
关于sgemm_hsw的一点解释说明
之前为了验证一个技术上的想法,随手写的一段汇编:
https://github.com/pigirons/sgemm_hsw/blob/master/sgemm_kernel_x64_fma.S
然后被朋友转到知乎上:
立交桥跳水冠军:大佬是怎么优雅实现矩阵乘法的?
这段汇编基本描述了这样一个寄存器分块的外积矩阵乘法:
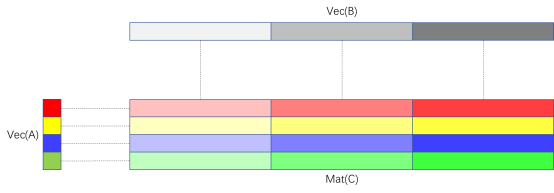
图中长矩形表示SIMD寄存器,方块表示标量。用一个4×3的寄存器分块来存储累加结果,然后从矩阵A里依次按列读取四个标量广播到向量寄存器的每个lane里,和矩阵B的三个行向量寄存器做乘法,累加到矩阵C的对应向量寄存器中。
根据我在github上给出的测试数据,这段代码只要控制矩阵三个维度(m,k,n)的大小使A,B,C三个矩阵都能放到L1
cache里,就可以达到十分接近理论峰值的性能。比如m = 24,k = 64,n = 24,在我的Zen2架构4750G上可以做到大于99%的浮点峰值性能。大家对于这个算法的点评得基本到位,但这里还是要补充几点:
关于使用的寄存器数量
大家讨论的一个点:这个程序恰好用满了AVX2指令的最多16个寄存器。但寄存器用了多少其实无关紧要,我这里只是恰好用到最大,可以支持FMA指令更长的延迟,更多的发射端口。
在我之前的文章里:
https://zhuanlan.zhihu.com/p/28226956
提到过FMA的吞吐和延迟的关系。以Intel
Haswell架构为例,FMA指令延迟是5个周期,每周期可以吞吐2条。这样为了掩盖所有FMA的执行周期,至少需要10条无数据依赖关系的FMA指令才能填满各级流水线。按照文章里面测试FMA峰值的代码,反映在时空图上就是这样的:
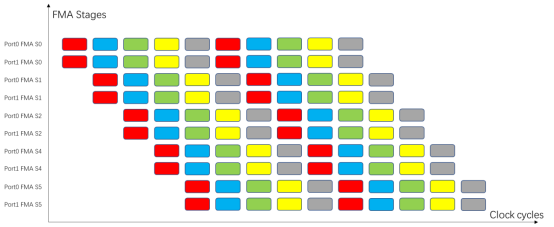
纵轴代表haswell架构port0和port1上各有一个FMA单元,每个FMA单元有五级流水线(S0->S5)。横轴代表时钟周期:第一个周期,最开始的两条fma指令(红色)同时分别发射到port0和port5,并执行流水线的第一阶段(S0);随着时钟的tick,这两条指令分别进入之后的流水阶段(S2到S5);从第二周期开始,再发射两条FMA指令(蓝色)到S0;以此类推,到第五个周期,最后两条指令开始发射(灰色),同时最开始的两条指令执行最后一个阶段(S5);第六个周期开始,循环也回到开头,继续发射两条红色的FMA指令,完美衔接,没有任何气泡。可以想象,只要程序足够长,两个FMA单元的10个流水线阶段(相当于计算资源)绝大部分时间都是有指令在执行的,除了开头进入流水线,和结尾结束流水线。
这个原理反应在寄存器分块上,就是存储累加结果的分块使用的寄存器数量,要大于等于10,才能保证中间的FMA指令没有停顿。我这里安排4×3=12这个分块,就没有问题。实际上,安排2×5或者5×2,都没有问题。这个情况最少用2×5+2+1=13个寄存器就可以打满峰值。对于后续的skylake等一系列新架构,FMA指令的延迟降低到4个周期,同时保持一个周期发射两条,那么在这种情况下,最少可以用2×4+2+1=11个寄存器就可以打满峰值了。我这里安排4×3=12,就是为了照顾各种不同架构FMA发射端口数量以及延迟可能有差别。
这同时引出了下一个问题:
向量读取指令和FMA指令的关系
既然寄存器分块只要保证10个以上的寄存器,那能不能用10×1的分块呢?我们回顾一下Intel Haswell架构图:
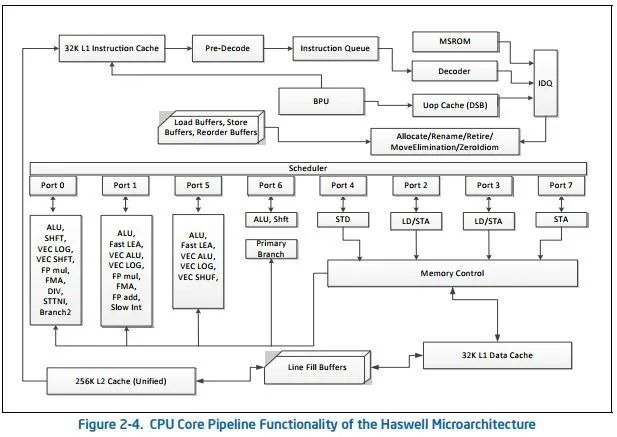
可以看出,除了Port0和Port1分别有一条FMA单元,Port2和Port3也分别有一条LD单元(Load),这个LD单元可以读取向量。我们假设所有的数据都在L1 cache里,LD指令就可以流水执行,大约是4个周期可以把一条向量读取到寄存器。这样,每个周期,Haswell
CPU就可以同时发射两条FMA以及两条vmovaps(或者vbroadcastss)指令。这就要求,总的Load指令数量最多跟FMA指令数量相等,一旦超过,FMA将不是瓶颈,LD指令将变成瓶颈。对于10×1的分块,我们需要10+1=11次LD才能喂给10条FMA指令,这样一定不能打满FMA的峰值;对于4×3的分块,我们需要4+3=7次LD就能喂给12条FMA指令,Haswell架构应对这个比例非常轻松。
对于不同的处理器,这个结论可以推广为:LD和FMA指令的比例,要小于等于处理器提供的LD和FMA单元同周期发射能力的比例。对于某些顺序单发射(比如某已流片的RISC-V)或者乱序发射能力有限(比如多数早期arm如a9,a15,a57)的架构,甚至要把这个比例在寄存器数量能支撑的范围内降到最低,这样就可以保证更多的周期是在发射FMA。其实对于m×n的寄存器分块,LD的数量一般就是m+n,所以尽量构造一个足够大的接近方形的分块,可以最大限度地利用FMA的峰值性能。
关于ymm15
可以看到程序里面对于矩阵B的三个向量的读取,分别用了三个寄存器(ymm12,ymm13和ymm14),但对于矩阵A的四个标量的读取,只用一个ymm15寄存器,这样不会有问题吗?我们拿出程序的一段结构观察:
vmovaps 0(%rbx), %ymm12
vmovaps 32(%rbx), %ymm13
vmovaps 64(%rbx), %ymm14
vbroadcastss 0(%r12, %rax, 4), %ymm15
vfmadd231ps %ymm12, %ymm15, %ymm0
vfmadd231ps %ymm13, %ymm15, %ymm1
vfmadd231ps %ymm14, %ymm15, %ymm2
vbroadcastss 0(%r13, %rax, 4), %ymm15
vfmadd231ps %ymm12, %ymm15, %ymm3
vfmadd231ps %ymm13, %ymm15, %ymm4
vfmadd231ps %ymm14, %ymm15, %ymm5
vbroadcastss 0(%r14, %rax, 4), %ymm15
vfmadd231ps %ymm12, %ymm15, %ymm6
vfmadd231ps %ymm13, %ymm15, %ymm7
vfmadd231ps %ymm14, %ymm15, %ymm8
vbroadcastss 0(%r15, %rax, 4), %ymm15
vfmadd231ps %ymm12, %ymm15, %ymm9
vfmadd231ps %ymm13, %ymm15, %ymm10
vfmadd231ps %ymm14, %ymm15, %ymm11
可以看到,第二条vbroadcastss指令要写入第二个标量给ymm15。从这个程序执行的性能结果分析,几乎每个周期都紧凑地有两条FMA发射出去,第二组三条FMA指令又依赖第二条vbroadcastss读取到的数据,所以这条广播指令一定被CPU乱序调度到第一组三条FMA指令更前面去了,因为LD指令本身需要4个周期。从程序逻辑来看,第一组三条FMA依赖的ymm15数据,是从第一条广播指令读取来的,但是第二条广播指令又会被调度到第一组三条FMA之前,这样数据不就乱套了吗?
其实不然,CPU有一个强大的register renamer部件,我们能操纵的ymm寄存器,只是逻辑寄存器,具体映射到实际的物理寄存器,是有一套复杂的转换规则。对于这个例子,CPU能分析出指令的数据流依赖关系,自动把第二组ymm15映射到与第一组ymm15不同的物理寄存器上,这样两组数据就毫无关系了,可以随意改变发射顺序,不影响结果的正确性。
这个技术部分地解决了逻辑寄存器不够用的问题。对于前面构造寄存器分块的分析,实际上m+n条LD指令,并不需要m+n个寄存器存储,只需要min(m,n)+1条寄存器就够了。这就增加了寄存器分块本身可以利用的寄存器的数量,构造更大的分块,进一步减少LD和FMA的比例。
这就是sgemm_hsw这个程序里面构造4×3寄存器分块暗含的三个玄机,一环套一环,虽然有其他的分块方案仍然能做到接近的峰值,但这个方案对不同x86架构的鲁棒性更好,适用范围更广。这些参数不是恰巧凑出来的,都是一步步精细算出来的,希望这篇文章对大家有所帮助。
最后强调一点,这还只是在L1
cache里的矩阵乘法分块,真正想优化任意大小的矩阵乘法,还有很多工作要做,比如CPU的prefetch机制,多级cache的性能特性,TLB miss的处理,多核多线程的任务分配调度等,这些技术大家去参考Goto的经典论文即可。
- The End -
长按二维码关注我们
本公众号专注:
1. 技术分享;
2. 学术交流;
3. 资料共享。
欢迎关注我们,一起成长!