
分库分表需要考虑的问题及方案
分库分表的基本思想就是把一个数据库切分成多个部分放到不同的数据库,用来缓解单一数据库的性能问题。即,有两种拆分方式,第一种拆分方式是把表进行拆分,把表放到多个server上,用来实现基本的拆分。第二种拆分方式是在表的数据量很大的时候,按照某种ID顺序,切分到多个数据库上。这两种切分方式被称为水平切分和垂直切分。
常用中间件
这里常用的中间件有以下几种。
简单易用的
当当网 sharding-jdbc
蘑菇街:Tsharding
强悍重量级中间件
sharding
TDDL Smart Client
Atlas
alibaba.cobar
MyCat
需要解决的问题
事物问题
解决事物问题,有两种可行的方案,这里使用分布式事物,或者通过应用程序与数据库共同控制实现事物。做一个简单的对比
方案一:使用分布式事物
优点:交给数据库管理,简单有效。缺点:性能代价相当高。
方案二:由应用程序和数据库共同控制
原理:把一个跨多个数据库的分布式事物分拆成多个仅处于单个数据库上的小事物,通过应用程序来控制各个小事物。优点:性能较高。缺点:需要应用程序在事物上做控制,
跨节点join的问题
只要是进行切分,跨节点的join就会有此问题。一般做法是分两次查询实现。第一次查询获得id,第二次再次查询获得第二次的id。
跨节点的count,order by, group by 以及聚合函数。
这是一类问题,解决办法就是在分节点上获取到数据,然后在应用程序端进行合并。
ID 问题
一旦数据库被切分到多个物理结点上,此时需要以下的方式作为数据库主键生成方式。
UUID
这是作为主键的最简单的方案,索引建立不方便,以及性能不方便。
维护数据库的Sequence表
在数据库中建立一个相关的表,表的结构如下
CREATE TABLE `SEQUENCE` (
`table_name` varchar(18) NOT NULL,
`nextid` bigint(20) NOT NULL,
PRIMARY KEY (`table_name`)
) ENGINE=InnoDB
通过使用Twitter的Snowflake算法
这里使用推特的UUID算法,进行生成。
10---0000000000 0000000000 0000000000 0000000000 0 --- 00000 ---00000 ---000000000000
在上面的字符串中,第一位为未使用(实际上也可作为long的符号位),接下来的41位为毫秒级时间,然后5位datacenter标识位,5位机器ID(并不算标识符,实际是为线程标识),然后12位该毫秒内的当前毫秒内的计数,加起来刚好64位,为一个Long型。
这样的好处是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由datacenter和机器ID作区分),并且效率较高,经测试,snowflake每秒能够产生26万ID左右,完全满足需要。
跨分片的排序分页
一般来讲,分页需要按照指定字段进行排序,排序字段就是分片信息。通过分片规则可以定位到指定的分片。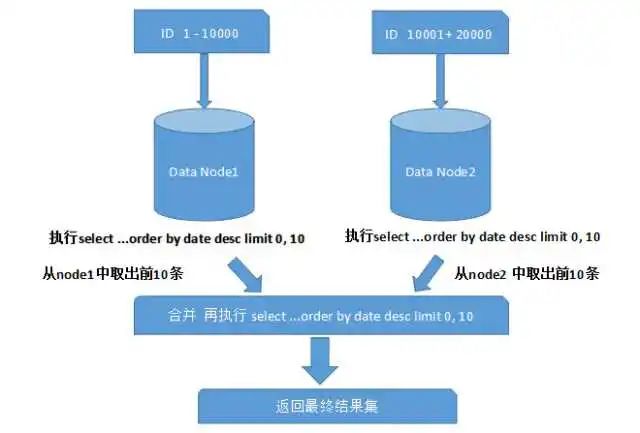
上面图中所描述的只是最简单的一种情况(取第一页数据),看起来对性能的影响并不大。但是,如果想取出第10页数据,情况又将变得复杂很多,如下图所示:
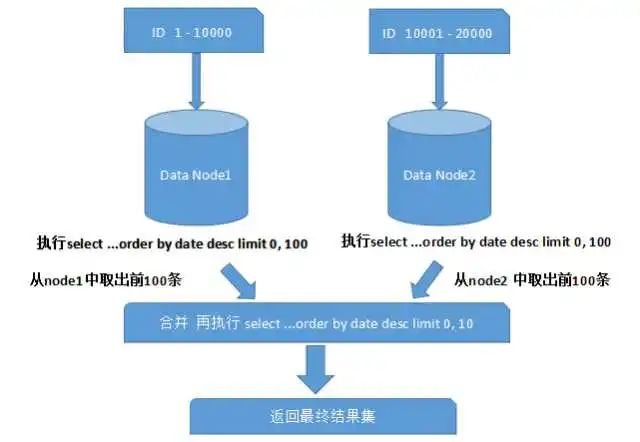
分库方式
分库确定以后,如何把记录分到各自库里?一般由两种方式
根据数值范围确定,id为1-999分到一个库,999以后分到另外一个库。 进行取模。
分库数量
分库数量和单库的处理记录条数有关,Mysql单库5000万条进行分库。
路由透明
对于单库访问,必如查询条件指定用户ID,则该SQL只需要访问特定库,此时DAL会进行自动的路由。
使用框架还是自主研发
各有优势,各有短板。综合考虑。
有道无术,术可成;有术无道,止于术
欢迎大家关注Java之道公众号
好文章,我在看❤️