
图文详解 23 种设计模式
点击下方“IT牧场”,选择“设为星标”

面向接口编程,而不是面向实现。这个很重要,也是优雅的、可扩展的代码的第一步,这就不需要多说了吧。
职责单一原则。每个类都应该只有一个单一的功能,并且该功能应该由这个类完全封装起来。
对修改关闭,对扩展开放。对修改关闭是说,我们辛辛苦苦加班写出来的代码,该实现的功能和该修复的 bug 都完成了,别人可不能说改就改;对扩展开放就比较好理解了,也就是说在我们写好的代码基础上,很容易实现扩展。

public class FoodFactory {
public static Food makeFood(String name) {
if (name.equals("noodle")) {
Food noodle = new LanZhouNoodle();
noodle.addSpicy("more");
return noodle;
} else if (name.equals("chicken")) {
Food chicken = new HuangMenChicken();
chicken.addCondiment("potato");
return chicken;
} else {
return null;
}
}
}
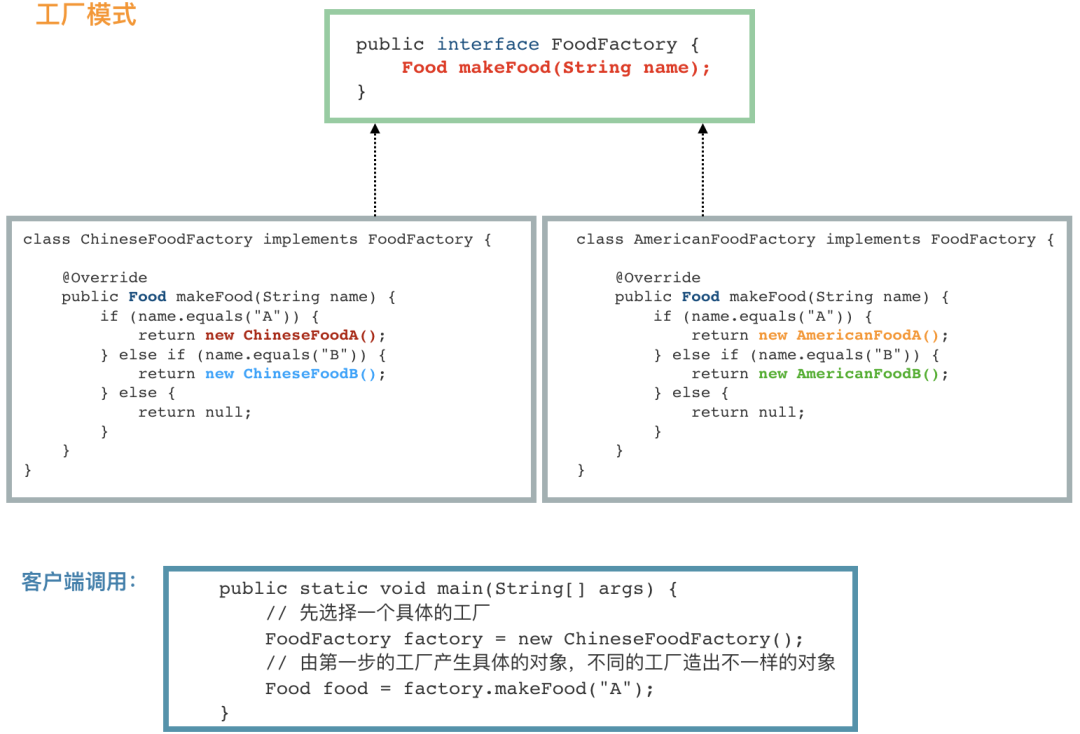
public interface FoodFactory {
Food makeFood(String name);
}
public class ChineseFoodFactory implements FoodFactory {
@Override
public Food makeFood(String name) {
if (name.equals("A")) {
return new ChineseFoodA();
} else if (name.equals("B")) {
return new ChineseFoodB();
} else {
return null;
}
}
}
public class AmericanFoodFactory implements FoodFactory {
@Override
public Food makeFood(String name) {
if (name.equals("A")) {
return new AmericanFoodA();
} else if (name.equals("B")) {
return new AmericanFoodB();
} else {
return null;
}
}
}
public class APP {
public static void main(String[] args) {
// 先选择一个具体的工厂
FoodFactory factory = new ChineseFoodFactory();
// 由第一步的工厂产生具体的对象,不同的工厂造出不一样的对象
Food food = factory.makeFood("A");
}
}
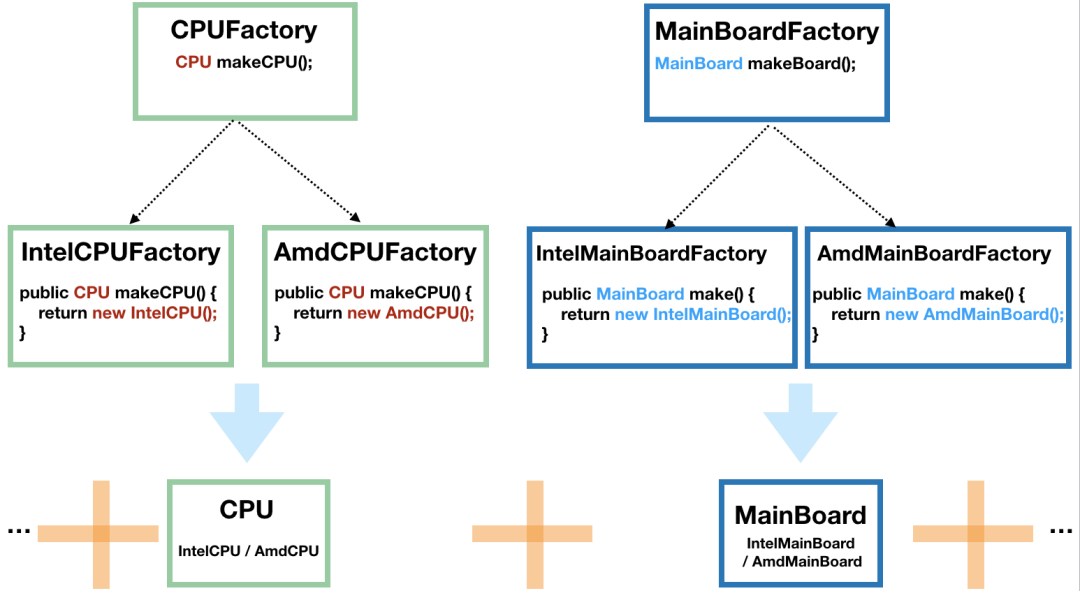
// 得到 Intel 的 CPU
CPUFactory cpuFactory = new IntelCPUFactory();
CPU cpu = intelCPUFactory.makeCPU();
// 得到 AMD 的主板
MainBoardFactory mainBoardFactory = new AmdMainBoardFactory();
MainBoard mainBoard = mainBoardFactory.make();
// 组装 CPU 和主板
Computer computer = new Computer(cpu, mainBoard);
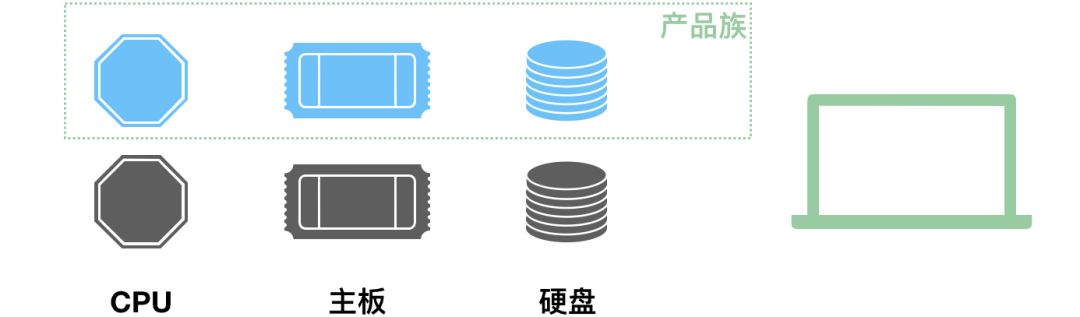
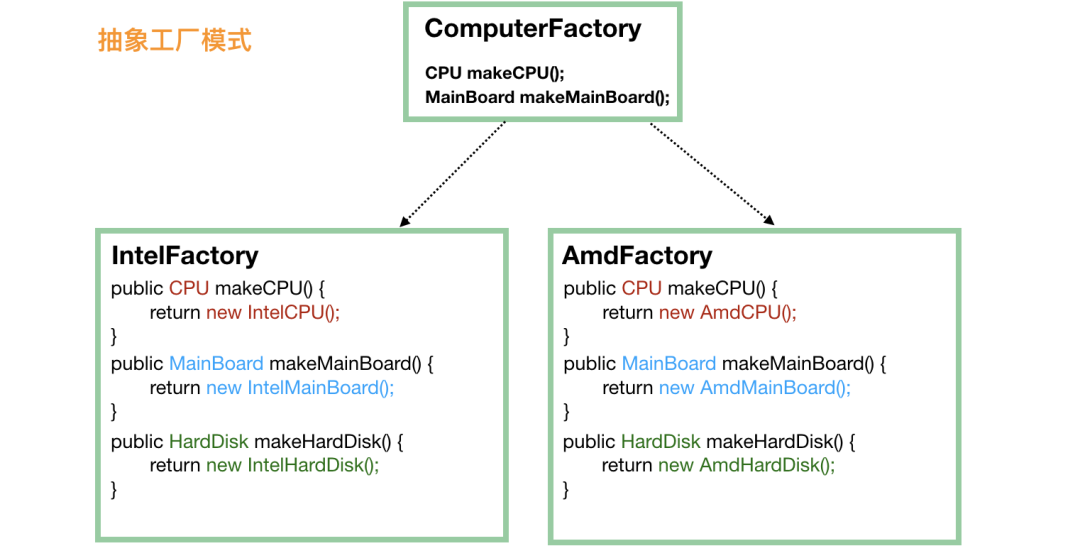
public static void main(String[] args) {
// 第一步就要选定一个“大厂”
ComputerFactory cf = new AmdFactory();
// 从这个大厂造 CPU
CPU cpu = cf.makeCPU();
// 从这个大厂造主板
MainBoard board = cf.makeMainBoard();
// 从这个大厂造硬盘
HardDisk hardDisk = cf.makeHardDisk();
// 将同一个厂子出来的 CPU、主板、硬盘组装在一起
Computer result = new Computer(cpu, board, hardDisk);
}
public class Singleton {
// 首先,将 new Singleton() 堵死
private Singleton() {};
// 创建私有静态实例,意味着这个类第一次使用的时候就会进行创建
private static Singleton instance = new Singleton();
public static Singleton getInstance() {
return instance;
}
// 瞎写一个静态方法。这里想说的是,如果我们只是要调用 Singleton.getDate(...),
// 本来是不想要生成 Singleton 实例的,不过没办法,已经生成了
public static Date getDate(String mode) {return new Date();}
}
public class Singleton {
// 首先,也是先堵死 new Singleton() 这条路
private Singleton() {}
// 和饿汉模式相比,这边不需要先实例化出来,注意这里的 volatile,它是必须的
private static volatile Singleton instance = null;
public static Singleton getInstance() {
if (instance == null) {
// 加锁
synchronized (Singleton.class) {
// 这一次判断也是必须的,不然会有并发问题
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
volatile 在这里是需要的,希望能引起读者的关注。
很多人不知道怎么写,直接就在 getInstance() 方法签名上加上 synchronized,这就不多说了,性能太差。
public class Singleton3 {
private Singleton3() {}
// 主要是使用了 嵌套类可以访问外部类的静态属性和静态方法 的特性
private static class Holder {
private static Singleton3 instance = new Singleton3();
}
public static Singleton3 getInstance() {
return Holder.instance;
}
}
Food food = new FoodBuilder().a().b().c().build();
Food food = Food.builder().a().b().c().build();
class User {
// 下面是“一堆”的属性
private String name;
private String password;
private String nickName;
private int age;
// 构造方法私有化,不然客户端就会直接调用构造方法了
private User(String name, String password, String nickName, int age) {
this.name = name;
this.password = password;
this.nickName = nickName;
this.age = age;
}
// 静态方法,用于生成一个 Builder,这个不一定要有,不过写这个方法是一个很好的习惯,
// 有些代码要求别人写 new User.UserBuilder().a()...build() 看上去就没那么好
public static UserBuilder builder() {
return new UserBuilder();
}
public static class UserBuilder {
// 下面是和 User 一模一样的一堆属性
private String name;
private String password;
private String nickName;
private int age;
private UserBuilder() {
}
// 链式调用设置各个属性值,返回 this,即 UserBuilder
public UserBuilder name(String name) {
this.name = name;
return this;
}
public UserBuilder password(String password) {
this.password = password;
return this;
}
public UserBuilder nickName(String nickName) {
this.nickName = nickName;
return this;
}
public UserBuilder age(int age) {
this.age = age;
return this;
}
// build() 方法负责将 UserBuilder 中设置好的属性“复制”到 User 中。
// 当然,可以在 “复制” 之前做点检验
public User build() {
if (name == null || password == null) {
throw new RuntimeException("用户名和密码必填");
}
if (age <= 0 || age >= 150) {
throw new RuntimeException("年龄不合法");
}
// 还可以做赋予”默认值“的功能
if (nickName == null) {
nickName = name;
}
return new User(name, password, nickName, age);
}
}
}
public class APP {
public static void main(String[] args) {
User d = User.builder()
.name("foo")
.password("pAss12345")
.age(25)
.build();
}
}
@Builder
class User {
private String name;
private String password;
private String nickName;
private int age;
}
User user = new User().setName("").setPassword("").setAge(20);
protected native Object clone() throws CloneNotSupportedException;
public interface FoodService {
Food makeChicken();
Food makeNoodle();
}
public class FoodServiceImpl implements FoodService {
public Food makeChicken() {
Food f = new Chicken()
f.setChicken("1kg");
f.setSpicy("1g");
f.setSalt("3g");
return f;
}
public Food makeNoodle() {
Food f = new Noodle();
f.setNoodle("500g");
f.setSalt("5g");
return f;
}
}
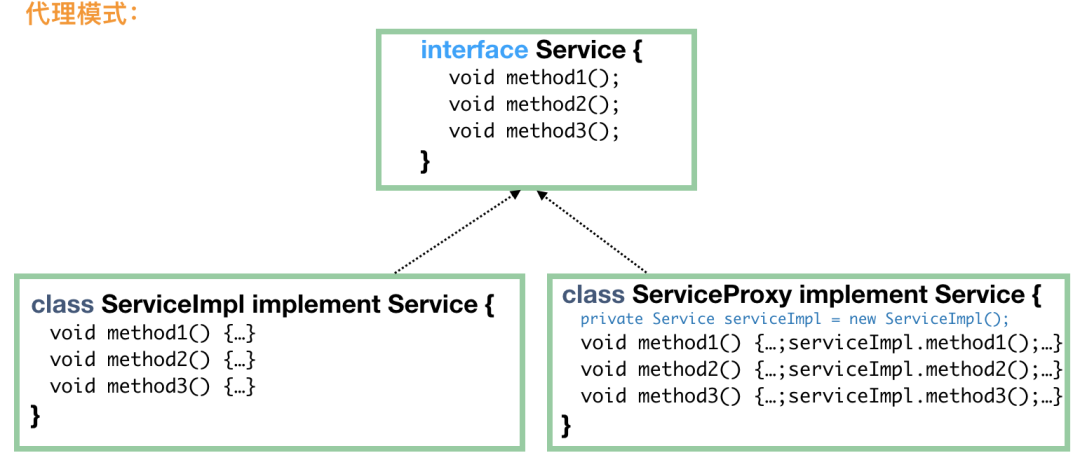
// 代理要表现得“就像是”真实实现类,所以需要实现 FoodService
public class FoodServiceProxy implements FoodService {
// 内部一定要有一个真实的实现类,当然也可以通过构造方法注入
private FoodService foodService = new FoodServiceImpl();
public Food makeChicken() {
System.out.println("我们马上要开始制作鸡肉了");
// 如果我们定义这句为核心代码的话,那么,核心代码是真实实现类做的,
// 代理只是在核心代码前后做些“无足轻重”的事情
Food food = foodService.makeChicken();
System.out.println("鸡肉制作完成啦,加点胡椒粉"); // 增强
food.addCondiment("pepper");
return food;
}
public Food makeNoodle() {
System.out.println("准备制作拉面~");
Food food = foodService.makeNoodle();
System.out.println("制作完成啦")
return food;
}
}
// 这里用代理类来实例化
FoodService foodService = new FoodServiceProxy();
foodService.makeChicken();
public interface FileAlterationListener {
void onStart(final FileAlterationObserver observer);
void onDirectoryCreate(final File directory);
void onDirectoryChange(final File directory);
void onDirectoryDelete(final File directory);
void onFileCreate(final File file);
void onFileChange(final File file);
void onFileDelete(final File file);
void onStop(final FileAlterationObserver observer);
}
public class FileAlterationListenerAdaptor implements FileAlterationListener {
public void onStart(final FileAlterationObserver observer) {
}
public void onDirectoryCreate(final File directory) {
}
public void onDirectoryChange(final File directory) {
}
public void onDirectoryDelete(final File directory) {
}
public void onFileCreate(final File file) {
}
public void onFileChange(final File file) {
}
public void onFileDelete(final File file) {
}
public void onStop(final FileAlterationObserver observer) {
}
}
public class FileMonitor extends FileAlterationListenerAdaptor {
public void onFileCreate(final File file) {
// 文件创建
doSomething();
}
public void onFileDelete(final File file) {
// 文件删除
doSomething();
}
}
public interface Duck {
public void quack(); // 鸭的呱呱叫
public void fly(); // 飞
}
public interface Cock {
public void gobble(); // 鸡的咕咕叫
public void fly(); // 飞
}
public class WildCock implements Cock {
public void gobble() {
System.out.println("咕咕叫");
}
public void fly() {
System.out.println("鸡也会飞哦");
}
}
// 毫无疑问,首先,这个适配器肯定需要 implements Duck,这样才能当做鸭来用
public class CockAdapter implements Duck {
Cock cock;
// 构造方法中需要一个鸡的实例,此类就是将这只鸡适配成鸭来用
public CockAdapter(Cock cock) {
this.cock = cock;
}
// 实现鸭的呱呱叫方法
@Override
public void quack() {
// 内部其实是一只鸡的咕咕叫
cock.gobble();
}
@Override
public void fly() {
cock.fly();
}
}
public static void main(String[] args) {
// 有一只野鸡
Cock wildCock = new WildCock();
// 成功将野鸡适配成鸭
Duck duck = new CockAdapter(wildCock);
...
}
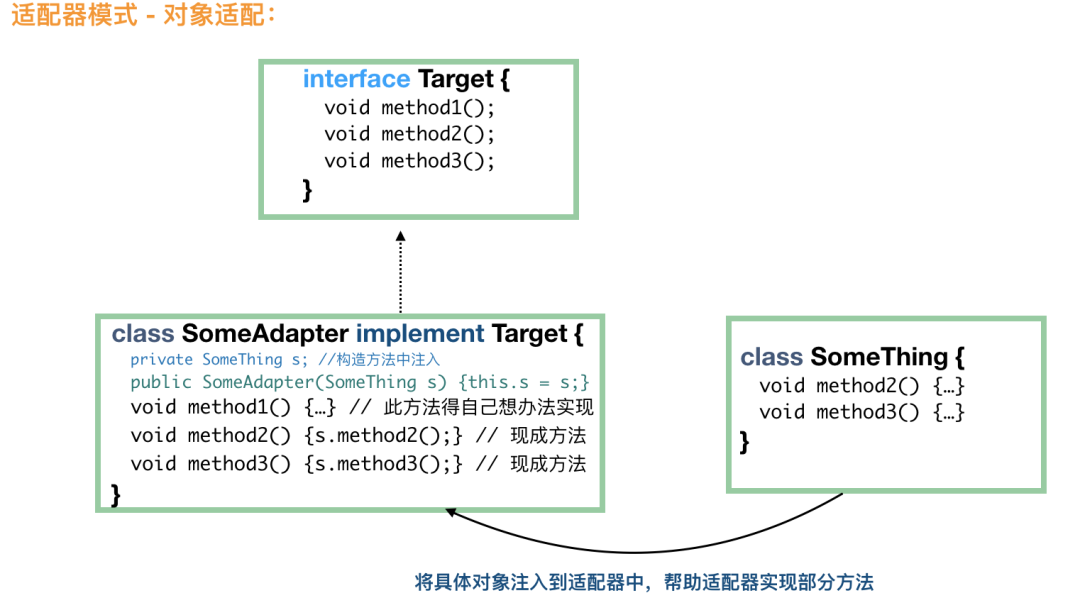
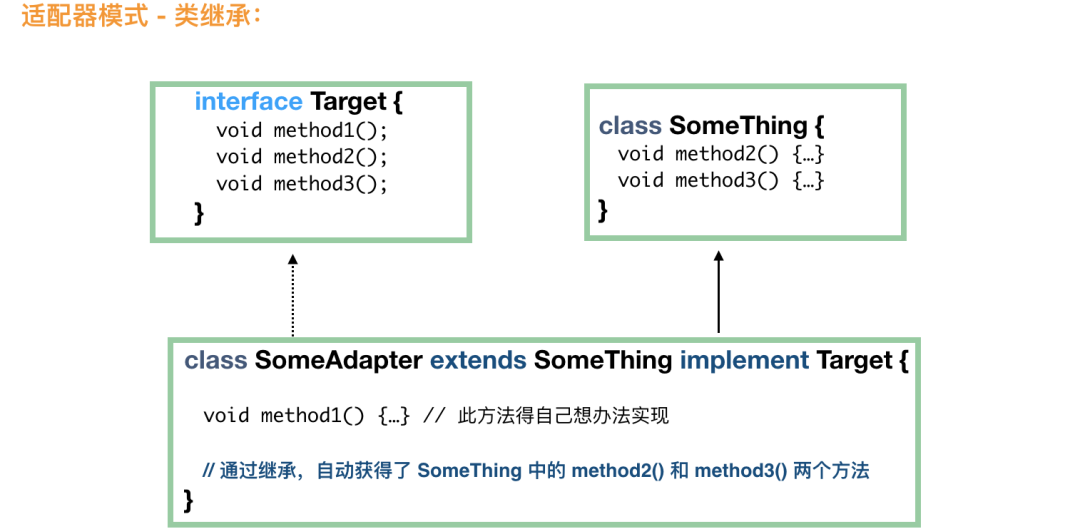
一个采用继承,一个采用组合;
类适配属于静态实现,对象适配属于组合的动态实现,对象适配需要多实例化一个对象;
总体来说,对象适配用得比较多。
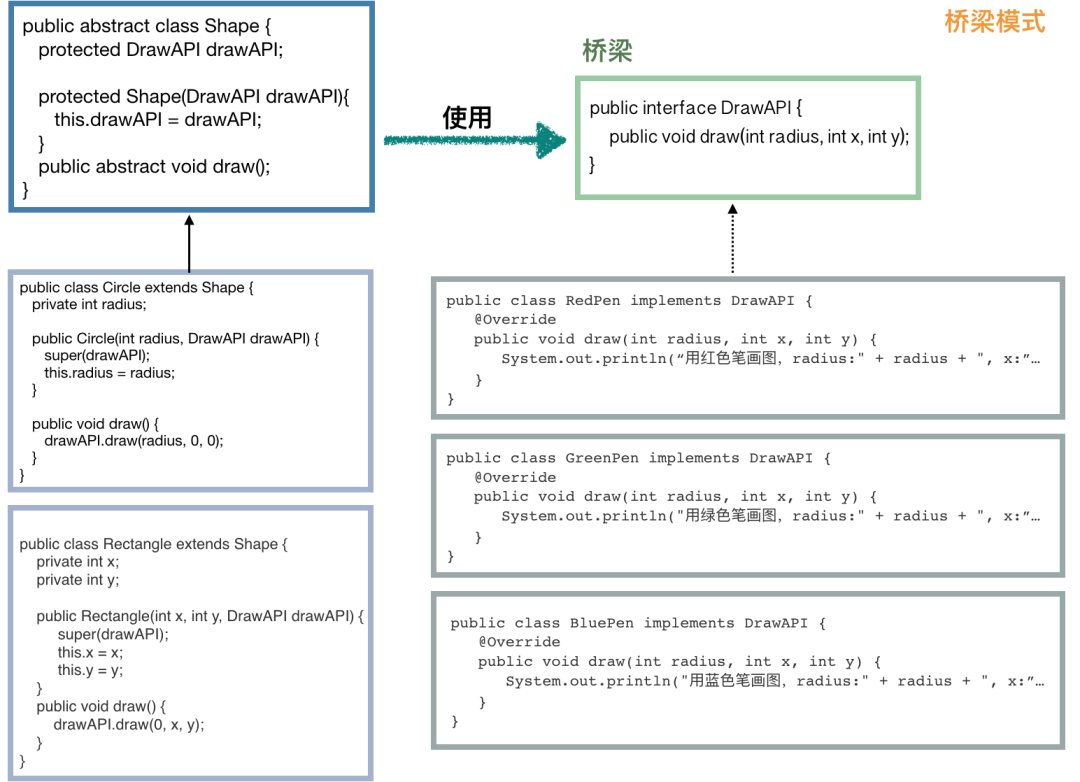
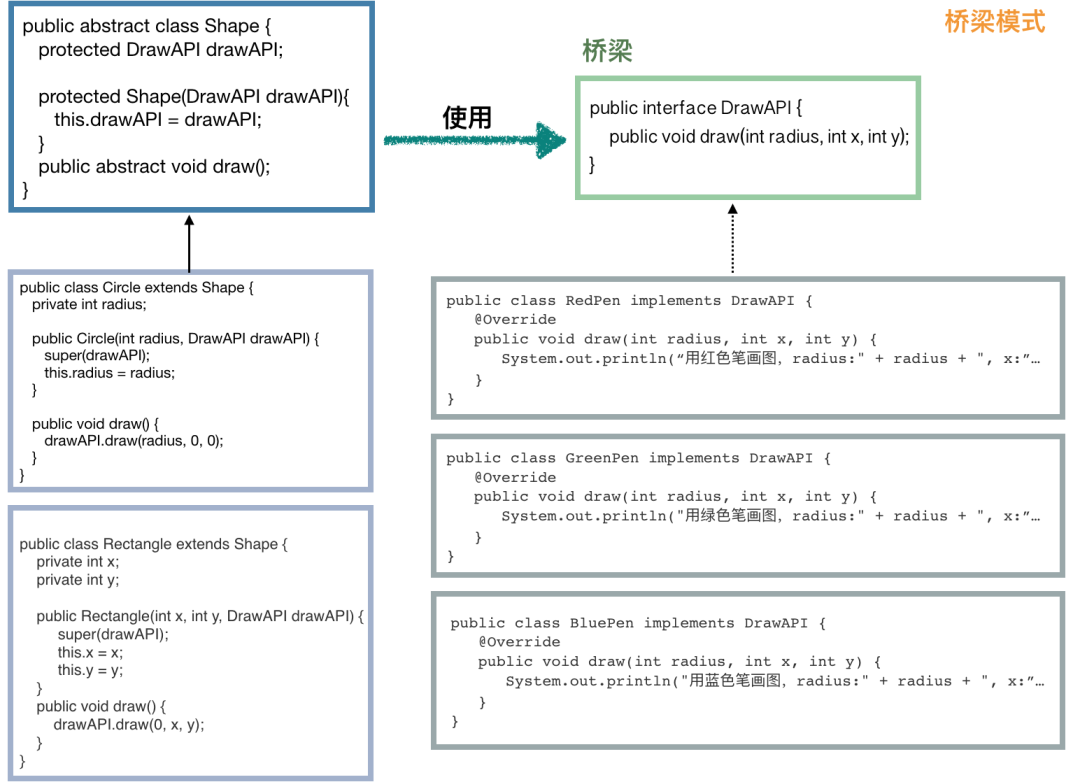
public interface DrawAPI {
public void draw(int radius, int x, int y);
}
public class RedPen implements DrawAPI {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用红色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
public class GreenPen implements DrawAPI {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用绿色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
public class BluePen implements DrawAPI {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用蓝色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
public abstract class Shape {
protected DrawAPI drawAPI;
protected Shape(DrawAPI drawAPI) {
this.drawAPI = drawAPI;
}
public abstract void draw();
}
// 圆形
public class Circle extends Shape {
private int radius;
public Circle(int radius, DrawAPI drawAPI) {
super(drawAPI);
this.radius = radius;
}
public void draw() {
drawAPI.draw(radius, 0, 0);
}
}
// 长方形
public class Rectangle extends Shape {
private int x;
private int y;
public Rectangle(int x, int y, DrawAPI drawAPI) {
super(drawAPI);
this.x = x;
this.y = y;
}
public void draw() {
drawAPI.draw(0, x, y);
}
}
public static void main(String[] args) {
Shape greenCircle = new Circle(10, new GreenPen());
Shape redRectangle = new Rectangle(4, 8, new RedPen());
greenCircle.draw();
redRectangle.draw();
}
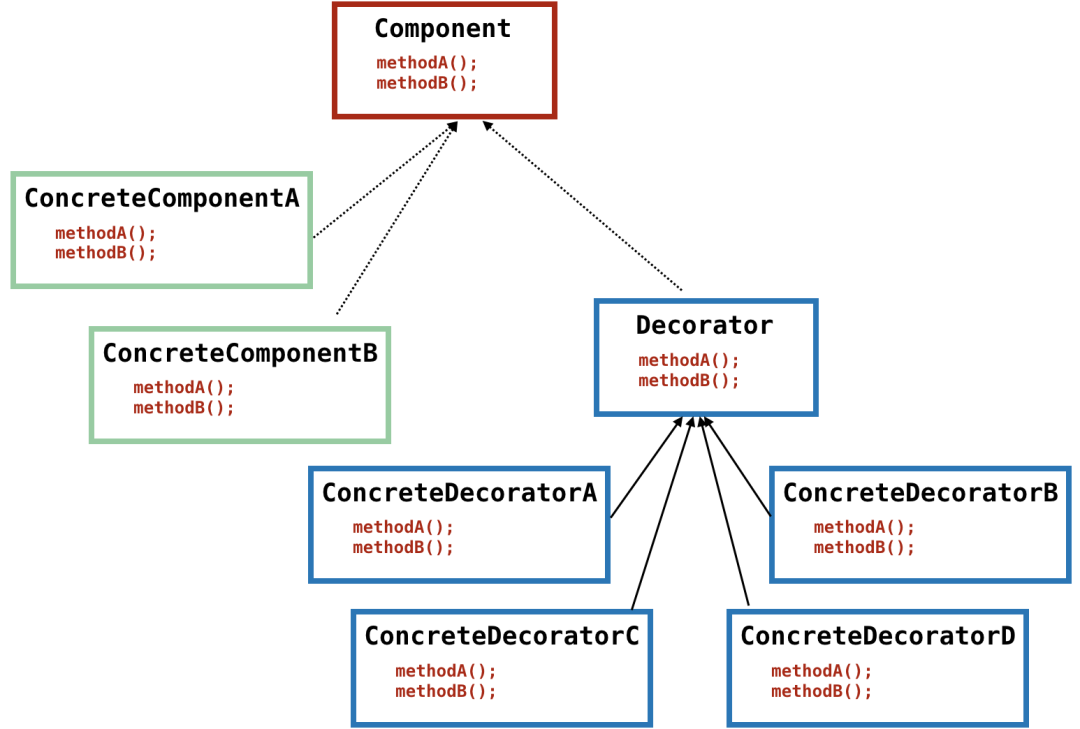
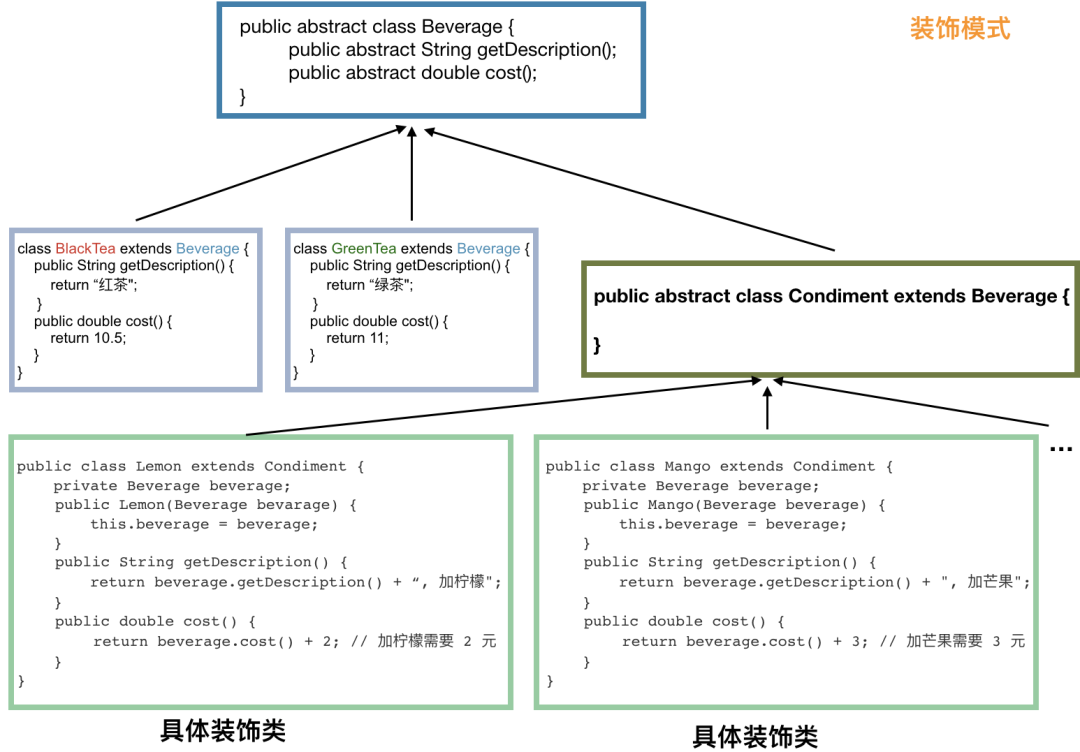
public abstract class Beverage {
// 返回描述
public abstract String getDescription();
// 返回价格
public abstract double cost();
}
public class BlackTea extends Beverage {
public String getDescription() {
return "红茶";
}
public double cost() {
return 10;
}
}
public class GreenTea extends Beverage {
public String getDescription() {
return "绿茶";
}
public double cost() {
return 11;
}
}
...// 咖啡省略
// 调料
public abstract class Condiment extends Beverage {
}
public class Lemon extends Condiment {
private Beverage bevarage;
// 这里很关键,需要传入具体的饮料,如需要传入没有被装饰的红茶或绿茶,
// 当然也可以传入已经装饰好的芒果绿茶,这样可以做芒果柠檬绿茶
public Lemon(Beverage bevarage) {
this.bevarage = bevarage;
}
public String getDescription() {
// 装饰
return bevarage.getDescription() + ", 加柠檬";
}
public double cost() {
// 装饰
return beverage.cost() + 2; // 加柠檬需要 2 元
}
}
public class Mango extends Condiment {
private Beverage bevarage;
public Mango(Beverage bevarage) {
this.bevarage = bevarage;
}
public String getDescription() {
return bevarage.getDescription() + ", 加芒果";
}
public double cost() {
return beverage.cost() + 3; // 加芒果需要 3 元
}
}
...// 给每一种调料都加一个类
public static void main(String[] args) {
// 首先,我们需要一个基础饮料,红茶、绿茶或咖啡
Beverage beverage = new GreenTea();
// 开始装饰
beverage = new Lemon(beverage); // 先加一份柠檬
beverage = new Mongo(beverage); // 再加一份芒果
System.out.println(beverage.getDescription() + " 价格:¥" + beverage.cost());
//"绿茶, 加柠檬, 加芒果 价格:¥16"
}
Beverage beverage = new Mongo(new Pearl(new Lemon(new Lemon(new BlackTea()))));
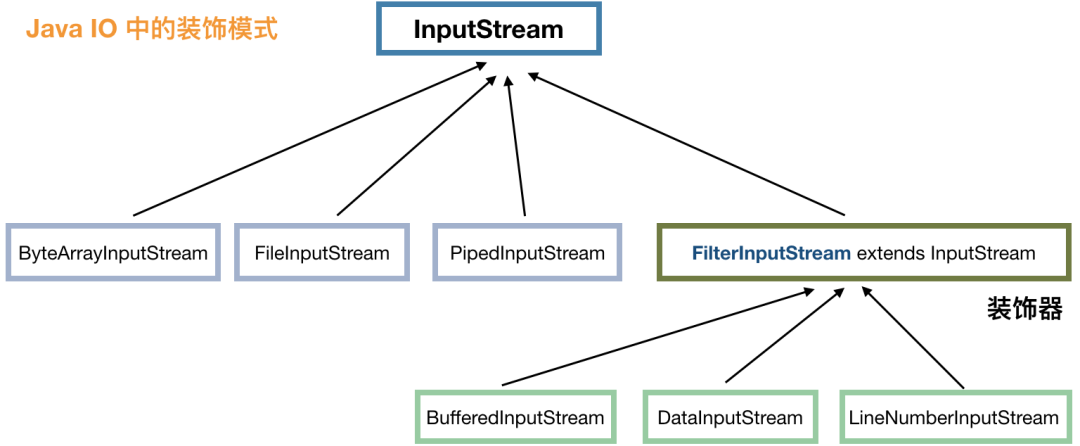
InputStream inputStream = new LineNumberInputStream(new BufferedInputStream(new FileInputStream("")));
DataInputStream is = new DataInputStream(
new BufferedInputStream(
new FileInputStream("")));
public interface Shape {
void draw();
}
public class Circle implements Shape {
@Override
public void draw() {
System.out.println("Circle::draw()");
}
}
public class Rectangle implements Shape {
@Override
public void draw() {
System.out.println("Rectangle::draw()");
}
}
public static void main(String[] args) {
// 画一个圆形
Shape circle = new Circle();
circle.draw();
// 画一个长方形
Shape rectangle = new Rectangle();
rectangle.draw();
}
public class ShapeMaker {
private Shape circle;
private Shape rectangle;
private Shape square;
public ShapeMaker() {
circle = new Circle();
rectangle = new Rectangle();
square = new Square();
}
/**
* 下面定义一堆方法,具体应该调用什么方法,由这个门面来决定
*/
public void drawCircle(){
circle.draw();
}
public void drawRectangle(){
rectangle.draw();
}
public void drawSquare(){
square.draw();
}
}
public static void main(String[] args) {
ShapeMaker shapeMaker = new ShapeMaker();
// 客户端调用现在更加清晰了
shapeMaker.drawCircle();
shapeMaker.drawRectangle();
shapeMaker.drawSquare();
}
public class Employee {
private String name;
private String dept;
private int salary;
private List<Employee> subordinates; // 下属
public Employee(String name,String dept, int sal) {
this.name = name;
this.dept = dept;
this.salary = sal;
subordinates = new ArrayList<Employee>();
}
public void add(Employee e) {
subordinates.add(e);
}
public void remove(Employee e) {
subordinates.remove(e);
}
public List<Employee> getSubordinates(){
return subordinates;
}
public String toString(){
return ("Employee :[ Name : " + name + ", dept : " + dept + ", salary :" + salary+" ]");
}
}
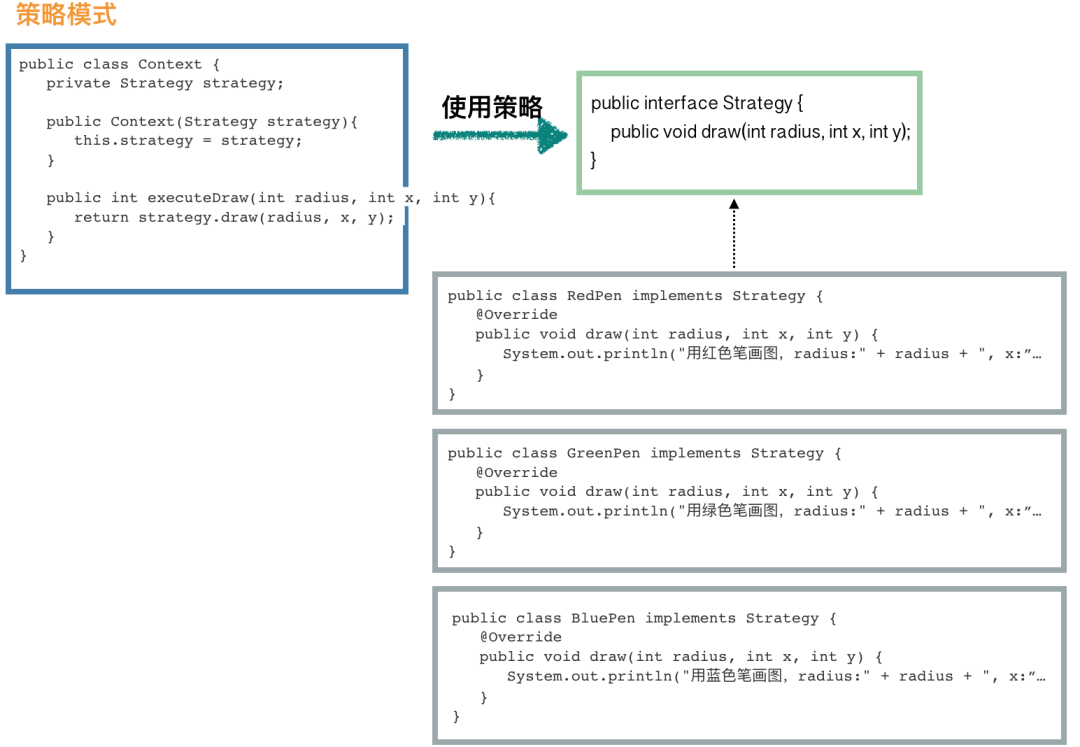
public interface Strategy {
public void draw(int radius, int x, int y);
}
public class RedPen implements Strategy {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用红色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
public class GreenPen implements Strategy {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用绿色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
public class BluePen implements Strategy {
@Override
public void draw(int radius, int x, int y) {
System.out.println("用蓝色笔画图,radius:" + radius + ", x:" + x + ", y:" + y);
}
}
public class Context {
private Strategy strategy;
public Context(Strategy strategy){
this.strategy = strategy;
}
public int executeDraw(int radius, int x, int y){
return strategy.draw(radius, x, y);
}
}
public static void main(String[] args) {
Context context = new Context(new BluePen()); // 使用绿色笔来画
context.executeDraw(10, 0, 0);
}
public class Subject {
private List<Observer> observers = new ArrayList<Observer>();
private int state;
public int getState() {
return state;
}
public void setState(int state) {
this.state = state;
// 数据已变更,通知观察者们
notifyAllObservers();
}
// 注册观察者
public void attach(Observer observer) {
observers.add(observer);
}
// 通知观察者们
public void notifyAllObservers() {
for (Observer observer : observers) {
observer.update();
}
}
}
public abstract class Observer {
protected Subject subject;
public abstract void update();
}
public class BinaryObserver extends Observer {
// 在构造方法中进行订阅主题
public BinaryObserver(Subject subject) {
this.subject = subject;
// 通常在构造方法中将 this 发布出去的操作一定要小心
this.subject.attach(this);
}
// 该方法由主题类在数据变更的时候进行调用
@Override
public void update() {
String result = Integer.toBinaryString(subject.getState());
System.out.println("订阅的数据发生变化,新的数据处理为二进制值为:" + result);
}
}
public class HexaObserver extends Observer {
public HexaObserver(Subject subject) {
this.subject = subject;
this.subject.attach(this);
}
@Override
public void update() {
String result = Integer.toHexString(subject.getState()).toUpperCase();
System.out.println("订阅的数据发生变化,新的数据处理为十六进制值为:" + result);
}
}
public static void main(String[] args) {
// 先定义一个主题
Subject subject1 = new Subject();
// 定义观察者
new BinaryObserver(subject1);
new HexaObserver(subject1);
// 模拟数据变更,这个时候,观察者们的 update 方法将会被调用
subject.setState(11);
}
订阅的数据发生变化,新的数据处理为二进制值为:1011
订阅的数据发生变化,新的数据处理为十六进制值为:B
public abstract class RuleHandler {
// 后继节点
protected RuleHandler successor;
public abstract void apply(Context context);
public void setSuccessor(RuleHandler successor) {
this.successor = successor;
}
public RuleHandler getSuccessor() {
return successor;
}
}
public class NewUserRuleHandler extends RuleHandler {
public void apply(Context context) {
if (context.isNewUser()) {
// 如果有后继节点的话,传递下去
if (this.getSuccessor() != null) {
this.getSuccessor().apply(context);
}
} else {
throw new RuntimeException("该活动仅限新用户参与");
}
}
}
public class LocationRuleHandler extends RuleHandler {
public void apply(Context context) {
boolean allowed = activityService.isSupportedLocation(context.getLocation);
if (allowed) {
if (this.getSuccessor() != null) {
this.getSuccessor().apply(context);
}
} else {
throw new RuntimeException("非常抱歉,您所在的地区无法参与本次活动");
}
}
}
public class LimitRuleHandler extends RuleHandler {
public void apply(Context context) {
int remainedTimes = activityService.queryRemainedTimes(context); // 查询剩余奖品
if (remainedTimes > 0) {
if (this.getSuccessor() != null) {
this.getSuccessor().apply(userInfo);
}
} else {
throw new RuntimeException("您来得太晚了,奖品被领完了");
}
}
}
public static void main(String[] args) {
RuleHandler newUserHandler = new NewUserRuleHandler();
RuleHandler locationHandler = new LocationRuleHandler();
RuleHandler limitHandler = new LimitRuleHandler();
// 假设本次活动仅校验地区和奖品数量,不校验新老用户
locationHandler.setSuccessor(limitHandler);
locationHandler.apply(context);
}
public abstract class AbstractTemplate {
// 这就是模板方法
public void templateMethod() {
init();
apply(); // 这个是重点
end(); // 可以作为钩子方法
}
protected void init() {
System.out.println("init 抽象层已经实现,子类也可以选择覆写");
}
// 留给子类实现
protected abstract void apply();
protected void end() {
}
}
public class ConcreteTemplate extends AbstractTemplate {
public void apply() {
System.out.println("子类实现抽象方法 apply");
}
public void end() {
System.out.println("我们可以把 method3 当做钩子方法来使用,需要的时候覆写就可以了");
}
}
public static void main(String[] args) {
AbstractTemplate t = new ConcreteTemplate();
// 调用模板方法
t.templateMethod();
}
public interface State {
public void doAction(Context context);
}
public class DeductState implements State {
public void doAction(Context context) {
System.out.println("商品卖出,准备减库存");
context.setState(this);
//... 执行减库存的具体操作
}
public String toString() {
return "Deduct State";
}
}
public class RevertState implements State {
public void doAction(Context context) {
System.out.println("给此商品补库存");
context.setState(this);
//... 执行加库存的具体操作
}
public String toString() {
return "Revert State";
}
}
public class Context {
private State state;
private String name;
public Context(String name) {
this.name = name;
}
public void setState(State state) {
this.state = state;
}
public void getState() {
return this.state;
}
}
public static void main(String[] args) {
// 我们需要操作的是 iPhone X
Context context = new Context("iPhone X");
// 看看怎么进行补库存操作
State revertState = new RevertState();
revertState.doAction(context);
// 同样的,减库存操作也非常简单
State deductState = new DeductState();
deductState.doAction(context);
// 如果需要我们可以获取当前的状态
// context.getState().toString();
}
干货分享
最近将个人学习笔记整理成册,使用PDF分享。关注我,回复如下代码,即可获得百度盘地址,无套路领取!
•001:《Java并发与高并发解决方案》学习笔记;•002:《深入JVM内核——原理、诊断与优化》学习笔记;•003:《Java面试宝典》•004:《Docker开源书》•005:《Kubernetes开源书》•006:《DDD速成(领域驱动设计速成)》•007:全部•008:加技术群讨论
加个关注不迷路
喜欢就点个"在看"呗^_^