
王小川又发大模型,闭源或许离商业更近
 大数据文摘受权转载自AI科技评论
大数据文摘受权转载自AI科技评论
作者丨董子博
编辑丨林觉民
3B 大模型,是王小川做大模型的第三步,也或成百川智能商业化的第一步。
8月8日立秋,北京总算短暂逃离了持续近2个月的酷暑,气温舒适。在海淀的塞尔大厦,身着黑色T恤的王小川姗姗来迟。
自百川智能官宣创业,已经过了近4个月的时间。这中间,Baichuan-7B、Baichuan-13B 相继开源,几乎2个月一个版本,进展神速。
而他们的第三个大模型——Baichuan 53B(下简称“53B”),也在今天加入了他们的大模型产品矩阵。
在过去的时间里,7B、13B 两个大模型不仅在榜单上跑分不错,而且也被不少公司拿来使用。王小川说,据百川统计,已经有150家以上的公司申请使用他们的开源模型,并且收获的评价也不错。
而此次的 53B 大模型,也集成了他们在前两次探索中获得的经验。
一方面,高质量、多样化、有层次的预训练数据,是百川做大模型训练的基础;
另一方面,有搜狗的基因做支持,百川也将搜索能力和大模型能力结合到一起,以搜索增强对抗幻觉和时效性不足的大模型原生问题——在经过搜索技术的赋能,对用户的意图完成理解、优化之后,来完成用户prompt的调优;
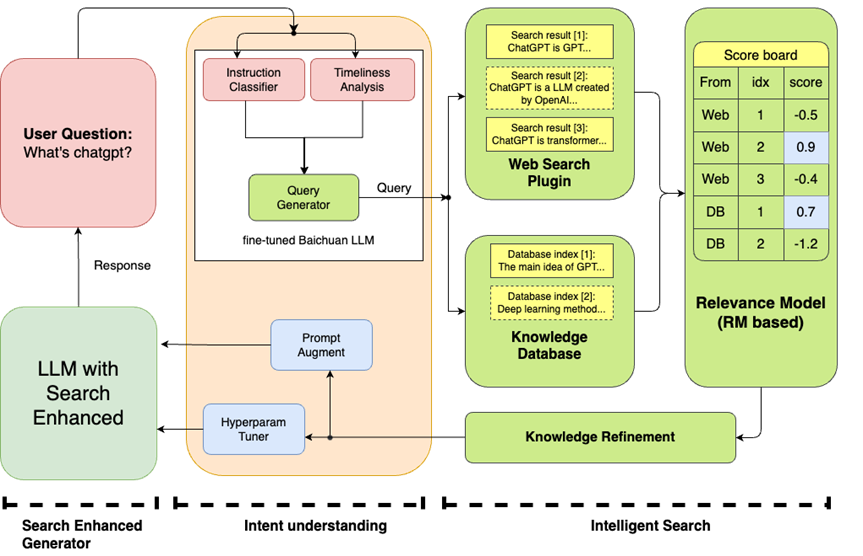
搜索增强技术路径图
而同时,53B 的另一个“有力兵器”是它的对齐调整,多目标优化、多 RM 融合等技术,让 53B 的有用性和可靠性,都获得了大幅度的增强。
而在技术之外,最引人关心的,莫过于百川的开源和闭源之辩。一改过去两款大模型的开源,53B 选择闭源,百川智能有着怎样技术和商业上的考量?
对于开源和闭源的战略,外界有解读:开源是为闭源服务的前置手段,通过免费的服务先积累用户和口碑,再用闭源的、能力更强的模型收取费用,完成商业上的营收。
而近期,曾主管搜狗运营的洪涛回到王小川麾下,也让人对百川未来的商业化路径浮想联翩。
王小川则表示,53B 的闭源,最主要的原因还是模型规模大、部署成本高,相比 7B、13B 规模的模型,体量更大,更适合闭源做简单接口,客户使用起来也会更方便。
而之所以选择在今天做闭源、做商业化,王小川表示,当下的机会很多,开源只是中间的一件事,未来在 To B 服务、To C 产品上,百川不会只专注于一个小赛道。
“我们对自己团队过往的能力也好、经验也好,是有信心的,能同时打好几场仗。”谈到这里,王小川胸有成竹,意气飞扬。
在4月,王小川曾公开表示,在今年 Q3,百川会发布一款参数量级在500亿以上的大模型产品。
8月上旬,Q3尚未过半,百川就完成了他们给自己定下的“KPI”。这不由得让人浮想联翩——4月提到的,“今年年底,对标ChatGPT3.5的模型”,是否也可以如期兑现?
战略执行按部就班,融资也相当顺利。据王小川本人披露,百川已经完成了第二轮融资,估值在5亿美金左右,正稳步向着大模型独角兽的“小目标”迈进。
点「在看」的人都变好看了哦!