
修剪网络要趁早?「彩票假说」告诉你关于剪枝的一切

新智元报道
新智元报道
来源:TNW
编辑:小匀
【新智元导读】深度学习的确很出色,但其成本也不能避之不谈,碳足迹、商业化等等都使深度学习变得越来越昂贵。本文综合了几篇论文,探讨了在不对其性能产生重大影响的情况下,为什么即使是当前最先进的方法,也无法降低神经网络训练的成本。
深度学习好吗?
好!但是成本很贵……大量的计算资源、训练,还有碳足迹和AI研究的商业化,这些成本给人工智能界带来了若干挑战。
尽管AI研究员在降低运行深度学习模型的成本方面取得了进步,但降低训练成本的更大问题仍未解决。
麻省理工学院计算机科学与人工智能实验室(MIT CSAIL),多伦多大学向量实验室和Element AI的AI研究人员最近取得了进展。在题为「在初始化时剪枝神经网络:我们为什么会遗漏标记」的论文中,在不对其性能产生重大影响的情况下,研究人员讨论了为什么即使是当前最先进的方法,也无法降低神经网络训练的成本。

训练 后剪枝 深度神经网络
GPT-3我们都知道,这个大型神经网络可谓成了精,这个具有1,750亿个参数的AI背后却是高达数百万美元的代价。此外,您需要数百GB的VRAM和强大的服务器来运行该模型。
好消息是,有大量的工作证明,神经网络可以被「剪枝」。
这意味着在给定非常大的神经网络的情况下,存在一个较小的子集,可以提供与原始AI模型相同的准确性,而不会对其性能造成重大损失。例如,今年早些时候,一对AI研究人员表明,尽管大型的深度学习模型可以学习预测约翰·康威(John Conway)的《生命游戏》中的未来步骤,但几乎总是存在一个较小的神经网络,可以训练该神经网络执行相同的操作精确地完成任务。

在深度学习模型遍历整个训练过程后,可以丢弃许多参数,有时将其缩小到原始大小的10%。
「彩票假说」提出小子集训练
训练后剪枝神经网络的问题在于,它不会削减调整所有多余参数的成本。即使训练过的神经网络压缩到原始大小的一小部分,您仍然需要支付训练它的全部费用。
那么,是否可以在不训练整个神经网络的情况下找到最佳子网?
麻省理工学院CSAIL的两位AI研究人员,该论文的合著者Jonathan Frankle和Michael Carbin于2018年发表了一篇题为「彩票假说」的论文,该论文证明,在许多深度学习模型中,一些小子集可以训练到完全准确。
找到这些子网,就能大大减少训练深度学习模型的时间和成本。彩票假说的发布引发了对在初始化或训练初期剪枝神经网络的方法的研究。
AI研究人员在他们的新论文中研究了一些更广为人知的早期剪枝方法:ICLR 2019上展示的单发网络剪枝(SNIP); 在ICLR 2020上展示的梯度信号保存(GraSP)和迭代突触流剪枝(SynFlow)。
SNIP的目标是减少对损失最不重要的砝码。GraSP的目的是剪枝对梯度流有害或影响最小的砝码。「 SynFlow反复剪枝权重,目的是避免层崩溃,在这种情况下,剪枝会集中在网络的某些层上并过早降低性能。」
早期神经网络剪枝如何执行?
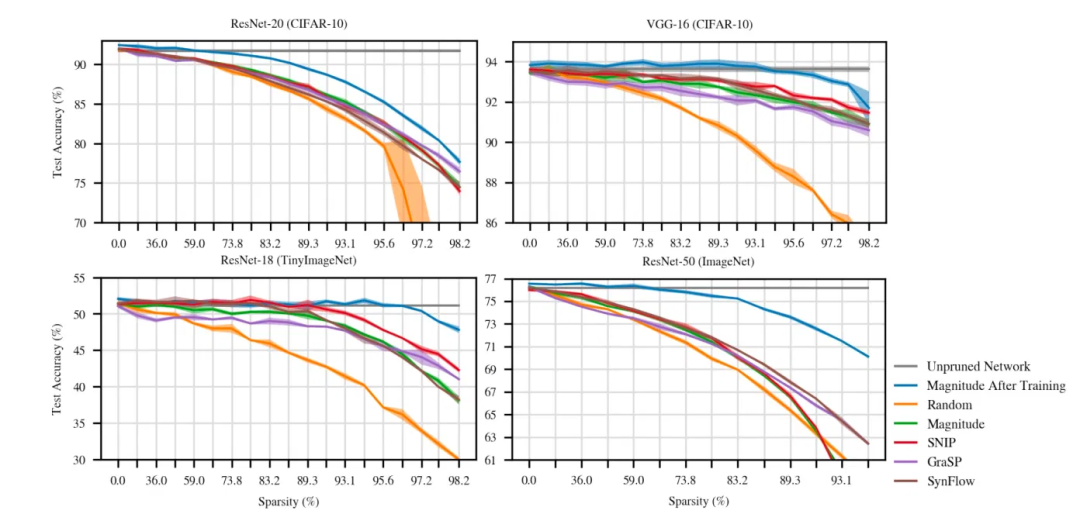
几种新技术可以在初始化阶段剪枝深度神经网络。尽管它们的性能优于随机剪枝,但仍未达到pos训练基准
研究人员还将早期剪枝方法与两种简单技术进行了比较。其中之一从神经网络中随机删除权重。检查随机性能对于验证一种方法是否提供了重要的结果很重要。
另一种方法是根据参数的绝对权重删除参数。「幅度剪枝是剪枝的一种标准方法,并且是早期剪枝的另一个比较幼稚的比较点。」
实验是在VGG-16和ResNet的三个变体「两个流行的 卷积神经网络 (CNN)」上进行的。
在AI研究人员评估的早期剪枝技术中,没有哪一种早期方法能脱颖而出,并且性能会因所选的神经网络结构和剪枝百分比而异。但是他们的发现表明,在大多数情况下,这些最新方法比粗随机剪枝要好得多。
但是,这些方法都无法达到基准训练后剪枝的准确性。
总体而言,这些方法取得了一些进展,通常胜于随机剪枝。然而,就整体准确性和可以达到完全准确性的稀疏性而言,训练后的进展仍然远远不够。
研究人员试验多种早期剪枝方法
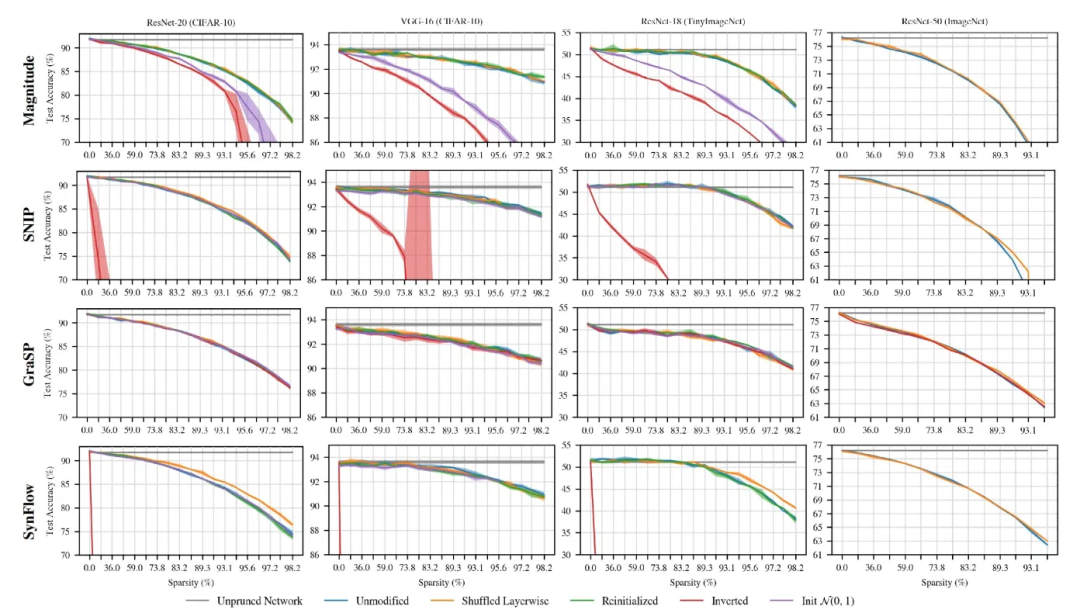
对早期剪枝方法的测试表明,它们对随机改组和重新初始化具有强大的抵抗力,这表明它们没有在目标神经网络中找到特定的剪枝权重
为了测试剪枝方法为何表现不佳,AI研究人员进行了几次测试。首先,他们测试了「随机改组」。对于每种方法,他们随机切换从神经网络的每一层中删除的参数,以查看它是否对性能产生影响。如果如剪枝方法所建议的那样,它们根据相关性和影响删除参数,那么随机切换将严重降低性能。
令人惊讶的是,研究人员发现随机改组对结果没有严重影响。相反,真正决定结果的是它们从每一层去除的权重的数量。
接下来,研究人员检查了重新初始化网络是否会改变剪枝方法的性能。在训练之前,将使用所选分布中的随机值初始化神经网络中的所有参数。以前的工作,包括Frankle和Carbin所做的工作,以及本文前面提到的「生命游戏」研究,都表明这些初始值通常会对培训的最终结果产生重大影响。实际上,术语「彩票」是基于以下事实而创造的:幸运的初始值可以使小型神经网络在训练中达到高精度。
因此,应根据参数值选择参数,并且如果更改其初始值,则将严重影响剪枝网络的性能。再次,测试没有显示出重大变化。
最后,他们尝试反转剪枝后的重量。这意味着对于每种方法,他们都将砝码标记为可移动,而去掉了应该保留的砝码。最终测试将检查用于选择剪枝权重的计分方法的效率。SNIP和SynFlow这两种方法对反演显示出极大的敏感性,而其准确性却下降了,这是一件好事。但是,在减去剪枝后的权重后,GraSP的性能并没有降低,在某些情况下,它甚至表现更好。
这些测试的关键之处在于,当前的早期剪枝方法无法检测到在深度学习模型中定义最佳子网的特定连接。
在训练神经网络之前剪枝它们,可以为无法访问大量计算资源的更广泛的AI研究人员和实验室提供新的机会。

