
记住关系型数据库设计要领就够了!
不点蓝字关注,我们哪来故事?
一个指导程序员进入大公司/独角兽的精品社群,致力于分享职场达人的专业打法,包括「学习路线+简历模板+实习避坑+笔试面试+试用转正+升职加薪+跳槽技巧」。
摘要
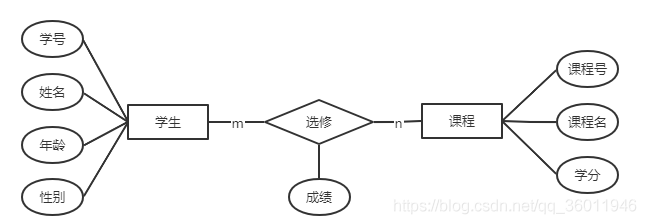
实体-关系模型(E-R)
实体:实体是世界中可以区别于其他对象的“事件”或者“物体”,例如,学校里的每个学生、学生选修的每门课程等都是一个实体。属性:属性是实体集中每个成员具有的描述性性质。例如,学生的姓名,学号等。实体集:实体集就是就有相同类型及属性的实体集合,比如,学校里的所有学生,学生选修的所有课程等。关系:关系是多个实体间的相互关联。例如,小明选修语文课程。关系集:关系集是同类关系的集合。例如,所用学生选修课程的集合。
关系表设计
Boyce-Codd范式
α→β 是平凡函数依赖(即 β ⊂ α)。(一般来说,平凡函数依赖并没有讨论意义,讨论的都是非平凡函数依赖,即 β ∉⊂ α 的情况) α 是模式R的超码。
学生 = (学号,姓名,年龄,性别)
课程 = (课程号,课程名,学分)
选修 = (学号,课程号,成绩)
banker-name → branch-name branch-name customer-name → banker-name
第三范式
BCNF。 无损连接。 保持函数依赖。
α→β 是平凡函数依赖(即 β ⊂ α)。 α 是模式R的超码。 β - α 中的每个属性 A 都包含在R的候选码中。
每个BCNF都属于3NF,因为BCNF的约束比3NF更严格。
存储引擎的选择
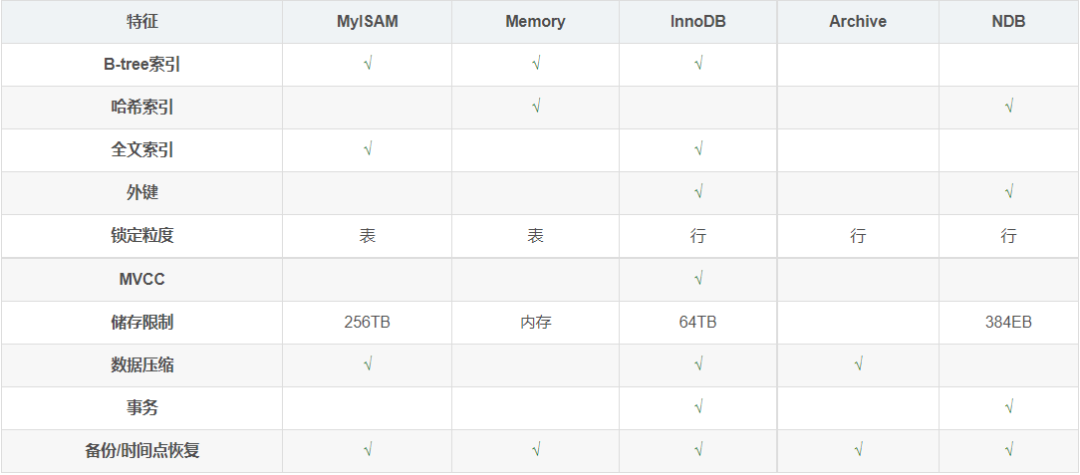
MyISAM:MySQL 5.5.5以前,MyISAM作为MySQL的默认存储引擎。 InnoDB:MySQL 5.5.5以后,InnoDB作为MySQL的默认存储引擎。
何如选择?
InnoDB和非InnoDB存储引擎的组合对比,仅使用InnoDB存储引擎可以简化备份和恢复操作。MySQL Enterprise Backup对使用InnoDB存储引擎的所有表进行热备份。对于使用MyISAM或其他非InnoDB存储引擎的表,它会执行“热”备份,数据库会继续运行,但这些表在备份时不能修改。
InnoDB:事务型业务场景首选。 MyISAM:非事务型的大多数业务场景。 Memory:数据保存到内存中,能提供极速的访问速度。(个人觉得可以使用Redis等NoSQL数据库代替)
字符集选择
如何选择?
数据类型的选择
选择原则
固定长度和可变长度
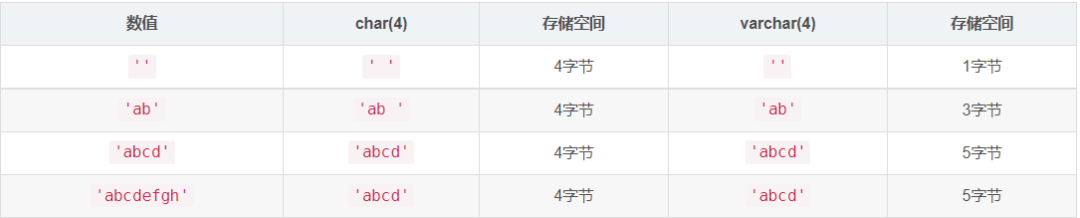
mysql> CREATE TABLE vc (v VARCHAR(4), c CHAR(4));
Query OK, 0 rows affected (0.01 sec)
mysql> INSERT INTO vc VALUES ('ab ', 'ab ');
Query OK, 1 row affected (0.00 sec)
mysql> SELECT CONCAT('(', v, ')'), CONCAT('(', c, ')') FROM vc;
+---------------------+---------------------+
| CONCAT('(', v, ')') | CONCAT('(', c, ')') |
+---------------------+---------------------+
| (ab ) | (ab) |
+---------------------+---------------------+
1 row in set (0.06 sec)
执行大量的删除和更新操作后,会留下很”空洞“,需要定期optimize table进行碎片整理; 避免查询大型的text和blob。查询大型的text和blob会使一页能装下的数据量减少,增加磁盘I/O压力。 把text和blob分离到单独的表中。这会把原来表中的数据列转变为更短的固定长度的数据行格式,这个十分有用。
浮点数和定点数
友情提醒:在有关金钱交易方面浮点数慎用!!!
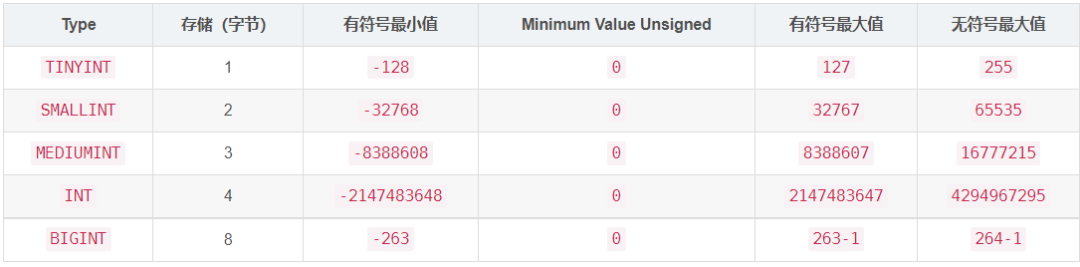
整数
索引设计
设计原则
搜索的索引列,不一定是所要选择的列。最适合索引的列是出现在 WHERE 子 句中的列,或连接子句中指定的列,而不是出现在 SELECT 关键字后的选择列表中的列。 使用惟一索引。对于惟一值的列,索引的效果最好,而具有多个 重复值的列,其索引效果最差。 使用短索引。如果对字符串列进行索引,应该指定一个前缀长度 。例如,如果有一个 CHAR(200) 列,如果在前 10 个或 20 个字符内,多数值是惟一的, 那么就不要对整个列进行索引。 利用最左前缀。每个额外的索 引都要占用额外的磁盘空间,并降低写操作的性能。 不要过度索引。 考虑在列上进行的比较类型。如果是在列上做函数运算,对其进行索引将毫无意义。
示例
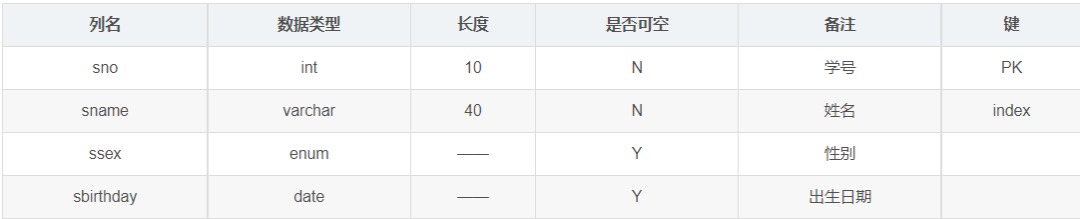


Student中姓名的长度是40,这里把外国人也考虑进来了;
Student中性别定义成枚举,主要是枚举意义简明;
Student中没有存年龄,而存储的出生日期,是因为年龄并不是一成不变的,并且能够通过出生日期正确计算。
SC中成绩使用的是double而不采用decimal,主要是因为成绩并不需要那么高的精确度。
SC中(sno,cno)作为联合主键而不是独立主键,由于现阶段markdown无法合拼行,所以无法编辑。

推荐



评论