
Pandas 计算连续行为天数的几种思路
大家好,我是才哥。
最近在处理数据的时候遇到一个需求,核心就是求取最大连续行为天数。类似需求在去年笔者刚接触 pandas 的时候也做过《利用Python统计连续登录N天或以上用户》,这里可以用同样的方法进行实现。
这里用北京空气质量数据作为案例进行演示,需求是找出北京空气质量连续污染最长持续多久并确定其周期。
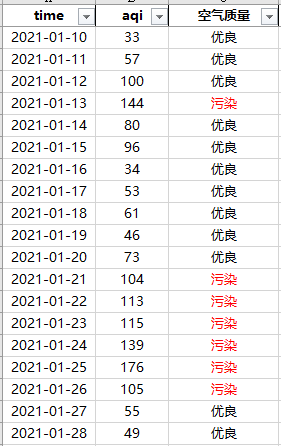
以上图中数据来算,可以看到从1月21日-1月26日空气质量连续污染持续了6天。
不过,在实际的数据处理中,原始数据往往会较大,并不一定能直接看出来。接下来,介绍几种解决方案供大家参考。
1. 获取案例数据
大家可以通过以下方式获取案例数据。
import akshare as ak
air_quality_hist_df = ak.air_quality_hist(city="北京", period="day", start_date="2021-01-01", end_date="2021-04-26")
air_quality_hist_df.head()
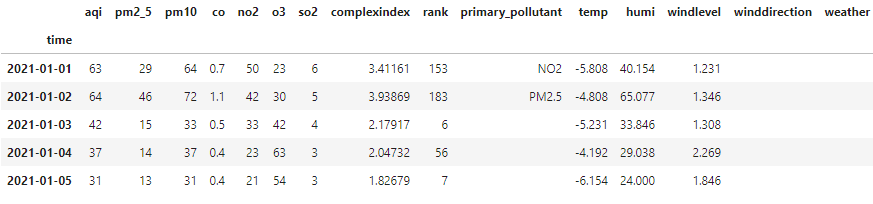
由于只需要用到aqi,并按照国际标准进行优良与污染定级,这里简单做下数据处理如下:
import pandas as pd
# 重置索引
aqi = air_quality_hist_df['aqi'].reset_index()
# 将aqi列改为int类型
aqi.aqi = aqi.aqi.astype('int')
# 使用分箱进行空气质量定级
aqi['空气质量'] = pd.cut(aqi.aqi,
bins=[0,100,500],
labels=['优良','污染'])
# 取10个样本预览
aqi.sample(10)
2. 求连续污染持续天数
结合上次的《利用Python统计连续登录N天或以上用户》案例,本文再提供1种新的解题思路,合计2种解题思路。
2.1. 思路1:按时间排序求差值再分组计数
才哥上次的解法就是这种思路,回看当初的代码显得比较稚嫩,今天我们看看小明哥的解法,非常精彩。
步骤1:筛选空气质量为污染的数据
t = aqi.query('空气质量=="污染"')
t.sample(5)
步骤2:新增辅助列(辅助列可以不用加到原数据t上)
这里的逻辑大概如下:
辅助排名列(按照时间顺序排序)为间隔天数 然后用时间字段(time)与间隔天数求差值得到一个日期 如果得到的这个日期相同,则这几天是连续污染天
groupids = pd.to_datetime(aqi.time)-pd.to_timedelta(aqi.time.rank(),unit='d')
groupids.sample(5)

步骤3:分组计数获得连续天数,分组求最小最大值获得连续 污染起止日期
t.groupby(groupids).agg({
'time': lambda x:f'{x.min()}~{x.max()}', # 求起止日期
'空气质量':"count", # 求连续天数
}).nlargest(5,'空气质量') # 取 空气质量 字段最大的前5组数据

以上完整代码如下:
t = aqi.query('空气质量=="污染"')
t.groupby(
pd.to_datetime(t.time)-pd.to_timedelta(t.time.rank(),unit='d')
).agg(
{
'time': lambda x:f'{x.min()}~{x.max()}',
'空气质量':"count",
}
).nlargest(5,'空气质量')
2.2. 思路2:比对相邻两天空气质量标记
思路2有两种解法,其一是利用循环创建辅助列,其二是利用shift和cumsum创建辅助列,具体我们可以往下看。
解法1:利用循环创建辅助列
创建一个辅助列,辅助列的值按照以下思路创建函数获取 如果空气质量为优良,则辅助列值+1;若当前空气质量和上一日不同,则辅助列值也+1 以上均不满足,则辅助列值不变
last = None
num = 0
groupids = []
for v in aqi.空气质量.values:
if v != last or v != '污染':
num += 1
groupids.append(num)
last = v
根据这个逻辑可以得到辅助列数据如下:
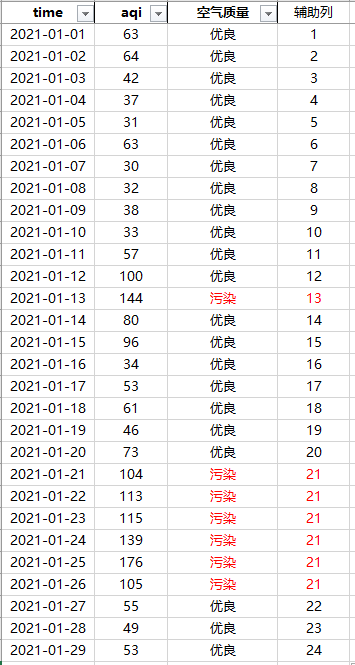
可以发现,按照辅助列分组进行计数即可获得连续污染天数,如上红色标记区域。
aqi.groupby(groupids).agg(
{
'time': lambda x:f'{x.min()}~{x.max()}',
'空气质量':"count",
}
).nlargest(5,'空气质量')
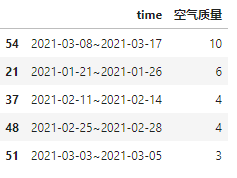
解法2:利用shift和cumsum创建辅助列
先创建空气质量的shift列,下移动一位 如果shift列和空气质量列相等,则判断列为0,否则为1 辅助列为判断列累加求和
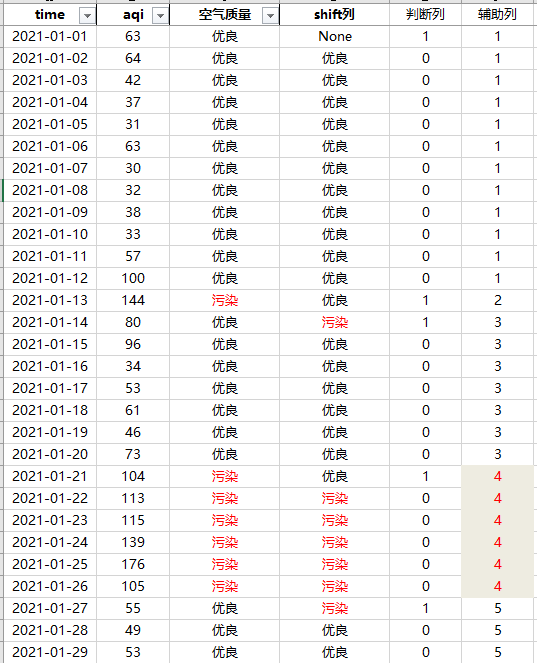
我们也可以发现,按照辅助列分组计数即可获取空气质量连续天数(优良和污染均可),如上红色区域。
(
aqi.query('空气质量=="污染"') # 这里筛选 污染 天气
.groupby((aqi.空气质量.shift() != aqi.空气质量).cumsum()) # 辅助列
.time.agg(['count','min','max']) # 计数及获取日期区间
.nlargest(5,'count')
)

按照小明哥的输出结果,调整代码如下:
(aqi.query("空气质量=='污染'").groupby((aqi.空气质量 != aqi.空气质量.shift()).cumsum()).agg({'time': lambda x: f"{x.min()}~{x.max()}",'空气质量': "count"}).nlargest(5, '空气质量'))

以上就是本次全部内容,其实我们在日常工作生活中还可能遇到类似场景如:计算用户连续登录天数、计算用户连续付费天数、计算南方梅雨季节连续下雨天数等等!