
正确配置Python应用程序

概述:Python模块和包



在__init__.py中放入代码


多个环境&十二因素应用程序
不经常更改的静态内容,或者显著影响系统行为的内容应该存在于代码中。 频繁更改的动态内容或应该保密的内容(API键/凭据)应该存在于代码之外。
我们如何切换环境?
Ruby/Rails生态系统使用RACK_ENV或RAILS_ENV Javascript项目通常会利用NODE_ENV
我的本地开发环境没有设置一个ENV变量,因此系统默认情况下会推断开发环境。 AWS CodePipeline上的测试环境使用ENV=test EC2上的生产环境使用ENV=production
最终的目标

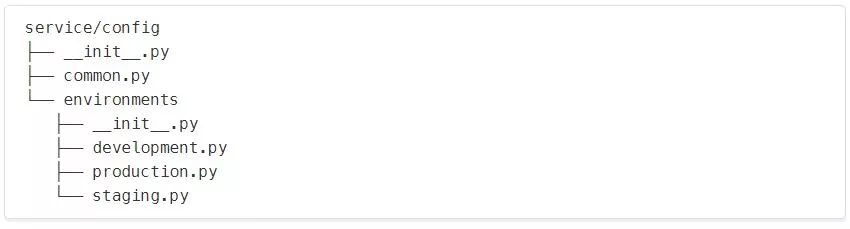
common.py包含我们所有的公共或共享配置。这些东西在不同的环境中并没有太大的不同。你可以称其为base或shared配置,如果你愿意。 environments/development.py包含开发配置。该文件可以排除在版本控制之外,这样团队中的每个开发人员都可以实现自己的配置设置。 environments/(production|staging).py包含每个环境特有的配置。

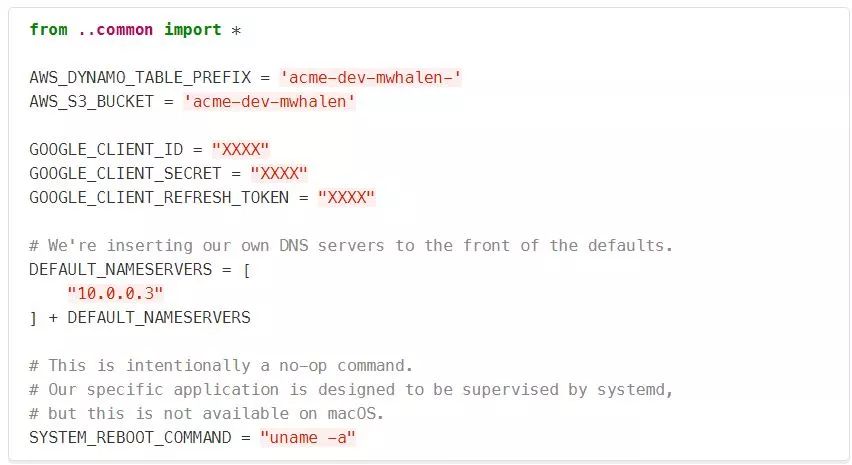
我们首先导入common配置,以便在默认情况下继承所有公共配置。现在我们可以添加、替换或增加参数,而不需要从父配置进行复制粘贴。 为了支持本地开发, 我可以自定义在我的环境中使用的AWS资源。系统的其余部分没有改变,但是现在我的本地系统使用我自己的Dynamo表和S3 bucket。 因为该文件不在版本控制中,所以我可以放心地存储机密信息,比如我自己的GOOGLE_CLIENT_ credentials。 因为可以访问公共的DEFAULT_NAMESERVERS,所以我可以扩展它们,而不是复制粘贴任何公共值到我自己的配置中。 在生产环境中,systemd命令用于在响应某些管理操作时重新启动应用程序。因为我的Mac没有systemd,所以我用一个简单的no-op替换了system reboot命令,从而完全避免了这个问题。
它是如何工作的

首先,我们导入importlib模块(文档),它为我们提供了一些用代码导入代码的方便工具。 使用我们建立的约定—ENV环境变量—我们获取当前运行的环境的名称。 如果没有设置环境,我们就选择development作为默认设置,但是如前所述,这个决定将根据系统的不同而有所不同。 我们甚至可以考虑阻止应用程序启动,除非定义了这个变量。下面是一个这样的例子: 
接下来我们使用importlib.import_module函数将包含特定环境代码的模块加载到局部变量module中。 最后,我们更新这个模块的globals,将development.py文件中设置合并到其中。 最终,你将看到一些便利的工具(a-la Rails),使基于环境切换具体的逻辑变得更加容易。它们作为函数保存,以便将实现隔离到此模块,而不是隔离到使用它的任何地方。
一个真实的例子
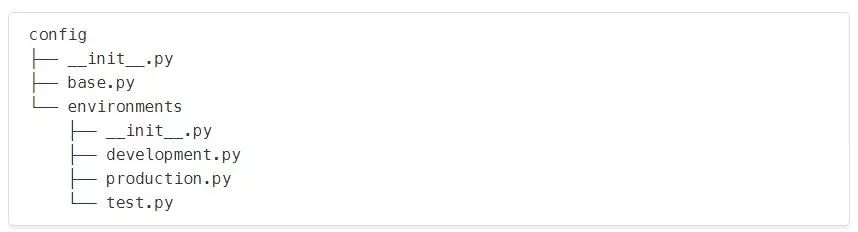
development.py在本地使用 production.py用于Heroku test.py用于带有pytest的本地单元测试
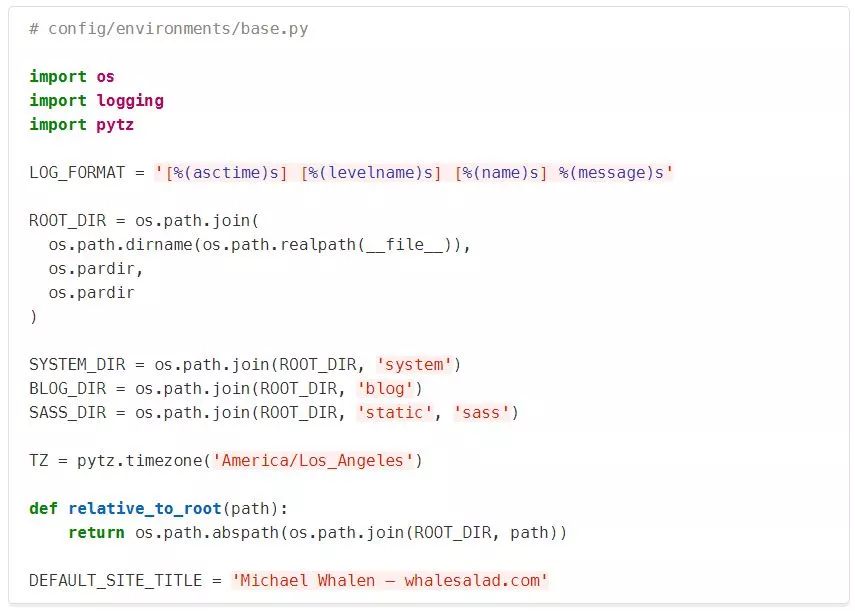
一个在项目的其他地方使用的集中式日志格式。 通用目录和一个使路径相关的工作更容易的助手函数。 我的服务的时区。 当页面不提供自己的标题时使用的默认标题。
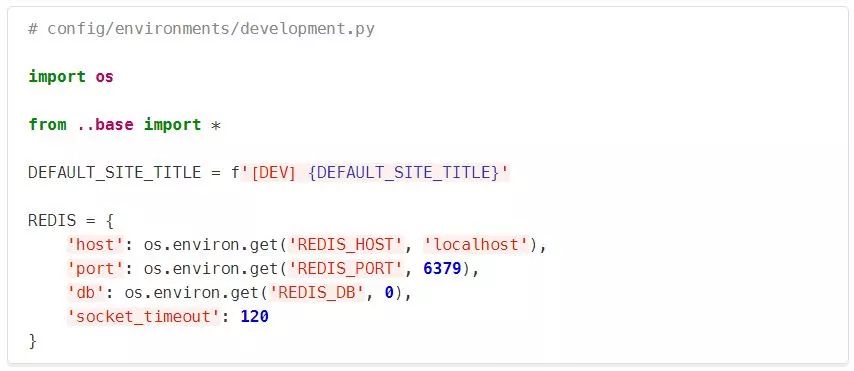
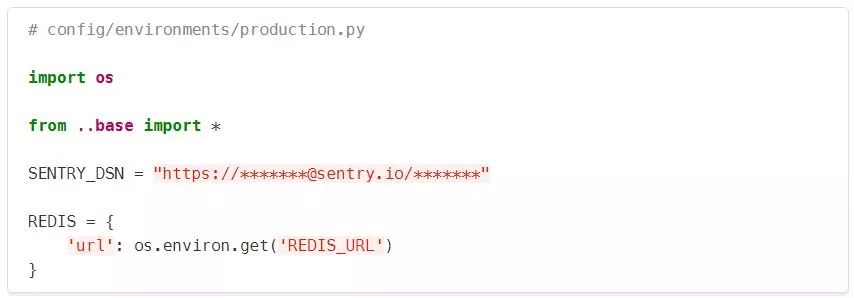
SENTRY_DSN只在production.py中被定义,而没有在base或其他环境中定义。这是为了防止Sentry(集中式错误日志)在开发或测试情况下被激活。 在Heroku上,Redis连接细节来自一个URL,因此我们在这里进行了配置。

结论
我们有创造无限数量环境的灵活性。例如,如果我们想为一个拉取请求启动一个临时环境:我们只需要使用“cp environments/staging.py environments/PR_402.py and ENV=PR_402”就可以了。 当在本地进行开发时,我们可以在生产模式下运行系统,方法是在它前面加上ENV=production,反之亦然,我们也可以在开发或测试模式下在其他任何地方运行软件。 开发人员可以通过查看每个环境被覆盖的配置来快速收集每个环境之间的主要差异。这使得将新的团队成员加入到你的代码库中变得更加容易。 类似地,团队中的每个开发人员都可以有自己独特的配置。这不会过多地影响中心配置,因为你的系统有一些不同于其他系统的设置。 我们可以通过显式地将environments/test.py 中的某些变量设置为None来保护我们的测试环境,以避免意外地访问生产环境资源。 我们消除了在各种CLI工具(如Docker等等)之间传递较大键/值配置映射的负担(尽管现在的工具越来越能够从文件中读取env) 我们将我们的配置公开为一个普通的Python包,因此与其他Python工具几乎没有学习曲线和互操作性问题。 我们避免了支持外部库/依赖项所需要的成本。
文章转载:Python编程学习圈
(版权归原作者所有,侵删)
![]()

点击下方“阅读原文”查看更多
评论