
太牛逼了!用 Python 实现抖音上的“人像动漫化”特效,原来这么简单!
来自公众号:数据分析与统计学之美
前几天,女友拉着我和她玩儿抖音,就是这个人像动漫化的操作,顿时觉得很好玩儿。我心想:python既然这么强大,是不是也可以使用python程序来实现这样一个操作呢?
哈哈!我自己当然是没有这个本事编写这样一个牛逼的程序出来,但是百度可以呀,并且还很好用。百度AI开放平台给我们提供了完整的接口,甚至贴心的将代码都给我们写好了。这些接口还支持很多主流语言都呢,像Java、Python、PHP、C#等,我们做的就是直接调用它即可。效果怎么样呢?我们先来看看下方的对比图吧。
效果展示
原图和动漫图:

原图和戴口罩的动漫图:

那么这样的动漫图,究竟是怎么做出来的呢?今天我就带着大家一一探究一下。
原理分析
这里首先给大家提供下面的一个网址,这就是百度AI开放平台关于人像动漫化特效的网页。http://suo.im/64FNvD
在这里我们可以上传自己的图片(如图所示),进行人像动漫画的操作。

但是呢?这个并不是今天的重点,如果说我想要为动漫图片带口罩,你就没辙了吧。
在该页面有一个重要的东西:软件操作人像动漫化的接口(如图所示)。从左边可以看到,这是一个Post请求,发送该请求的网址并不全,需要你提供自己的access_token。同时呢,发送Post请求不仅需要携带Headers,还需要携带一个Params参数,其中Headers是固定的,image参数是图片的Base64编码格式。该Post请求的返回值Response是一个字典,我们这里先记住就行了。

除了上面所叙述的,这个网址显示的页面中还有一个很重要的东西:人像动漫画接口的API文档(如图所示),该文档可以帮助我们怎么写代码,百度够贴心吧。
API文档网址:http://suo.im/64FNZ9
从图中可以看到,这个API文档中不仅有人像动漫画的操作,还有黑白图像上色、图像修复等一系列操作,都是很好玩的。希望大家学习了本文以后,能够下去玩玩其他的操作。

通过上述的原理分析:实现人像动漫画操作,最终就转化为发送一个Post请求。而发送Post请求呢,我们就需要获取我们的access_token参数。
access_token参数的获取
获取access_token参数,需要使用百度的鉴权认证机制。下面就是鉴权认证机制的网址,在该网页上,详细介绍了我们怎么获取自己的access_token参数。
鉴权认证机制网址:http://suo.im/6rUoTr
仔细查看本页面上的文档,我们可以很容易的发现:获取access_token参数,就是是发送一次Post请求,该请求的返回值是一个字典,里面有我们想要获取的access_token参数。
https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【官网获取的AK】&client_secret=【官网获取的SK】
上面是这个Post请求的网址,但是可以看到这个网址也是不全的,它还需要我们在官网中获取到自己的【官网获取的AK】和【官网获取的SK】,其中AK指的是API Key,SK指的是Secret Key。
通过上述的分析:为了获取access_token参数,也是发送一个Post请求,而发送Post请求,就需要我们找到自己的API Key和Secret Key。
寻找API Key和Secret Key
首先登陆百度智能云的网址。这个网址需要我们扫码登陆,我们按照提示进行登陆即可。
百度智能云:https://login.bce.baidu.com/
当出现下面这个页面,我们完成图中的操作。
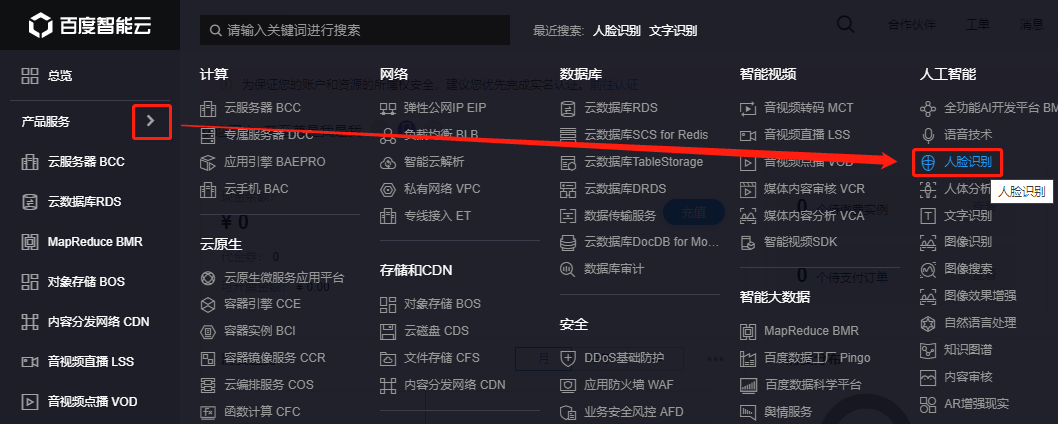
当出现如下页面,我们点击应用列表。
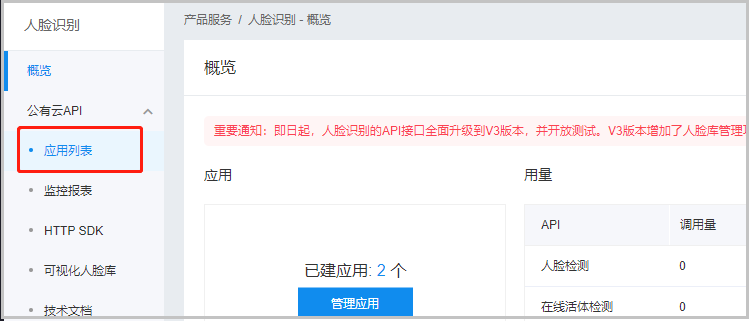
可以看到,这里已经有我创建好的两个应用。如果你是第一次创建,你这里什么也没有,直接点击创建应用。记住:这里就有我们想要的API Key和Secret Key。
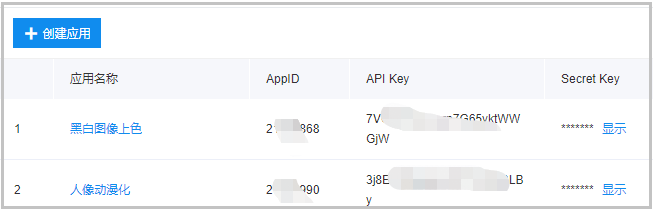
当出现如下界面,完成如下的操作。
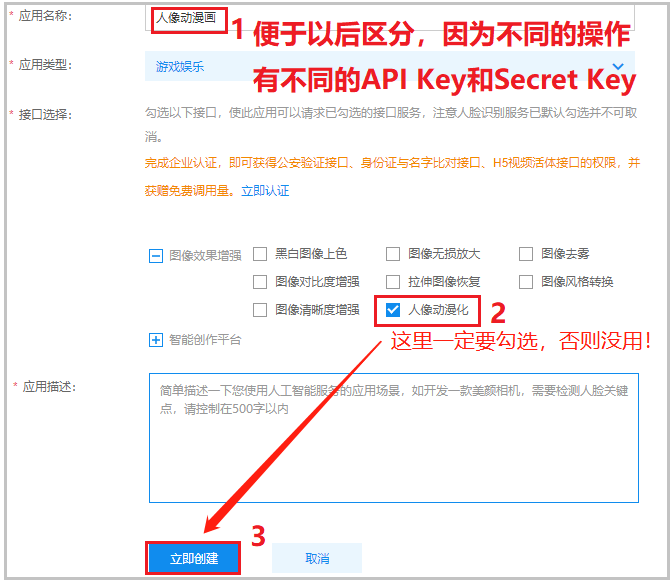
创建成功后,直接查看应用列表即可,最终页面如下。
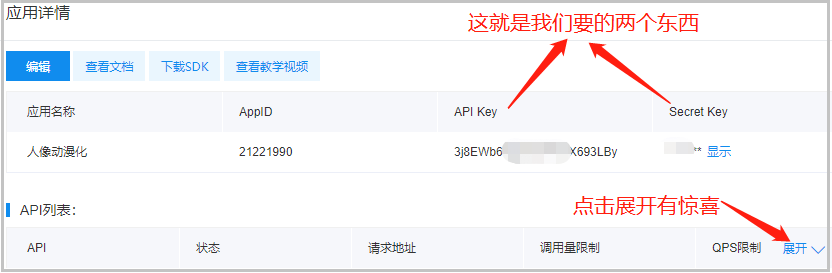
点击展开后,我们可以查看某个API的使用次数。因为有些API接口并不是一直免费的,有效次数使用完了以后,需要付费使用啦。下图也可以看到人像动漫画操作大致也就500次的免费使用次数。

代码展示
1)单纯的人像动漫化,不为人像戴口罩
import requests, base64
# 这个函数的操作是为了获取access_token参数
def get_access_token():
url = 'https://aip.baidubce.com/oauth/2.0/token'
data = {
'grant_type': 'client_credentials', # 固定值
'client_id': '3j8EWb6rgg..SPY2X693LBy', # 在开放平台注册后所建应用的API Key
'client_secret': 'Px9KZuU0Gl...jTKktoCopnIWEiF57gf' # 所建应用的Secret Key
}
res = requests.post(url, data=data)
res = res.json()
#print(res)
access_token = res['access_token']
return access_token
# 下面的代码就是API文档中的代码,直接搬过来使用即可。
request_url = "https://aip.baidubce.com/rest/2.0/image-process/v1/selfie_anime"
f = open('zhao.jpg', 'rb') # 二进制方式打开图片文件
img = base64.b64encode(f.read()) # 图像转为base64的格式,这是百度API文档中要求的
params = {"image":img}
access_token = '24.11731cd1f0...9f9b3a930f917f3681b.2592000.1596894747.282335-21221990'
request_url = request_url + "?access_token=" + get_access_token()
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
res = response.json()
# 前面我们讲述了这个请求返回的是一个字典,其中一个键就是image,代表的是处理后的图像信息。
# 将这个图像信息写入,得到最终的效果图。
if res:
f = open("kouzhao4.jpg", 'wb')
after_img = res['image']
after_img = base64.b64decode(after_img)
f.write(after_img)
f.close()
2)人像动漫化,并为人像戴口罩
import requests, base64
# 这个函数的操作是为了获取access_token参数
def get_access_token():
url = 'https://aip.baidubce.com/oauth/2.0/token'
data = {
'grant_type': 'client_credentials', # 固定值
'client_id': '3j8EWb6rgg...SPY2X693LBy', # 在开放平台注册后所建应用的API Key
'client_secret': 'Px9KZuU0Gl...jTKktoCopnIWEiF57gf' # 所建应用的Secret Key
}
res = requests.post(url, data=data)
res = res.json()
#print(res)
access_token = res['access_token']
return access_token
request_url = "https://aip.baidubce.com/rest/2.0/image-process/v1/selfie_anime"
# 二进制方式打开图片文件
f = open('zhao.jpg', 'rb')
img = base64.b64encode(f.read())
# 注意:这里就是多了type参数和mask_id参数,都是在源文档中可以查看的参数。
# type的值为anime或者anime_mask。前者生成二次元动漫图,后者生成戴口罩的二次元动漫人像。
# 1~8之间的整数,用于指定所使用的口罩的编码。大家可以自行下去尝试。
params = {"image":img,"type":'anime_mask',"mask_id":"2"}
access_token = '24.11731cd1f0...9f9b3a930f917f3681b.2592000.1596894747.282335-21221990'
request_url = request_url + "?access_token=" + get_access_token()
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
res = response.json()
# print(res)
if res:
f = open("kouzhao5.jpg", 'wb')
after_img = res['image']
after_img = base64.b64decode(after_img)
f.write(after_img)
f.close()
回复关键词「简明python」,立即获取入门必备书籍《简明python教程》电子版
回复关键词「爬虫」,立即获取爬虫学习资料
python入门与进阶
每天与你一起成长
推荐阅读