
【小妙招】如何借助Proxy代理,提升架构扩展性
我们都知道HTTP协议本身是无状态的,前后两次请求没有直接关联。
但有些业务功能比较特殊,比如发起一次http请求创建一笔订单,前提要求用户先登录,为了解决这个问题,http协议header中引入了Cookie,存储上下文信息,传递登录状态。
同理,服务器也有状态之分,取决于服务器是否有存储数据,还是纯计算节点
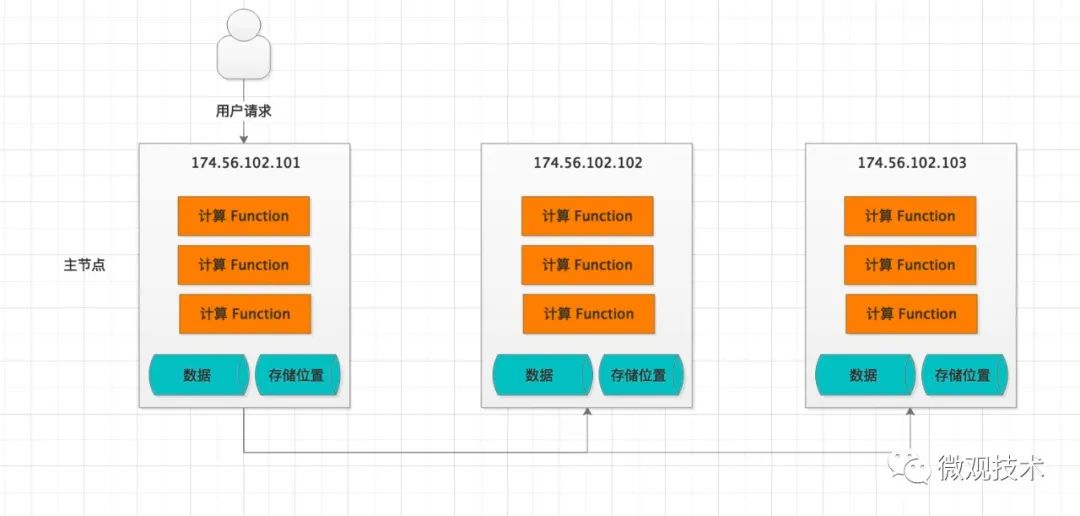
场景:
现在有这么一个业务场景,用户发出请求,指令随机打到了一台服务器,比如174.56.102.101,但根据索引条件,数据实际存储在 174.56.102.102 或者 174.56.102.103,此时174.56.102.101 需要将请求转发给真实的目标服务器,以便获取数据。
当然也有一定概率,174.56.102.101就是真实的数据存储服务器,此时只需要调用本地方法,直接获取数据即可。
思考:
那么问题来了,一个系统会提供很多功能函数,每个函数在执行时,都要先判断数据的真实存储位置,然后再发起远程网络请求,获取数据。这样编写存在大量的代码冗余。
有没有一种方式,只管调用对应的funcion函数,至于底层真实数据在哪里,由框架层来处理。
我们想到了RPC框架,比如 Dubbo,对于开发者而言,调用一个远程服务跟调用本地方法一样,简单方便。

如何来设计这个框架层
从大的角色划分来看,分为服务提供方和消费方,首先我们来看看消费方如何设计?
消费方
定义注解类 @RPCReference,作为Field字段的属性说明,如果有此标识说明注入的是一个代理类。
@Service
@Slf4j
public class ComputeService {
@RPCReference
private IResourceService iResourceService;
省略。。。。
public Object method(param){
// 正常方法调用
iResourceService.m1();
}
特别说明:
1、IResourceService 需要定义为接口类型
2、根据Spring的IOC注入机制,
iResourceService指向的是一个代理类实例地址
那么这个代理类如何创建?
首先,定义一个增强类 ConsumerProxyFactory,实现InvocationHandler接口
@Slf4j
public class ConsumerProxyFactory implements InvocationHandler {
/**
* 复写InvocationHandler类提供的方法,业务类方法调用会触发执行invoke增强逻辑
*/
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
Class<?> clazz = proxy.getClass().getInterfaces()[0];
if (method.getName().contains("toString")) {
return Boolean.TRUE;
}
// 根据args参数做判断
if (当前节点) {
// 调用本地方法
return invodeMethod(clazz, method, args);
}
// 否则走rpc远程调用
// 构造请求体
RPCRequest req = buildRpcReq(clazz, method, args);
// 构造请求头
Map<String, String> headerMap = buildHeaderMap( requestString);
// 访问远程服务器的接口,查询结果
String responseString = HttpClientUtil.postRequest(url, req, headerMap);
// 本地ThreadLocal资源清理、释放
// 反序列化,解析出Return对象
return JSONObject.parseObject(responseString, method.getGenericReturnType());
}
/**
* 执行当前节点的本地方法
*/
private Object invodeMethod(Class<?> clazz, Method method, Object[] args) {
try {
// 根据Class模板查询Bean实例
Object bean =ProviderContext.getProviders(clazz);
if (Void.TYPE.equals(method.getReturnType())) {
method.invoke(bean, args);
return null;
}
Object result = method.invoke(bean, args);
return result;
} catch (Exception e) {
return e.getMessage();
}
}
// 构造请求体
private RPCRequest buildRpcReq(Class<?> clazz, Method method, Object[] args) {
Class<?>[] parameterTypes = method.getParameterTypes();
String[] parameterTypeNames = Arrays.stream(parameterTypes).map(Class::getName).toArray(String[]::new);
Type[] listParameterType = method.getGenericParameterTypes();
String[] listParameterTypeNames = Arrays.stream(listParameterType).map(Type::getTypeName).toArray(String[]::new);
RPCRequest req = new RPCRequest();
req.setClazz(clazz);
req.setMethodName(method.getName());
req.setParameterTypeNames(parameterTypeNames);
req.setListParameterTypeNames(listParameterTypeNames);
req.setArguments(args);
req.setTt(System.currentTimeMillis());
省略一些业务参数。。
return req;
}
}
代理类又是如何注入的呢?
@Component
@Slf4j
public class RPCReferenceBeanPostProcessor implements BeanPostProcessor, ApplicationContextAware {
private ApplicationContext applicationContext;
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
// spring容器初始化时,拦截每一个Bean创建
Class<?> beanClass = bean.getClass();
do {
// 获取Bean实例下的所有全局变量Field
Field[] fields = beanClass.getDeclaredFields();
for (Field field : fields) {
// 判断是否有@RPCReference注解描述
if (!hasAnnotation(field.getAnnotations(), RPCReference.class.getName())) {
continue;
}
// 通过反射,为field属性填充Proxy代理类实例
setField(bean, field);
}
} while ((beanClass = beanClass.getSuperclass()) != null);
return bean;
}
private void setField(Object bean, Field field) {
if (!field.isAccessible()) {
field.setAccessible(true);
}
try {
// Field是接口类型
if (field.getType().isInterface()) {
Class<?> interfaceClass = field.getType();
// 创建代理类
Object object = Proxy.newProxyInstance(interfaceClass.getClassLoader(), new Class[]{interfaceClass}, new ConsumerProxyFactory());
// 代理类注入
field.set(bean, object);
} else {
throw new RPCException("10000", field.getType().getName() + "-Referenc only suiteable for interface");
}
} catch (Exception e) {
}
}
private boolean hasAnnotation(Annotation[] annotations, String annotationName) {
for (Annotation annotation : annotations) {
if (annotation.annotationType().getName().equals(annotationName)) {
return true;
}
}
return false;
}
}
此处主要借助Spring提供的扩展类,ApplicationContextAware、BeanPostProcessor。
ApplicationContextAware,通过这个上下文环境可以查看、管理 Spring 容器中的Bean。
BeanPostProcessor,如果我们想在Spring容器中完成bean实例化、配置以及其他初始化方法前后要添加一些自己逻辑处理。我们需要定义一个或多个BeanPostProcessor接口实现类,然后注册到Spring IoC容器中。
服务方
定义ResourceService继承IResourceService接口,用于处理具体的业务编码。
重点:类描述用@RPCService 注解标记,后面Spring框架要根据此标识扫描,并做统一管理
@Slf4j
@RPCService
@Service
public class ResourceService implements IResourceService {
/**
* 业务方法
*/
public ResourceDTO query() {
// 具体业务逻辑省略
return resourceDTO;
}
}
如何扫描@RPCService注解标识的服务实例呢?
@Slf4j
@Configuration
public class RpcServiceLoader {
private static Map<Class<?>, Object> providers = new ConcurrentHashMap<>();
public static Object getProviders(Class<?> clazz) {
return providers.get(clazz);
}
@Bean
@Autowired
RpcServiceFactory getProviderProxyFactory(ProviderConfig providerConfig, ApplicationContext ct) {
RpcServiceFactory rpcServiceFactory = new RpcServiceFactory();
// 扫描有RPCService注解的bean实例
Map<String, Object> map = ct.getBeansWithAnnotation(RPCService.class);
for (Object bean : map.values()) {
Class<?> interFaceClazz = AopUtils.getTargetClass(bean).getInterfaces()[0];
providers.put(interFaceClazz, bean);
}
return rpcServiceFactory;
}
}
服务提供方所有的RPC服务实例存储在Map<Class<?>, Object>,统一管理,后续查询服务时会用到
最后,关键一步,当服务方收到请求,如何完成触发调用?
public class RpcServiceFactory {
/***
* 作为RPC的服务提供方
* 接收消费方的请求信息,参数解析,通过反射机制,完成相关方法调用
* 返回结果给调用者(包含异常)
*/
public Object handleHttpContent(String reqStr) throws Throwable {
// 将消费方传递的参数反序列化,解析出对象
RPCRequest req = RPCSerializer.INSTANCE.requestParse(reqStr);
// 反射
Class<?> clazz = req.getClazz();
String methodName = req.getMethodName();
Object[] args = req.getArguments();
String[] parameterTypeNames = req.getParameterTypeNames();
String[] listParameterTypeNames = req.getListParameterTypeNames();
Class<?>[] parameterTypes = Arrays.stream(parameterTypeNames).map(this::classForName)
.toArray(Class[]::new);
Method method = clazz.getMethod(methodName, parameterTypes);
// 根据类模板查服务的Bean实例
Object bean = RpcServiceLoader.getProviders(clazz);
int argsListSize = 0;
if (null != args) {
argsListSize = args.length;
}
// 解析出方法的入参
Object[] argsList = new Object[argsListSize];
for (int i = 0; i < argsListSize; i++) {
Object o;
if (parameterTypeNames[i].contains("java.util.List")) {
//参数是list
String clazzName = listParameterTypeNames[i].replace("java.util.List<", "").replace(">", "");
//非list
Class<?> aClass = classForName(clazzName);
o = JSONObject.parseArray(JSONObject.toJSONString(args[i]), aClass);
} else {
//非list
Class<?> aClass = classForName(parameterTypeNames[i]);
o = JSONObject.parseObject(JSONObject.toJSONString(args[i]), aClass);
}
argsList[i] = o;
}
if (Void.TYPE.equals(method.getReturnType())) {
method.invoke(bean, argsList);
return Void.TYPE.getName();
}
Object result = method.invoke(bean, argsList);
return result;
}
public Object getBeanByClass(Class<?> clazz) throws RPCException {
if (bean != null) {
return bean;
}
}
public Class<?> classForName(String className) {
try {
return Class.forName(className);
} catch (ClassNotFoundException e) {
return null;
}
}
}
Redis cluster集群便是采用这个设计思路
Redis cluster有固定的16384个hash slot,对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slot。
集群中每个master都会持有部分slot,比如有3个master,那么可能每个master持有5000多个hash slot
如:100w条数据,5个master,每个master就负责存储20w条数据,分布式数据存储
此时会有同学问,如果集群扩容或缩容怎么办?
其实很简单,增加一个master,就将其他master的hash slot移动部分过去。减少一个master,就将它的hash slot移动到其他master上去
接下来要讲的部分跟今天的主题相关,或者说设计思路相似
Redis cluster 如何对多master写入?
写入数据的时候,其实是你可以将请求发送到任意一个master上去执行,该master会计算这个key对应的CRC16值,然后对16384个hash slot取模,找到key对应的hash slot,然后找到真实的master节点。
如果对应的master就在自己本地的话,如:set key1 value1,key1 对应的hash slot 就在自己本地,那么自己处理就可以了。
但是如果计算出来的hash slot在其他master节点上,则返回moved给客户端,由客户端进行重定向到对应的master上执行
好奇宝宝又要发问了?
基于重定向的客户端,大部分情况下,可能都会出现一次请求重定向,才能找到正确的节点,非常消耗网络IO。有什么解决方案吗?

可以了解下 JedisCluster
JedisCluster是针对Redis Cluster的java客户端,它封装了java访问redis集群的各种操作,包括初始化连接、请求重定向等。
原理细节:
在JedisCluster初始化的时候,随机选择一个node,初始化hash slot -> node映射表,同时为每个节点创建一个JedisPool连接池
每次基于JedisCluster执行操作,首先JedisCluster都会在本地计算key的hash slot,然后在本地映射表找到对应的节点
如果那个node正好还是持有那个hash slot,那么就ok; 如果说进行了reshard这样的操作,可能hash slot已经不在那个node上了,就会返回moved
如果JedisCluter API发现对应的节点返回moved,那么利用该节点的元数据,更新本地的hash slot -> node映射表缓存
重复上面几个步骤,直到找到对应的节点,如果重试超过5次,那么就报错,JedisClusterMaxRedirectionException
jedis老版本,可能会出现在集群某个节点故障还没完成自动切换恢复时,频繁更新hash slot,频繁ping节点检查活跃,导致大量网络IO开销
jedis最新版本,对于这些过度的hash slot更新和ping,都进行了优化,避免了类似问题
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。