
Elastic Job从单点到高可用、同城主备、同城双活
在使用Elastic Job Lite做定时任务的时候,我发现很多开发的团队都是直接部署单点,这对于一些离线的非核心业务(如对账、监控等)或许无关紧要,但对于一些高可用补偿、核心数据定时修改(如金融场景的利息更新等),单点部署则“非常危险”。实际上,Elastic Job Lite是支持高可用的。网上关于Elastic Job的较高级的博文甚少,本文试图结合自身实践的一些经验,大致讲解其方案原理,并延伸至同城双机房的架构实践。
注:本文所有讨论均基于开源版本的Elastic Job Lite, 不涉及Elastic Job Cloud部分。
单点部署到高可用
如本文开头所说,很多系统的部署是采取以下部署架构:
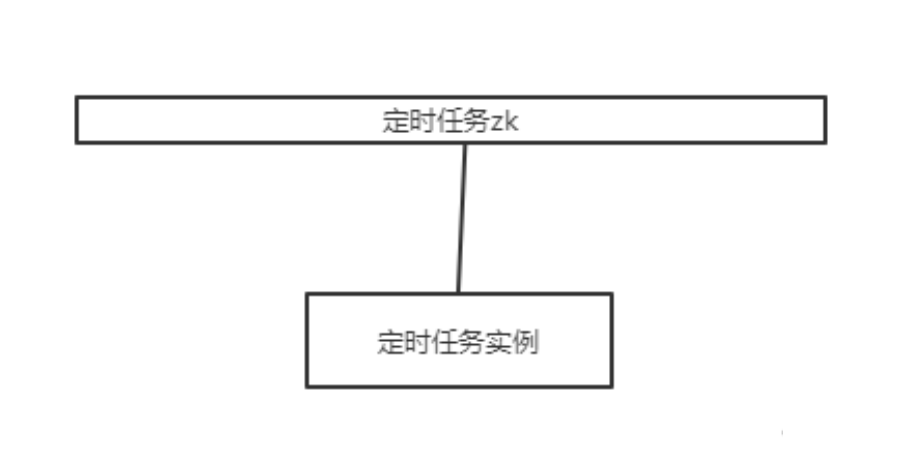
原因是开发者担心定时任务在同一时刻被触发多次,导致业务有问题。实际上这是对于框架最基本的原理不了解。在官方文档的功能列表里http://elasticjob.io/docs/elastic-job-lite/00-overview/ 就已说明其最基本的功能之一就是:
作业分片一致性,保证同一分片在分布式环境中仅一个执行实例
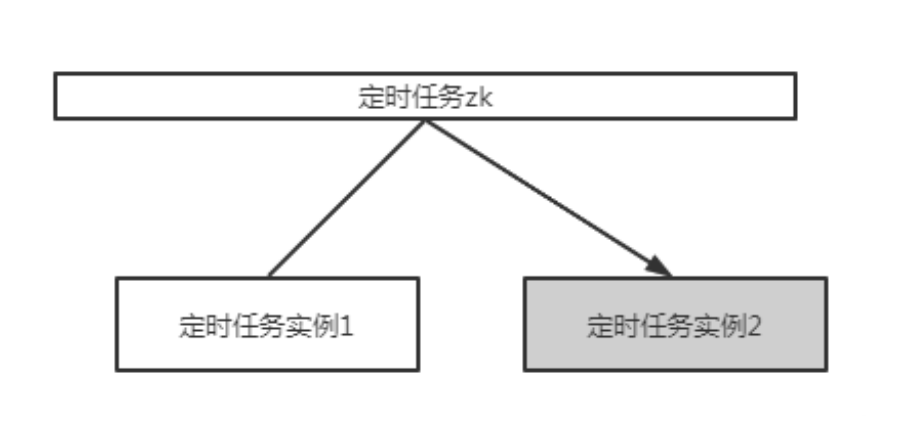
Elastic Job会依赖zookeeper选举出对应的实例做sharding,从而保证只有一个实例在执行同一个分片(如果任务没有采取分片(即分片数是0),就意味着这个任务只有一个实例在执行)
双机房高可用
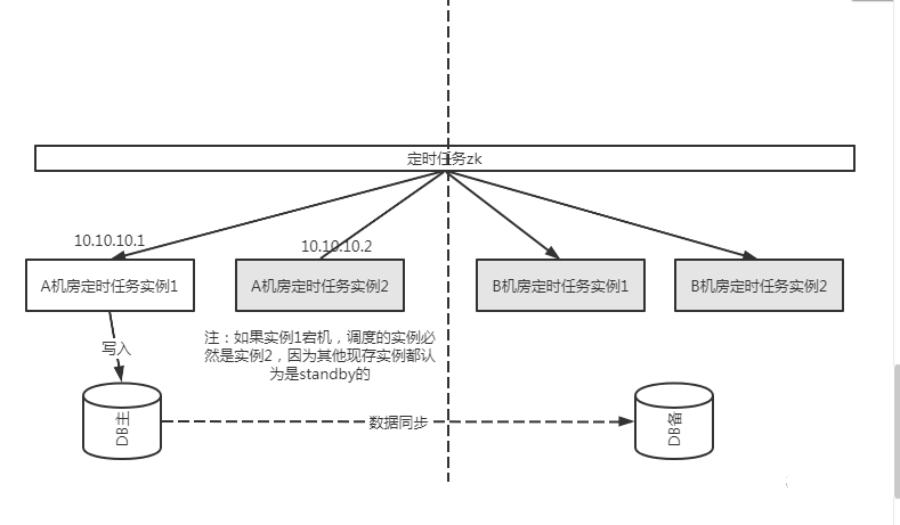
随着互联网业务的发展,慢慢地,对架构的高可用会有更高的要求。下一步可能就是需要同城两机房部署,那这时候为了保证定时服务在两个机房的高可用,我们架构上可能会变成这样的:
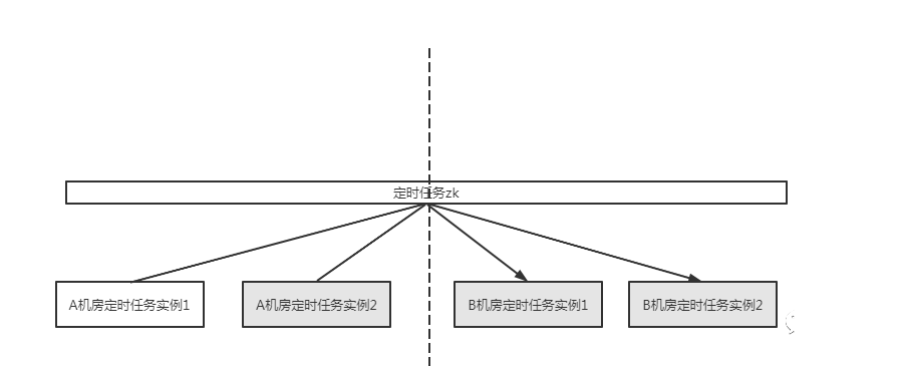
这样如果A机房的定时任务全部不可用了,B机房的确也能接手提供服务。而且由于集群是一个,Elastic Job能保证同一个分片在两个机房也只有一个实例运行。看似挺完美的。
注:本文不讨论zookeeper如何实现双机房的高可用,实际上从zookeeper的原理来看,仅仅两个机房组成一个大集群并不可以实现双机房高可用。
优先级调度?
以上的架构解决了定时任务在两个机房都可用的问题,但是实际的生产中,定时任务很可能是依赖存储的数据源的。而这个数据源,通常是有主备之分(这里不考虑单元化的架构的情况):例如主在A机房,备在B机房做实时同步。
如果这个定时任务只有读操作,可能没问题,因为只要配置数据源连接同机房的数据源即可。但是如果是要写入的,就有一个问题——如果所有任务都在B机房被调度了,那么这些数据的写入都会跨机房地往A机房写入,这样延迟就大大提升了,如下图所示。
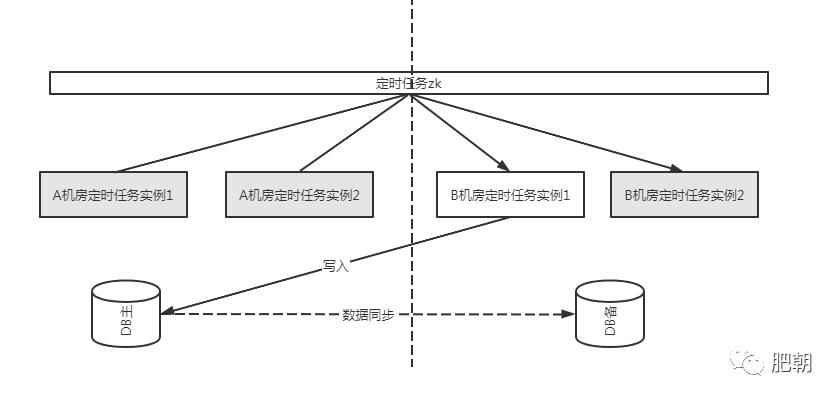
如图所示,如果Elastic Job把任务都调度到了B机房,那么流量就一直跨机房写了,这样对于性能来说是不好的事情。
那么有没有办法达到如下效果了:
保证两个机房都随时可用,也就是一个机房的服务如果全部不可用了,另外一个机房能提供对等的服务 但一个任务可以优先指定A机房执行
Elastic Job分片策略
在回答这个问题之前,我们需要了解下Elastic Job的分片策略,根据官网的说明(http://elasticjob.io/docs/elastic-job-lite/02-guide/job-sharding-strategy/ ) ,Elastic Job是内置了一些分片策略可选的,其中有平均分配算法,作业名的哈希值奇偶数决定IP升降序算法和作业名的哈希值对服务器列表进行轮转;同时也是支持自定义的策略,实现实现JobShardingStrategy接口并实现sharding方法即可。
public Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount)
假设我们可以实现这一的自定义策略:让做分片的时候知道哪些实例是A机房的,哪些是B机房的,然后我们知道A机房是优先的,在做分片策略的时候先把B机房的实例踢走,再复用原来的策略做分配。这不就解决我们的就近接入问题(接近数据源)了吗?
以下是利用装饰器模式自定义的一个装饰器类(抽象类,由子类判断哪些实例属于standby的实例),读者可以结合自身业务场景配合使用。
public abstract class JobShardingStrategyActiveStandbyDecorator implements JobShardingStrategy {
//内置的分配策略采用原来的默认策略:平均
private JobShardingStrategy inner = new AverageAllocationJobShardingStrategy();
/**
* 判断一个实例是否是备用的实例,在每次触发sharding方法之前会遍历所有实例调用此方法。
* 如果主备实例同时存在于列表中,那么备实例将会被剔除后才进行sharding
* @param jobInstance
* @return
*/
protected abstract boolean isStandby(JobInstance jobInstance, String jobName);
@Override
public Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount) {
List<JobInstance> jobInstancesCandidates = new ArrayList<>(jobInstances);
List<JobInstance> removeInstance = new ArrayList<>();
boolean removeSelf = false;
for (JobInstance jobInstance : jobInstances) {
boolean isStandbyInstance = false;
try {
isStandbyInstance = isStandby(jobInstance, jobName);
} catch (Exception e) {
log.warn("isStandBy throws error, consider as not standby",e);
}
if (isStandbyInstance) {
if (IpUtils.getIp().equals(jobInstance.getIp())) {
removeSelf = true;
}
jobInstancesCandidates.remove(jobInstance);
removeInstance.add(jobInstance);
}
}
if (jobInstancesCandidates.isEmpty()) {//移除后发现没有实例了,就不移除了,用原来的列表(后备)的顶上
jobInstancesCandidates = jobInstances;
log.info("[{}] ATTENTION!! Only backup job instances exist, but do sharding with them anyway {}", jobName, JSON.toJSONString(jobInstancesCandidates));
}
if (!jobInstancesCandidates.equals(jobInstances)) {
log.info("[{}] remove backup before really do sharding, removeSelf :{} , remove instances: {}", jobName, removeSelf, JSON.toJSONString(removeInstance));
log.info("[{}] after remove backups :{}", jobName, JSON.toJSONString(jobInstancesCandidates));
} else {//全部都是master或者全部都是slave
log.info("[{}] job instances just remain the same {}", jobName, JSON.toJSONString(jobInstancesCandidates));
}
//保险一点,排序一下,保证每个实例拿到的列表肯定是一样的
jobInstancesCandidates.sort((o1, o2) -> o1.getJobInstanceId().compareTo(o2.getJobInstanceId()));
return inner.sharding(jobInstancesCandidates, jobName, shardingTotalCount);
}
利用自定义策略实现同城双机房下的优先级调度
以下是一个很简单的就近接入的例子:指定在ip白名单的,就是优先执行的,不在的都认为是备用的。我们看如何实现。
一、继承此装饰器策略,指定哪些实例是standby实例
public class ActiveStandbyESJobStrategy extends JobShardingStrategyActiveStandbyDecorator{
@Override
protected boolean isStandby(JobInstance jobInstance, String jobName) {
String activeIps = "10.10.10.1,10.10.10.2";//只有这两个ip的实例才是优先执行的,其他都是备用的
String ss[] = activeIps.split(",");
return !Arrays.asList(ss).contains(jobInstance.getIp());//不在active名单的就是后备
}
}
很简单吧!这样实现之后,就能达到以下类似的效果
二、 在任务启动前,指定使用这个策略
以下以Java的方式示意,
JobCoreConfiguration simpleCoreConfig = JobCoreConfiguration.newBuilder(jobClass.getName(), cron, shardingTotalCount).shardingItemParameters(shardingItemParameters).build();
SimpleJobConfiguration simpleJobConfiguration = new SimpleJobConfiguration(simpleCoreConfig, jobClass.getCanonicalName());
return LiteJobConfiguration.newBuilder(simpleJobConfiguration)
.jobShardingStrategyClass("com.xxx.yyy.job.ActiveStandbyESJobStrategy")//使用主备的分配策略,分主备实例(输入你的实现类类名)
.build();
这样就大功告成了。
同城双活模式
以上这样改造后,针对定时任务就已经解决了两个问题:
1、定时任务能实现在两个机房下的高可用
2、任务能优先调度到指定机房
这种模式下,对于定时任务来说,B机房其实只是个备机房——因为A机房永远都是优先调度的。
对于B机房是否有一些实际问题其实我们可能是不知道的(常见的例如数据库权限没申请),由于没有流量的验证,这时候真的出现容灾问题,B机房是否能安全接受其实并不是100%稳妥的。
我们能否再进一步做到同城双活呢?也就是,B机房也会承担一部分的流量?例如10%?
回到自定义策略的sharding接口:
public Map<JobInstance, List<Integer>> sharding(List<JobInstance> jobInstances, String jobName, int shardingTotalCount)
在做分配的时候,是能拿到一个任务实例的全景图(所有实例列表),当前的任务名,和分片数。
基于此其实是可以做一些事情把流量引流到B机房实例的,例如:
指定任务的主机房让其是B机房优先调度(例如挑选部分只读任务,占10%的任务数) 对于分片的分配,把末尾(如1/10)的分片优先分配给B机房。
以上两种方案都能实现让A、B两个机房都有流量(有任务在被调度),从而实现所谓的双活。
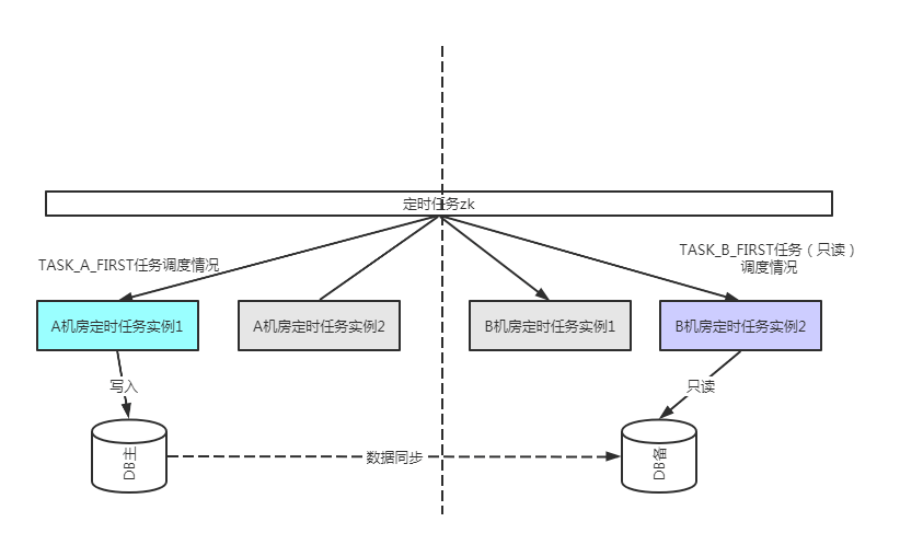
以下针对上面抛出来的方案一,给出一个双活的示意代码和架构。
假设我们定时任务有两个任务,TASK_A_FIRST,TASK_B_FIRST,其中TASK_B_FIRST是一个只读的任务,那么我们可以让他配置读B机房的备库让他优先运行在B机房,而TASK_A_FIRST是一个更为频繁的任务,而且带有写操作,我们则优先运行在A机房,从而实现双机房均有流量。
注:这里任意一个机房不可用了,任务均能在另外一个机房调度,这里增强的只是对于不同任务做针对性的优先调度实现双活
public class ActiveStandbyESJobStrategy extends JobShardingStrategyActiveStandbyDecorator{
@Override
protected boolean isStandby(JobInstance jobInstance, String jobName) {
String activeIps = "10.10.10.1,10.10.10.2";//默认只有这两个ip的实例才是优先执行的,其他都是备用的
if ("TASK_B_FIRST".equals(jobName)){//选择这个任务优先调度到B机房
activeIps = "10.11.10.1,10.11.10.2";
}
String ss[] = activeIps.split(",");
return !Arrays.asList(ss).contains(jobInstance.getIp());//不在active名单的就是后备
}
}
来源:https://jaskey.github.io/blog/2020/05/25/elastic-job-timmer-active-standby/ 推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)