
小样本文本数据分析
今后10年里,非结构化数据将占所有生产的互联网数据的90%。
互联网媒介发展日益瞩目,移动APP、博客、微信、论坛等媒体接踵而至,在悄无声息中改变了我们的生活方式。这些交互性强、容易沉淀价值信息的社交数据,往往包含着大量用户的基本信息和兴趣标签,是企业用来发掘商机、认知用户的绝好原料。
自然语言处理(NLP)是一种使计算机理解人类自然语言的技术和方法,将非结构化的语言文本转化为计算机能够处理的结构化信息,从而使之可以完成理解人类意图并与人类直接沟通的任务。

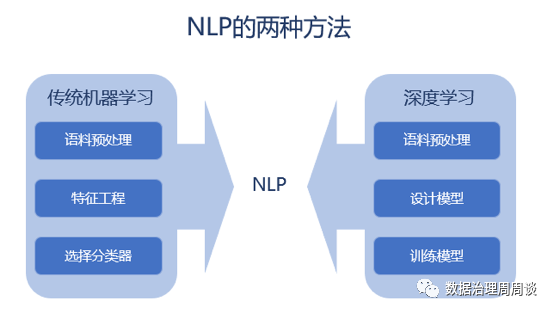
基于大数据的文本分析技术具有快速识别海量非结构化文本中的关键信息和关联,甚至实时监测舆情和传播趋势。但是在传统金融交互场景下,存在大量的对话或短语的形式的交互文本。由于现有语音转文本存在一定的误差,并且存在大量方言、语气词、口语化表述,而汉语又是典型的分析语(没有词性、时态等来辅助表达含义),因此在进行这类语义识别上往往需要依赖上下文或语境,采用传统的自然语言处理技术还远远不够。
小样本学习旨在通过少量样本学习到解决问题的模型。近年来,在大数据训练模型的趋势下,机器学习和深度学习在许多领域中取得突破性进展和较好的效果。一般来讲,深度学习的成功可以归结于三个关键因素:强大的计算资源(例如GPU)、复杂的神经网络(如CNN、LSTM)、大规模数据集。但许多现实的应用场景没有条件获取足够的带标签的训练样本,拥有从少量样本中学习和概括的能力,是将人工智能和人类智能进行区分的明显分界点,小样本学习能够帮助提升在短语或对话语义识别上性能和效果。
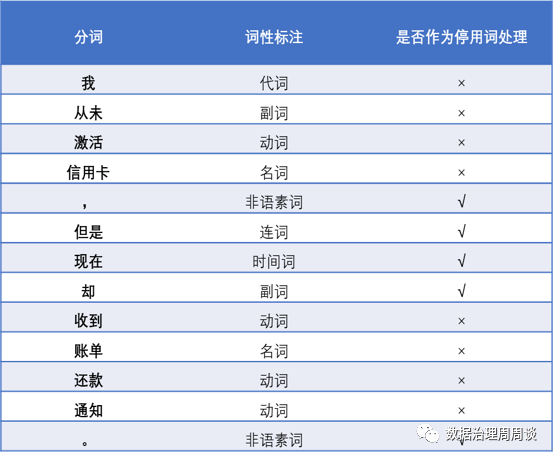
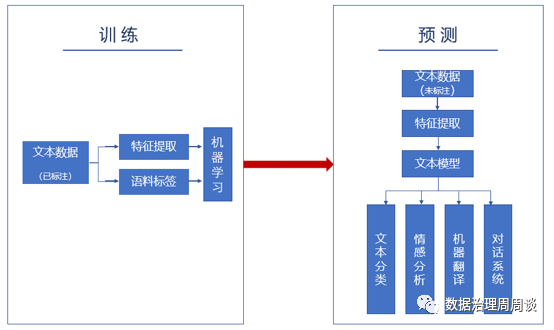 图3 文本分析流程
图3 文本分析流程
随着文本分析和挖掘技术的成熟,计算机可以更好、更快、更准的理解人类自然语言,存在着广阔的应用场景。
了解客户反馈:基于海量的非结构化信息,正确的理解用户散落在各渠道的声音,读懂用户的想法,挖掘出用户对于产品和服务的偏好以及随时间发展的变化情况。 客户关系管理:通过实时监测客户在使用产品、与服务人员和客户经理沟通记录、直接反馈信息的内容,挖掘出客户对于产品和服务的情绪和态度,是否存在负面或者投诉的倾向,结合客户旅程信息,捕获出在业务流程中存在的问题,不仅可以及时与客户沟通进行关系维护,还能够改善流程,优化客户体验。 舆情和口碑监测分析:通过大数据分析能够快速准确识别出企业及竞争对手在互联网上的热点信息和口碑变化,分析传播路径、传播节点、发展态势和受众反馈,为管理决策提供科学依据。 智能问答系统:从大量历史开放式问答记录中提取出有价值的、有共性的知识点,形成基于知识图谱的对话库。在智能客服和虚拟客服场景,能够高效准确地完成与客户的交流和沟通。
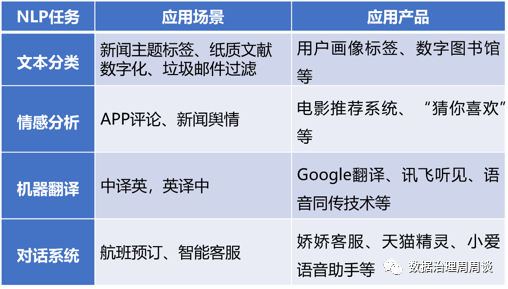
由随着人工智能在图像识别、语音识别领域的大放异彩,人们对其在自然语言分析上的能力也寄予厚望,并且逐步在多个应用领域崭露头角。虽然语言的本质使一些自然语言处理短期还不能有效地形式化,例如自动检测文本中的讽刺、反讽和隐含性的任务尚未得到有效解决,但是本文分析和挖掘技术将在商业实践中逐步体现出越来越大的商业价值。
(欢迎大家加入数据工匠知识星球获取更多资讯。)

扫描二维码关注我们

我们的使命:发展数据治理行业、普及数据治理知识、改变企业数据管理现状、提高企业数据质量、推动企业走进大数据时代。
我们的愿景:打造数据治理专家、数据治理平台、数据治理生态圈。
我们的价值观:凝聚行业力量、打造数据治理全链条平台、改变数据治理生态圈。
了解更多精彩内容
长按,识别二维码,关注我们吧!
数据工匠俱乐部
微信号:zgsjgjjlb
专注数据治理,推动大数据发展。