
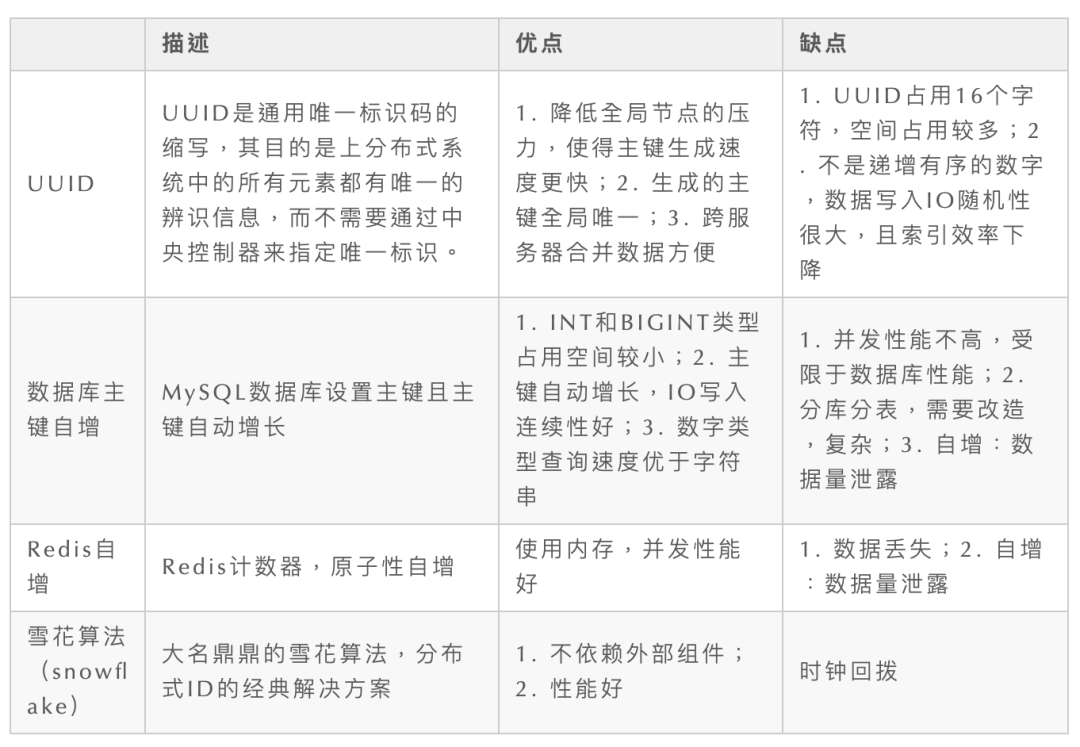
最常用的分布式 ID 解决方案,都在这里了
1、用 Java 撸了一款 SSH 客户端 2、处理 Exception 的几种实践,很优雅,被很多团队采纳! 3、一致性协议算法-2PC、3PC、Paxos、Raft、ZAB、NWR详解 4、这款IDEA插件刷爆了朋友圈,网友:一定是女朋友送的~ 5、@Autowire和@Resource注解使用的正确姿势,别再用错的了!!
「一、分布式ID概念」
「二、分布式ID实现方案」
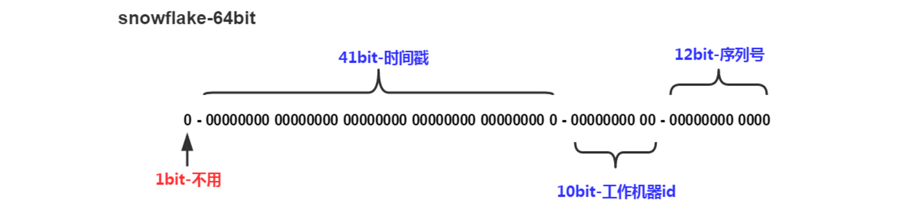
雪花算法能存放多少数据?时间范围:2^41 / (3652460601000) = 69年 工作进程范围:2^10 = 1024 序列号范围:2^12 = 4096,表示1ms可以生成4096个ID。
public class SnowFlake {
/**
* 起始的时间戳
*/
private final static long START_STMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATACENTER_BIT = 5;//数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT;
private long datacenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStmp = -1L;//上一次时间戳
public SnowFlake(long datacenterId, long machineId) {
if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
}
this.datacenterId = datacenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currStmp = getNewstmp();
if (currStmp < lastStmp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currStmp == lastStmp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currStmp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastStmp = currStmp;
return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分
| datacenterId << DATACENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
private long getNextMill() {
long mill = getNewstmp();
while (mill <= lastStmp) {
mill = getNewstmp();
}
return mill;
}
private long getNewstmp() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowFlake snowFlake = new SnowFlake(2, 3);
for (int i = 0; i < (1 << 12); i++) {
System.out.println(snowFlake.nextId());
}
}
}
「三、分布式ID开源组件」
3.1 如何选择开源组件
3.2 美团Leaf
全局唯一,绝对不会出现重复的ID,且ID整体趋势递增。 高可用,服务完全基于分布式架构,即使MySQL宕机,也能容忍一段时间的数据库不可用。 高并发低延时,在CentOS 4C8G的虚拟机上,远程调用QPS可达5W+,TP99在1ms内。 接入简单,直接通过公司RPC服务或者HTTP调用即可接入。
3.3 百度UidGenerator
3.4 开源组件对比
作者:James_Shangguan 来源:urlify.cn/3ARJRr
最近热文阅读:
1、用 Java 撸了一款 SSH 客户端 2、处理 Exception 的几种实践,很优雅,被很多团队采纳! 3、一致性协议算法-2PC、3PC、Paxos、Raft、ZAB、NWR详解 4、这款IDEA插件刷爆了朋友圈,网友:一定是女朋友送的~ 5、@Autowire和@Resource注解使用的正确姿势,别再用错的了!! 6、Java中的Switch都支持String了,为什么不支持long? 7、请谨慎使用Arrays.asList、ArrayList的subList 8、人脸识别“抓”错了人,他在监狱呆了 10 天 9、骚操作 !IDEA 防止写代码沉迷插件 ! 10、这四种情况下,才是考虑分库分表的时候! 关注公众号,你想要的Java都在这里
评论