
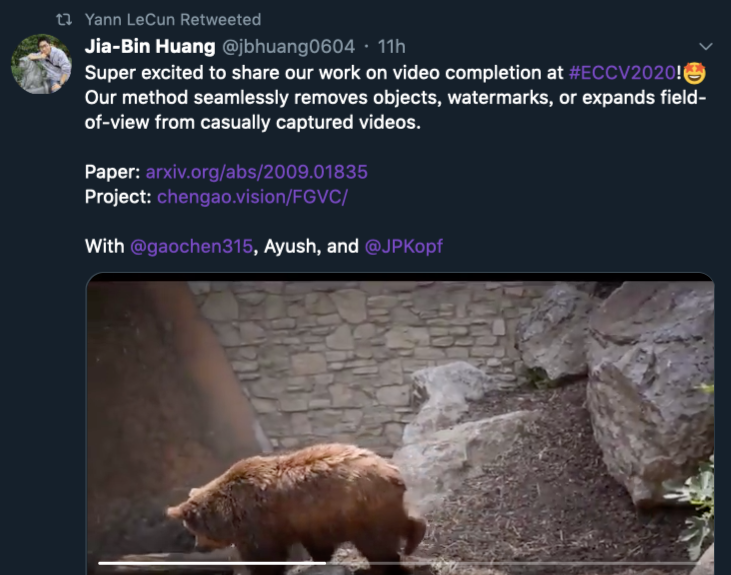
AI把视频里的你抹掉了!这个视频「橡皮擦」让你瞬间消失,头发丝都不留





论文链接:
https://arxiv.org/pdf/2009.01835.pdf
近来,基于学习的技术实现了更合理的合成效果。但是由于视频占用的内存较高,基于 3D 时空核的方法存在分辨率上的问题。迄今为止,最成功的方法是基于流的。
他们一起合成色彩和流,沿着流的轨迹传播颜色,以提升视频的时间连贯性。从而减轻内存占用问题并实现高分辨率输出。这项新研究也采用了这种通用方法。
使用基于流的方法获得良好结果的关键是准确的流补全,尤其是沿着目标边缘合成高度精确的流边缘。
但是,之前的方法都无法做到这一点,常会产生过度平滑的结果。尽管使用这种方法在背景平坦的情况下可以顺利地删除整个目标,但如果情况复杂一点,这些方法就会崩溃。
例如,现有的方法难以很好地补全部分可见的动态对象(图 1b–c)。值得注意的是,这种情况在补全静态屏幕空间掩码时经常发生。

研究者通过在一组非局部帧中引入额外的流约束来解决这个问题,这就创造了跨越流障碍的捷径,并将颜色传播到视频的更多部分。
以往基于流的方法是直接传递颜色值的,但受到光线变化、阴影、自动曝光、白平衡等因素的影响,颜色通常会随着时间的推移而产生微妙的改变。该方法通过也解决了这个问题。
1. 流边缘:通过显式地补全流边缘,研究者得到了分段平滑的流补全。
2. 非局部流:利用非局部流来补全无法通过可传递流(transitive flow)补全的区域;
3. 无缝融合:通过在梯度域中执行融合操作来避免可见的接缝;
4. 内存高效:研究者提出的方法可以处理 4k 分辨率的视频,而其他方法会因为 GPU 内存需求过大而失败。
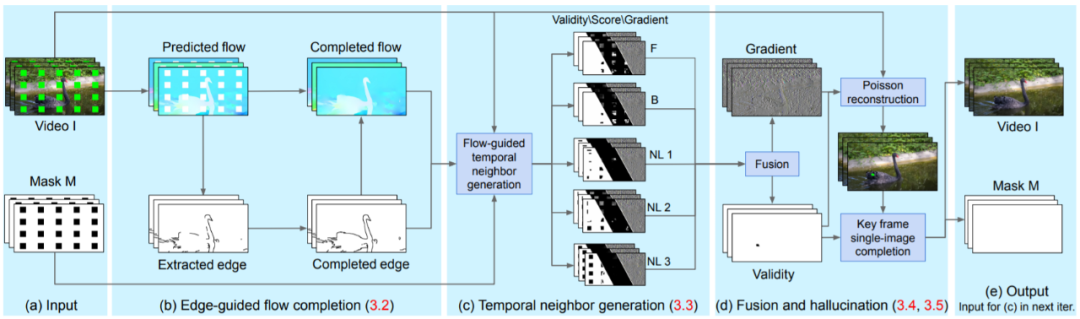
1. 流补全。研究者首先计算了相邻帧以及一组非相邻(non-local)帧之间的前向流和后向流,然后补全这些流场(flow field)的缺失区域。
由于边缘通常是流映射中最显著的特征,因此研究者首先提取并补全这些边缘。接下来,他们利用补全之后的边缘来生成分段平滑的流补全(见图 2b)。
2. 时间传播。接下来,研究者沿着流轨迹为每个缺失的像素传播一组候选像素。通过链接前向流向量和后向流向量,他们得到了两个候选像素,最后又得到一个已知的像素。
利用非局部流向量,通过对三个时间间隔较大的帧进行检验,研究者又得到了另外三个候选像素。他们为每一个候选像素估计了一个 confidence score 和一个二元有效性指标(见图 2c)。
如果经过这个过程之后还有缺失的像素,就意味着它们不能通过时间传播来填充(比如在整个视频中都被挡住的像素)。
为了解决这一问题,研究者选择了一个关键帧(包含大部分仍旧缺失的像素)并利用一种单张图像补全的技术来补全这些像素。他们利用得到的结果作为上述流程新一轮迭代的输入。
这种空间补全步骤保证他们在每次迭代中都取得进展,而且每一次得到的结果都会被传播到视频的其余部分,以便在下一个迭代中强制保持时间一致性。
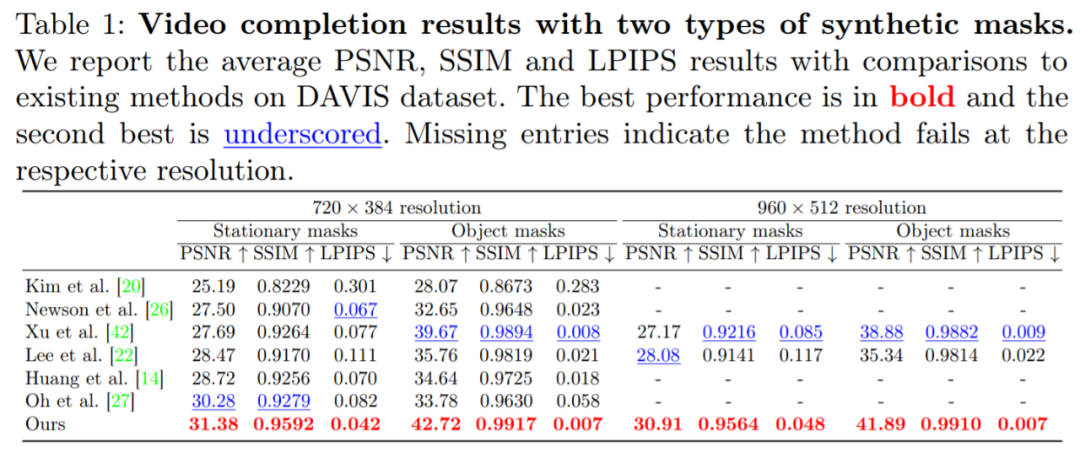
下表 1 展示了静态掩码图像补全方法和目标掩码图像补全方法在视频补全任务中的结果。
研究者所提出的方法在 3 项指标中都显著超越了之前的 SOTA 方法。

论文链接:
https://arxiv.org/pdf/2009.01835.pdf

2020-09-02
2020-08-31
2020-08-28