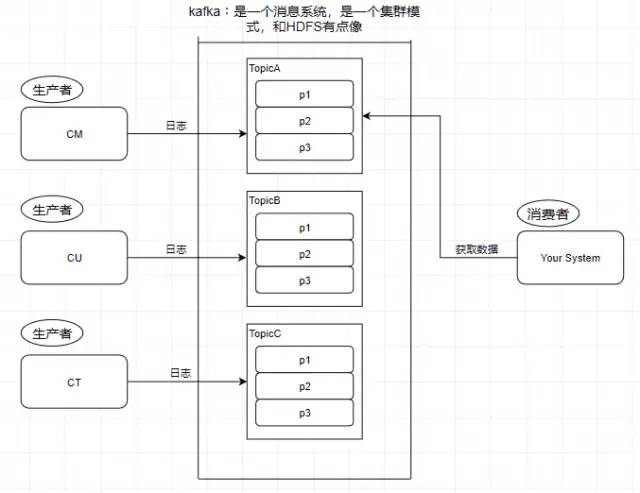
5.Message - 消息
kafka里面的我们处理的数据叫做消息
二、kafka的集群架构
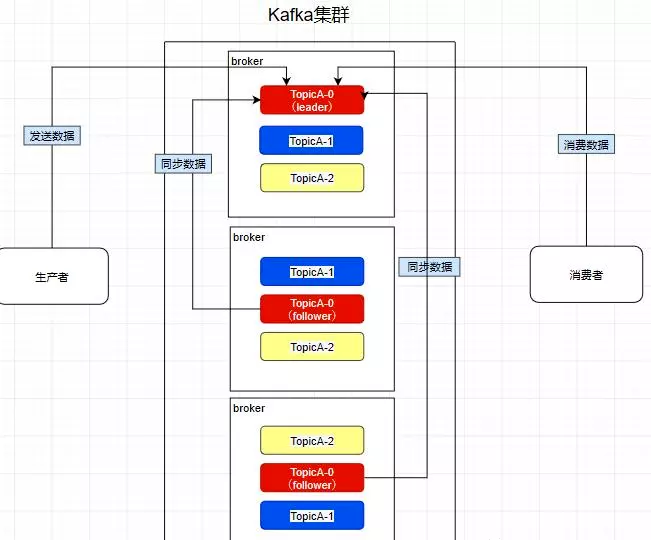
创建一个TopicA的主题,3个分区分别存储在不同的服务器,也就是broker下面。Topic是一个逻辑上的概念 ,并不能直接在图中把Topic的相关单元画出
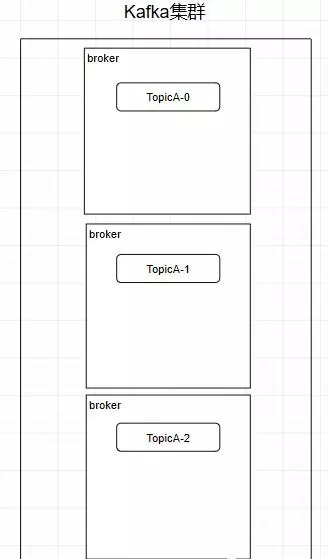
需要注意:kafka在0.8版本以前是没有副本机制的,所以在面对服务器宕机的突发情况时会丢失数据,所以尽量避免使用这个版本之前的kafka
Replica - 副本
kafka中的partition为了保证数据安全,所以每个partition可以设置多个副本。
此时我们对分区0,1,2分别设置3个副本(其实设置两个副本是比较合适的)
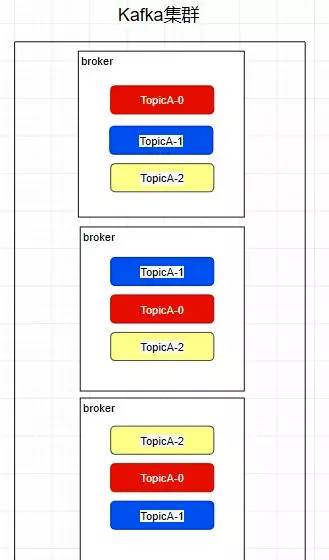
而且其实每个副本都是有角色之分的,它们会选取一个副本作为leader,而其余的作为follower,我们的生产者在发送数据的时候,是直接发送到leader partition里面 ,然后follower partition会去leader那里自行同步数据,消费者消费数据的时候,也是从leader那去消费数据的 。
Consumer Group - 消费者组
我们在消费数据时会在代码里面指定一个group.id,这个id代表的是消费组的名字,而且这个group.id就算不设置,系统也会默认设置
conf.setProperty("group.id","tellYourDream")
我们所熟知的一些消息系统一般来说会这样设计,就是只要有一个消费者去消费了消息系统里面的数据,那么其余所有的消费者都不能再去消费这个数据。可是kafka并不是这样,比如现在consumerA去消费了一个topicA里面的数据。
consumerA:
group.id = a
consumerB:
group.id = a
consumerC:
group.id = b
consumerD:
group.id = b
再让consumerB也去消费TopicA的数据,它是消费不到了,但是我们在consumerC中重新指定一个另外的group.id,consumerC是可以消费到topicA的数据的。而consumerD也是消费不到的,所以在kafka中,不同组可有唯一的一个消费者去消费同一主题的数据 。所以消费者组就是让多个消费者并行消费信息而存在的,而且它们不会消费到同一个消息,如下,consumerA,B,C是不会互相干扰的
consumer group:a
consumerA
consumerB
consumerC
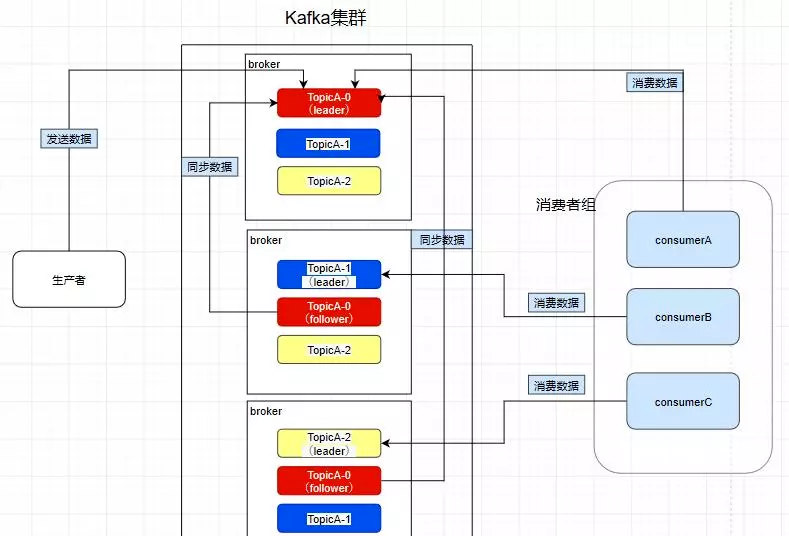
如图,因为前面提到过了消费者会直接和leader建立联系,所以它们分别消费了三个leader,所以一个分区不会让消费者组里面的多个消费者去消费 ,但是在消费者不饱和的情况下,一个消费者是可以去消费多个分区的数据的。
Controller
熟知一个规律:在大数据分布式文件系统里面,95%的都是主从式的架构,个别是对等式的架构,比如ElasticSearch。
kafka也是主从式的架构,主节点就叫controller,其余的为从节点,controller是需要和zookeeper进行配合管理整个kafka集群。
kafka和zookeeper如何配合工作
kafka严重依赖于zookeeper集群(不过从2.8版本之后:)。所有的broker在启动的时候都会往zookeeper进行注册,目的就是选举出一个controller,这个选举过程非常简单粗暴,就是一个谁先谁当的过程,不涉及什么算法问题。
那成为controller之后要做啥呢,它会监听zookeeper里面的多个目录。
例如有一个目录/brokers/,其他从节点往这个目录上注册(就是往这个目录上创建属于自己的子目录而已) 自己,这时命名规则一般是它们的id编号,比如/brokers/0,1,2
注册时各个节点必定会暴露自己的主机名,端口号等等的信息,此时controller就要去读取注册上来的从节点的数据(通过监听机制),生成集群的元数据信息,之后把这些信息都分发给其他的服务器,让其他服务器能感知到集群中其它成员的存在 。
此时模拟一个场景,我们创建一个主题(其实就是在zookeeper上/topics/topicA这样创建一个目录而已),kafka会把分区方案生成在这个目录中,此时controller就监听到了这一改变,它会去同步这个目录的元信息,然后同样下放给它的从节点,通过这个方法让整个集群都得知这个分区方案,此时从节点就各自创建好目录等待创建分区副本即可。这也是整个集群的管理机制。
加餐时间
1.Kafka性能好在什么地方?
① 顺序写
操作系统每次从磁盘读写数据的时候,需要先寻址,也就是先要找到数据在磁盘上的物理位置,然后再进行数据读写,如果是机械硬盘,寻址就需要较长的时间。kafka的设计中,数据其实是存储在磁盘上面,一般来说,会把数据存储在内存上面性能才会好。但是kafka用的是顺序写,追加数据是追加到末尾,磁盘顺序写的性能极高,在磁盘个数一定,转数达到一定的情况下,基本和内存速度一致
随机写的话是在文件的某个位置修改数据,性能会较低。
② 零拷贝
先来看看非零拷贝的情况
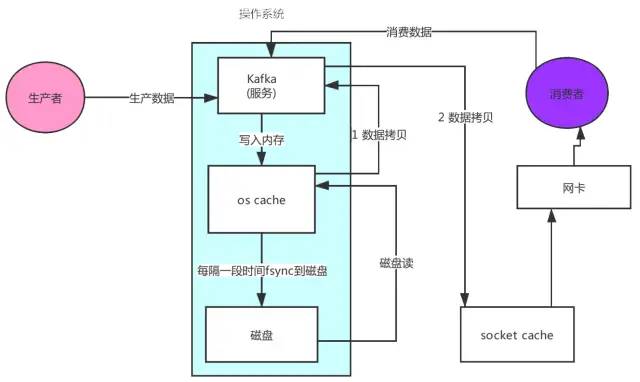
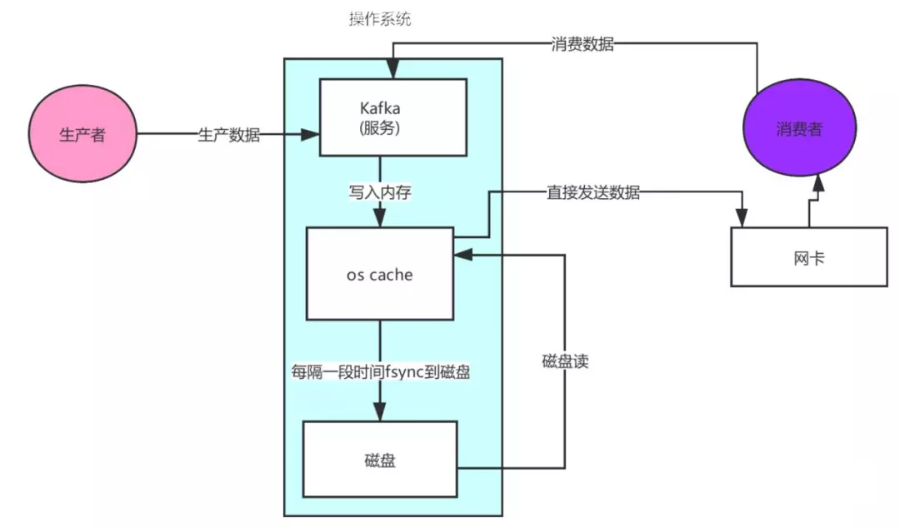
可以看到数据的拷贝从内存拷贝到kafka服务进程那块,又拷贝到socket缓存那块,整个过程耗费的时间比较高,kafka利用了Linux的sendFile技术(NIO),省去了进程切换和一次数据拷贝,让性能变得更好。
2.日志分段存储
Kafka规定了一个分区内的.log文件最大为1G,做这个限制目的是为了方便把.log加载到内存去操作
00000000000000000000.index
00000000000000000000.log
00000000000000000000.timeindex
00000000000005367851.index
00000000000005367851.log
00000000000005367851.timeindex
00000000000009936472.index
00000000000009936472.log
00000000000009936472.timeindex
这个9936472之类的数字,就是代表了这个日志段文件里包含的起始offset,也就说明这个分区里至少都写入了接近1000万条数据了。
Kafka broker有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是1GB,一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做log rolling,正在被写入的那个日志段文件,叫做active log segment。
如果大家有看前面的两篇有关于HDFS的文章时,就会发现NameNode的edits log也会做出限制,所以这些框架都是会考虑到这些问题。
3.Kafka的网络设计
kafka的网络设计和Kafka的调优有关,这也是为什么它能支持高并发的原因
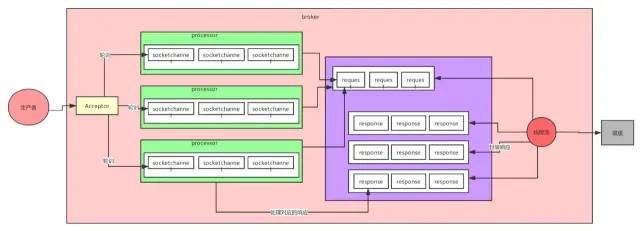
首先客户端发送请求全部会先发送给一个Acceptor,broker里面会存在3个线程(默认是3个),这3个线程都是叫做processor,Acceptor不会对客户端的请求做任何的处理,直接封装成一个个socketChannel发送给这些processor形成一个队列,发送的方式是轮询,就是先给第一个processor发送,然后再给第二个,第三个,然后又回到第一个。消费者线程去消费这些socketChannel时,会获取一个个request请求,这些request请求中就会伴随着数据。
线程池里面默认有8个线程,这些线程是用来处理request的,解析请求,如果request是写请求,就写到磁盘里。读的话返回结果。processor会从response中读取响应数据,然后再返回给客户端。这就是Kafka的网络三层架构。
所以如果我们需要对kafka进行增强调优,增加processor并增加线程池里面的处理线程,就可以达到效果。request和response那一块部分其实就是起到了一个缓存的效果,是考虑到processor们生成请求太快,线程数不够不能及时处理的问题。
所以这就是一个加强版的reactor网络线程模型。
finally
集群的搭建会再找时间去提及。这一篇简单地从角色到一些设计的方面讲述了Kafka的一些基础,在之后的更新中会继续逐步推进,进行更加深入浅出的讲解。
链接:https://juejin.cn/post/6844903999066341384
推荐阅读: