
为什么阿里巴巴规定超过3张表禁止JOIN?
点击上方“dotNET全栈开发”,“设为星标”
加“星标★”,每天21.45,好文必达

来源:http://blog.itpub.net/30393770/viewspace-2650450
一、 问题提出

二、问题分析
三、 实验环境
centos7内存4.5G,4核,50G硬盘。 mysql配置为2G,特别说明硬盘是SSD。
四、我概述下我的实验



五、下面两张表是测试结果
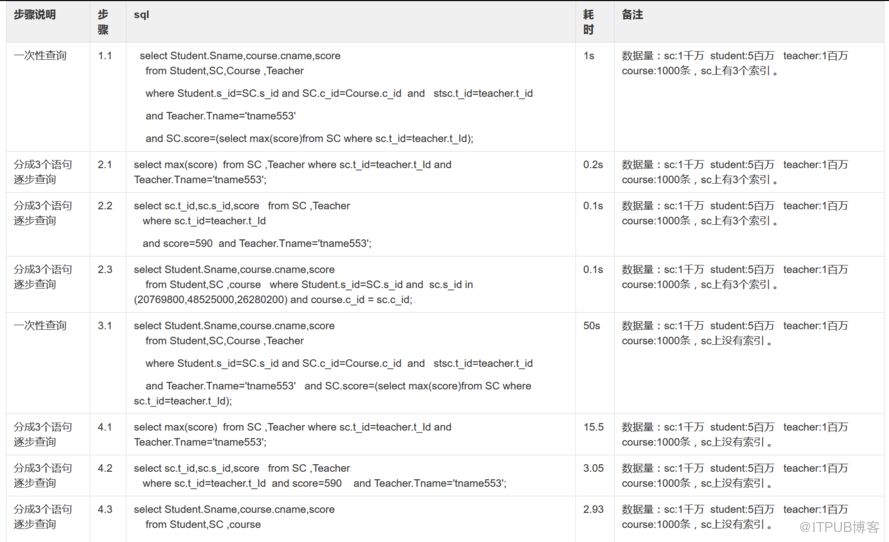
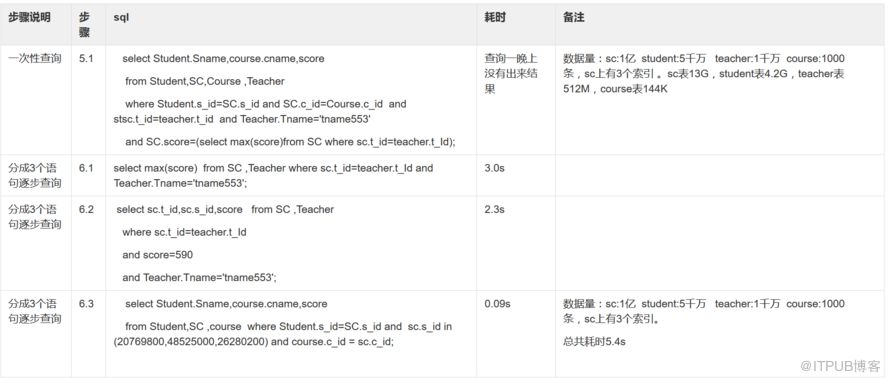
六、仔细看上表,可以发现:
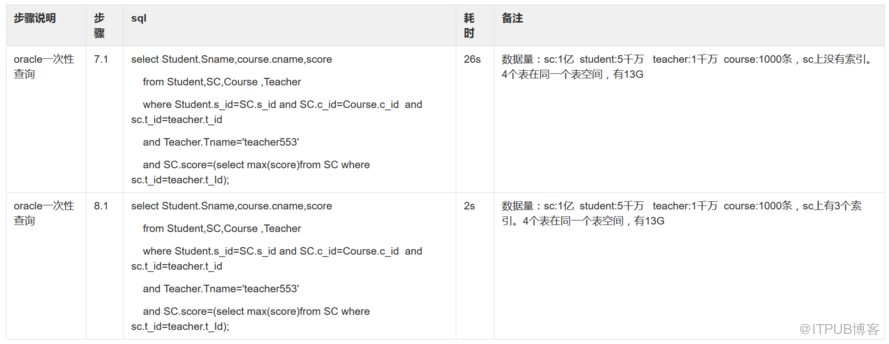
七、让我们来看看oracle数据库的优秀表现:
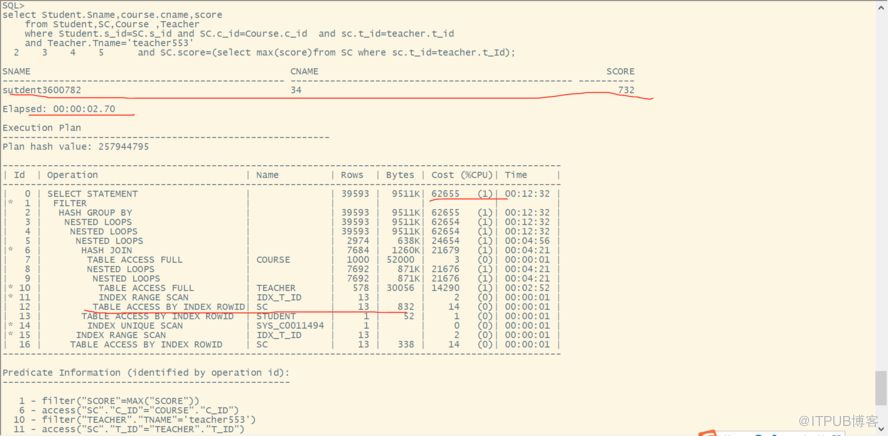
八、附上部分截图



九、附上sql语句和造数据脚本
use stu;
drop table if exists student;
create table student
( s_id int(11) not null auto_increment ,
sno int(11),
sname varchar(50),
sage int(11),
ssex varchar(8) ,
father_id int(11),
mather_id int(11),
note varchar(500),
primary key (s_id),
unique key uk_sno (sno)
) engine=innodb default charset=utf8mb4;
truncate table student;
delimiter $$
drop function if exists insert_student_data $$
create function insert_student_data()
returns int deterministic
begin
declare i int;
set i=1;
while i<50000000 do
insert into student values(i ,i, concat( name ,i),i,case when floor(rand()*10)%2=0 then f else m end,floor(rand()*100000),floor(rand()*1000000),concat( note ,i) );
set i=i+1;
end while;
return 1;
end$$
delimiter ;
select insert_student_data();
select count(*) from student;
use stu;
create table course
(
c_id int(11) not null auto_increment ,
cname varchar(50)
note varchar(500), primary key (c_id)
) engine=innodb default charset=utf8mb4;
truncate table course;
delimiter $$
drop function if exists insert_course_data $$
create function insert_course_data()
returns int deterministic
begin
declare i int;
set i=1;
while i<=1000 do
insert into course values(i , concat( course ,i),floor(rand()*1000),concat( note ,i) );
set i=i+1;
end while;
return 1;
end$$
delimiter ;
select insert_course_data();
select count(*) from course;
use stu;
drop table if exists sc;
create table sc
(
s_id int(11),
c_id int(11),
t_id int(11),
score int(11)
) engine=innodb default charset=utf8mb4;
truncate table sc;
delimiter $$
drop function if exists insert_sc_data $$
create function insert_sc_data()
returns int deterministic
begin
declare i int;
set i=1;
while i<=50000000 do
insert into sc values( i,floor(rand()*1000),floor(rand()*10000000),floor(rand()*750)) ;
set i=i+1;
end while;
return 1;
end$$
delimiter ;
select insert_sc_data();
commit;
select insert_sc_data();
commit;
create index idx_s_id on sc(s_id) ;
create index idx_t_id on sc(t_id) ;
create index idx_c_id on sc(c_id) ;
select count(*) from sc;
use stu;
drop table if exists teacher;
create table teacher
(
t_id int(11) not null auto_increment ,
tname varchar(50) ,
note varchar(500),primary key (t_id)
) engine=innodb default charset=utf8mb4;
truncate table teacher;
delimiter $$
drop function if exists insert_teacher_data $$
create function insert_teacher_data()
returns int deterministic
begin
declare i int;
set i=1;
while i<=10000000 do
insert into teacher values(i , concat( tname ,i),concat( note ,i) );
set i=i+1;
end while;
return 1;
end$$
delimiter ;
select insert_teacher_data();
commit;
select count(*) from teacher;
这个是oracle的测试和造数据脚本
create tablespace scott_data datafile /home/oracle/oracle_space/sitpay1/scott_data.dbf size 1024m autoextend on;
create tablespace scott_index datafile /home/oracle/oracle_space/sitpay1/scott_index.dbf size 64m autoextend on;
create temporary tablespace scott_temp tempfile /home/oracle/oracle_space/sitpay1/scott_temp.dbf size 64m autoextend on;
drop user scott cascade;
create user scott identified by tiger default tablespace scott_data temporary tablespace scott_temp ;
grant resource,connect,dba to scott;
drop table student;
create table student
( s_id number(11) ,
sno number(11) ,
sname varchar2(50),
sage number(11),
ssex varchar2(8) ,
father_id number(11),
mather_id number(11),
note varchar2(500)
) nologging;
truncate table student;
create or replace procedure insert_student_data
is
q number(11);
begin
q:=0;
for i in 1..50 loop
insert /*+append*/ into student select rownum+q as s_id,rownum+q as sno, concat( sutdent ,rownum+q ) as sname,floor(dbms_random.value(1,100)) as sage, f as ssex,rownum+q as father_id,rownum+q as mather_id,concat( note ,rownum+q ) as note from dual connect by level<=1000000;
q:=q+1000000;
commit;
end loop;
end insert_student_data;
/
call insert_student_data();
alter table student add constraint pk_student primary key (s_id);
commit;
select count(*) from student;
create table course
(
c_id number(11) primary key,
cname varchar2(50),
note varchar2(500)
) ;
truncate table course;
create or replace procedure insert_course_data
is
q number(11);
begin
for i in 1..1000 loop
insert /*+append*/ into course values(i , concat( name ,i),concat( note ,i) );
end loop;
end insert_course_data;
/
call insert_course_data();
commit;
select count(*) from course;
create table sc
(
s_id number(11),
c_id number(11),
t_id number(11),
score number(11)
) nologging;
truncate table sc;
create or replace procedure insert_sc_data
is
q number(11);
begin
q:=0;
for i in 1..50 loop
insert /*+append*/ into sc select rownum+q as s_id, floor(dbms_random.value(0,1000)) as c_id,floor(dbms_random.value(0,10000000)) t_id,floor(dbms_random.value(0,750)) as score from dual connect by level<=1000000;
q:=q+1000000;
commit;
end loop;
end insert_sc_data;
/
call insert_sc_data();
create index idx_s_id on sc(s_id) ;
create index idx_t_id on sc(t_id) ;
create index idx_c_id on sc(c_id) ;
select count(*) from sc;
create table teacher
(
t_id number(11) ,
tname varchar2(50) ,
note varchar2(500)
)nologging ;
truncate table teacher;
create or replace procedure insert_teacher_data
is
q number(11);
begin
q:=0;
for i in 1..10 loop
insert /*+append*/ into teacher select rownum+q as t_id, concat( teacher ,rownum+q ) as tname,concat( note ,rownum+q ) as note from dual connect by level<=1000000;
q:=q+1000000;
commit;
end loop;
end insert_teacher_data;
/
call insert_teacher_data();
alter table teacher add constraint pk_teacher primary key (t_id);
select count(*) from teacher;---END--
推荐阅读
微信后台回复“core”,获取全网最强.NET Core学习资料精选
回复“实战”,获取20套实战成品项目源码回复“进群”,可加入dotnet core开发者交流群
.NET Core已经崛起
长按关注,刷新认知
dotNet全栈开发
评论